Normalizing Flow
By LI Haoyang 2020.12.21 | 2020.12.30
Content
Normalizing FlowContentSupplementaryChange of Variables FormulaSylvester's determinant identityBanach Fixed Point theoremNormalizing Flows: An Introduction and Review of Current Methods - TPAMI 2020Generative ModelingNormalizing FlowFormal Construction of Normalizing FlowApplicationsDensity estimation and samplingVariational InferenceMethodsElementwise FlowsLinear FlowsPlanar and Radial FlowsPlanar FlowsSylvester FlowsRadial FlowsCoupling and Autoregressive FlowsCoupling FlowsAutoregressive FlowsResidual FlowsInfinitesimal (Continuous) FlowsDiscussion and Open ProblemsInductive biasesRole of the base measureForm of diffeomorphismsLoss functionGeneralisation to non-Euclidean spacesInspirations
Supplementary
Change of Variables Formula
Reference: http://stla.github.io/stlapblog/posts/ChangeOfVariables.html
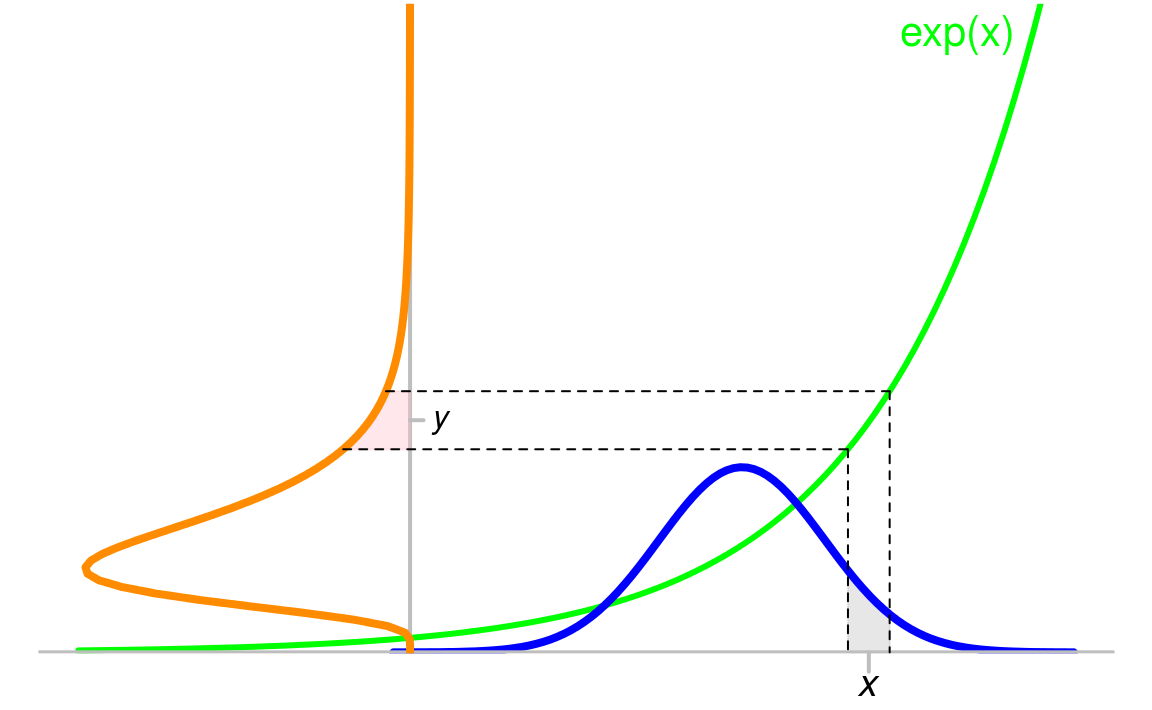
The change of variables formula refers to the calculation of the pdf of with a given pdf of .
Suppose that the pdf of is , and is an invertible function with the reverse as .
The probability that is drawn from should be equal to that of drawn from , i.e.
Therefore
Sylvester's determinant identity
Reference: https://math.stackexchange.com/questions/17831/sylvesters-determinant-identity
If and are matrices of sizes and , then there exists
A simple proof is as follows:
Banach Fixed Point theorem
Reference: https://mathworld.wolfram.com/BanachFixedPointTheorem.html
Let be a contraction mapping from a closed subset of a Banach space into . Then there exists a unique such that .
A function is said to be a contraction mapping if for some , there exists , i.e. the Lipschitz constant of this function is less than 1.
Normalizing Flows: An Introduction and Review of Current Methods - TPAMI 2020
Paper: https://ieeexplore.ieee.org/document/9089305
I. Kobyzev, S. Prince and M. Brubaker, "Normalizing Flows: An Introduction and Review of Current Methods," in IEEE Transactions on Pattern Analysis and Machine Intelligence, doi: 10.1109/TPAMI.2020.2992934.
Normalizing Flows are generative models which produce tractable distributions where both sampling and density evaluation can be efficient and exact.
Generative Modeling
Generative modeling aims to model a probability distribution given examples from that distribution.
There are mainly two approaches:
Direct analytic approaches approximate observed data with a fixed family of distributions.
The traditional way, fit observations with priors.
Variational approaches and expectation maximization introduce latent variables to explain the observed data.
Normalizing Flows (NF) are a family of generative models with tractable distributions where both sampling and density evaluation can be efficient and exact.
Normalizing Flow
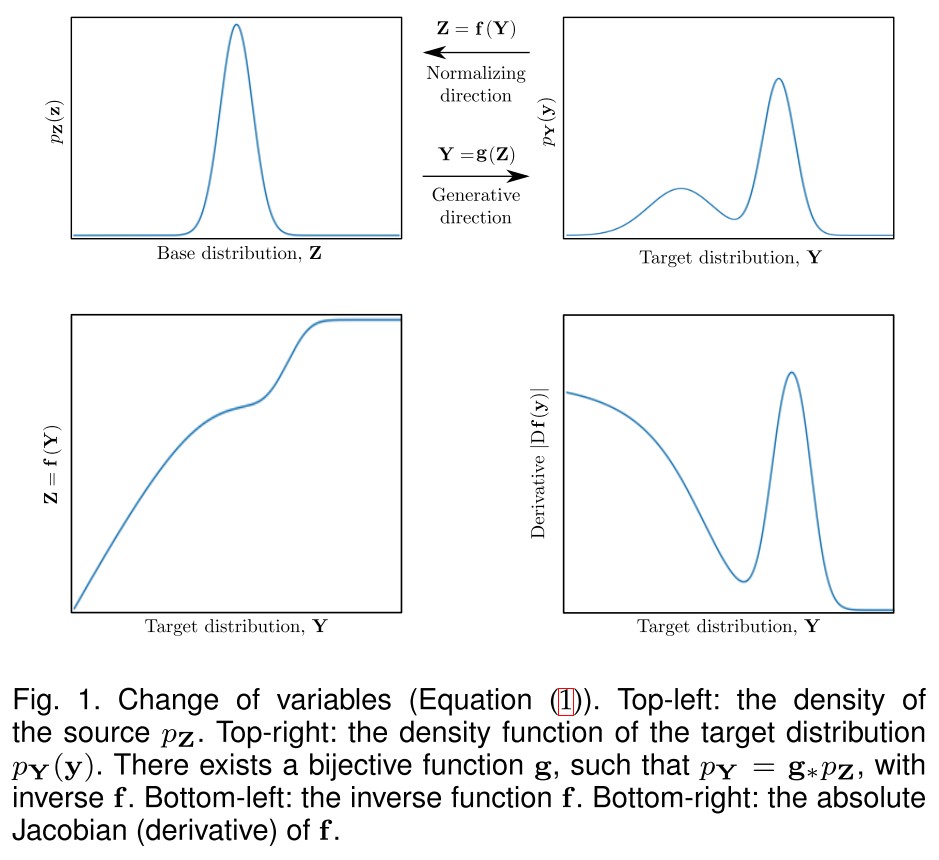
A Normalizing Flow is a transformation of a simple probability distribution (e.g., a standard normal) into a more complex distribution by a sequence of invertible and differentiable mappings.
Let be a random variable with a known and tractable probability density function .
Let be an invertible function, and .
Then, using the change of variables formula, one can compute the probability density function of the random variable :
in which:
- is the Jacobian of
- is the Jacobian of
This new density function is called a pushforward of the density by the function and denoted by .
- Generative direction: maps a simple distribution into a more complex distribution
- Normalizing direction: maps a complex distribution back to a simple (normal) distribution
Constructing arbitrarily complicated non-linear invertible functions (bijections) can be difficult.
Let be a set of bijective functions and define to be the composition of these functions.
Then is also bijective, with the inverse:
and the determinant of the Jacobian as:
where is the Jacobian of .
The value of the -th intermediate flow is denoted as
hence .
Thus, a set of nonlinear bijective functions can be composed to construct successively more complicated functions.
Basically, the idea of normalizing flow is to chain a series of bijective mapping constructed using neural networks to map the given samples to a normal distribution, then the reverse can serve as a sampling function.
Formal Construction of Normalizing Flow
Definition 1. If , are measurable spaces, is a measurable mapping between them, and is a measure on , then one can define a measure on , called the pushforward measure and denoted by , by the formula
The data we want to learn can be understood as a sample from a measured "data" space .
To learn the data, one can introduce a simpler measured space and find a function such that .
This function can be interpreted as a "generator", and as a latent space.
In this survey we will assume that , all sigma-algebras are Borel, and all measures are absolutely continuous with respect to Lebesgue measure (i.e., ).
Definition 2. A function is called a diffeomorphism, if it is bijective, differentiable, and its inverse is differentiable as well.
The pushforward of an absolutely continuous measure by a diffeomorphism is also absolutely continuous.
Thus the theoretical foundation of normalizing flow.
Remark 3. It is common in the normalizing flows literature to simply refer to diffeomorphisms as “bijections” even though this is formally incorrect. In general, it is not necessary that is everywhere differentiable; rather it is sufficient that it is differentiable only almost everywhere with respect to the Lebesgue measure on . This allows, for instance, piecewise differentiable functions to be used in the construction of .
Applications
Density estimation and sampling
Assume that there is only a single flow parametrized by , and the base measure is given and parametrized by the vector .
Given a set of data observed from some complicated distribution, , we can then perform likelihood-based estimation of the parameters .
The data likelihood becomes
in which
- The first term is the log likelihood of the sample under the base measure.
- The second term (the log-determinant/volume correction) accounts for the change of volume induced by the transformation of the normalizing flows.
The log changes the multiplication into addition.
During training, the parameters of the flow () and of the base distribution () are adjusted to maximize the log-likelihood.
Even though a flow must be theoretically invertible, computation of the inverse may be difficult in practice; hence, for density estimation it is common to model a flow in the normalizing direction.
Variational Inference
Consider a latent variable model , where is an observed variable and is the latent variable.
The posterior distribution is usually intractable in practice, therefore the estimation of parameters is done with the approximate posterior , i.e. minimizing the KL divergence
which is equivalent to maximizing the evidence lower bound
The latter can be optimized using gradient descent, which requires the computation of the gradient .
One can reparametrize
with normalizing flows. Assume for a single flow parametrized by , and the base distribution does not depend on , then
and the gradient of the right hand side with respect to can be computed.
This approach generally to computing gradients of an expectation is often called the "reparameterization trick"
What is this ?
Methods
Normalizing flows should satisfy several conditions to be practical:
- Invertible; for sampling we need while for computing likelihood we need .
- Sufficiently expressive to model the distribution of interest.
- Computationally efficient, both in terms of computing and , but in terms of the calculation of the determinant of the Jacobian.
Elementwise Flows
A basic form of bijective non-linearity can be constructed given any bijective scalar function.
Let be a scalar valued bijection.
If , then
is also a bijection.
In deep learning terminology, , could be viewed as an "activation function"
Linear Flows
Linear mappings can express correlation between dimensions.
where and are parameters. This function is invertible if is an invertible matrix.
The expressiveness of linear flows is limited. The determinant of the Jacobian is , which can be computed in . For computational efficiency, we can restrict the form of .
Diagonal
If is diagonal with nonzero diagonal entries, then its inverse can be computed in linear time and its determinant is the product of the diagonal entries.
But the diagonal matrix yields an elementwise transformation, which cannot express correlation between dimensions.
Triangular
The determinant of a triangular matrix is the product of its diagonal, which is much more efficient.
Inversion is relatively inexpensive requiring a single pass of back-substitution costing operations.
Permutation and Orthogonal
The expressiveness of triangular transformations is sensitive to the ordering of dimensions. Reordering the dimensions can be done easily using a permutation matrix which has an absolute determinant of 1.
The inverse and absolute determinant of an orthogonal matrix are both trivial to compute, which is efficient.
Factorizations
Kingma and Dhariwal [2018] proposed using the LU factorization:
where is lower triangular with ones on the diagonal, is upper triangular with non-zero diagonal entries, and is a permutation matrix.
The determinant is the product of the diagonal entries of U which can be computed in .
The inverse of the function g can be computed using two passes of backward substitution in .
But the discrete permutation cannot be easily optimized.
Convolution
Convolutions are easy to compute but their inverse and determinant are non-obvious.
Zheng et al. [2018] used 1D convolutions (ConvFlow) and exploited the triangular structure of the resulting transform to efficiently compute the determinant.
Hoogeboom et al. [2019a] have provided a more general solution for modelling d×d convolutions, either by stacking together masked autoregressive convolutions (referred to as Emerging Convolutions) or by exploiting the Fourier domain representation of convolution to efficiently compute inverses and determinants (referred to as Periodic Convolutions).
Planar and Radial Flows
Rezende and Mohamed [2015] introduced planar and radial flows. They are relatively simple, but their inverses aren’t easily computed.
Planar Flows
Planar flows expand and contract the distribution along certain specific directions and take the following form:
where and are parameters and is a smooth non-linearity.
The Jacobian determinant for this transformation is
which can be computed in time.
The inversion of this flow isn’t possible in closed form and may not exist for certain choices of and certain parameter settings.
The term can be interpreted as a multilayer perceptron with a bottleneck hidden layer with a single unit [Kingma et al., 2016].
Sylvester Flows
This kind of flows replaces the scaling parameters in planar flows with matrices:
where , and is an elementwise smooth nonlinearity, where is a hyperparameter to choose, which can be interpreted as the dimension of a hidden layer.
The Jacobian determinant is
where the last equality is Sylvester's determinant identity.
This can be computationally efficient if is small.
In a neural network perspective, this is a special residual block.
Radial Flows
Radial flows instead modify the distribution around a specific point so that
where is the point around which the distribution is distorted, and are parameters, .
The inverse of radial flows cannot be given in closed form but does exist under suitable constraints on the parameters.
Coupling and Autoregressive Flows
Coupling Flows
Dinh et al. [2015] introduced a coupling method to enable highly expressive transformations for flows.
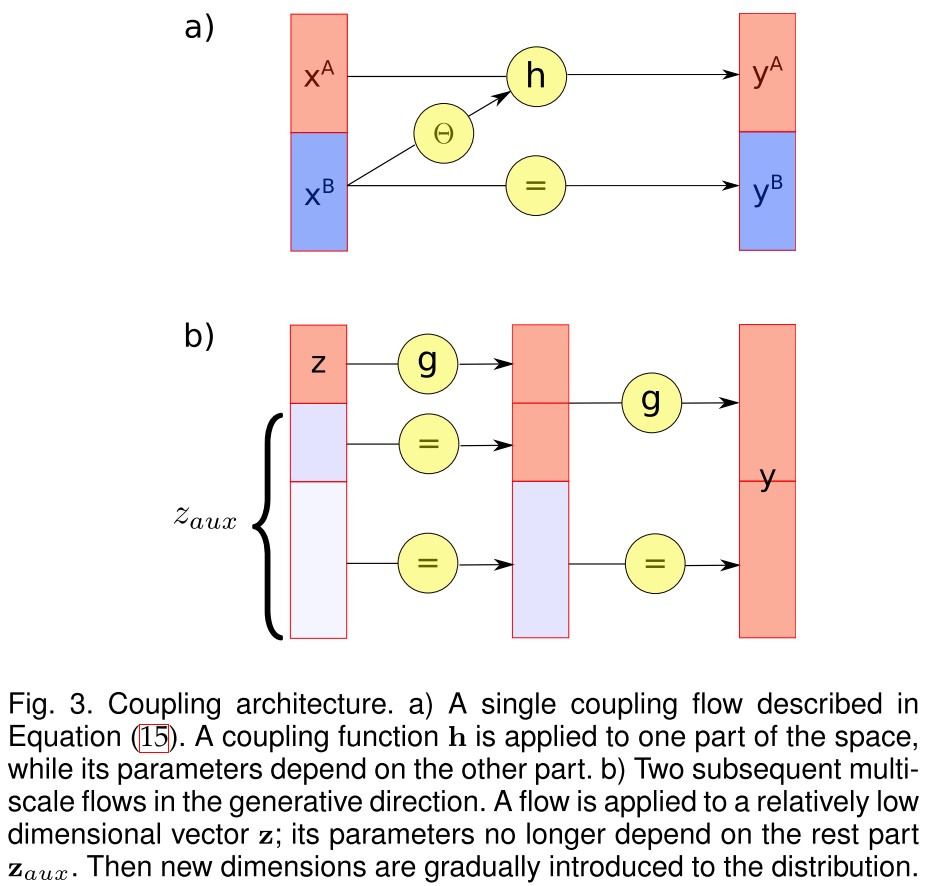
Consider a disjoint partition of the input into two subspaces: and a bijection , parametrized by .
Then one can define a function by the formula:
where the parameters are defined by any arbitrary function which only uses as input. It's called a conditioner.
The bijection is called a coupling function, and the resulting function is called a coupling flow.
As shown in Figure 3 (a), a coupling flow is invertible if and only if is invertible and has inverse:
Since the bijection is controlled by , therefore one can completely reverse with the parameters computed from .
The Jacobian of is a block triangular matrix where the diagonal blocks are and the identity matrix respectively.
Most coupling functions are applied to element-wise:
where each is a scalar bijection.
The power of a coupling flow resides in the ability of a conditioner to be arbitrarily complex. In practice it is usually modelled as a neural network.
As shown in Figure 3 (b), with constant conditioner, one can construct a multi-scale flow, which gradually introduces dimensions to the distribution in the generative direction.
In the normalizing direction, the dimension reduces by half after each iteration step, such that most of semantic information is retained.
For the partition of :
This is often done by splitting the dimensions in half [Dinh et al., 2015], potentially after a random permutation.
Autoregressive Flows
Kingma et al. [2016] used autoregressive models as a form of normalizing flow. These are non-linear generalizations of multiplication by a triangular matrix (Section 3.2.2).
Let be a bijection parametrized by .
An autoregressive model is a function , which ouputs each entry of conditioned on the previous entries of the input:
where .
Each part of is conditioned on the previous parts.
For , we choose arbitrary functions mapping to the set of all parameters, and is a constant. The functions are called conditioners.
The Jacobian matrix of the autoregressive transformation is triangular. Each output only depends on , and so the determinant is just a product of its diagonal entries:
In practice, it’s possible to efficiently compute all the entries of the direct flow.
The computation of the inverse is inherently sequential which makes it difficult to implement efficiently on modern hardware as it cannot be parallelized.
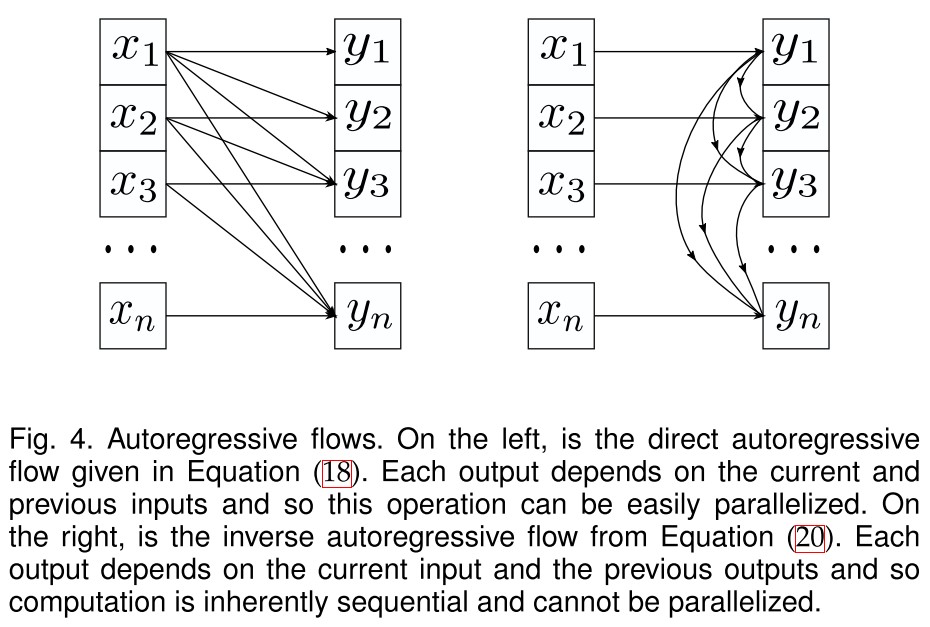
Alternatively, the inverse autoregressive flow (IAF) outputs each entry of conditioned the previous entries of , i.e.
which is the same form with autoregressive flow, but the inverse of IAF can be computed relatively efficiently as shown in Figure 4.
Typically, papers model flows in the normalizing direction, i.e. from data to the base density, while IAF is a flow in generative direction.
For fast sampling, IAF is better; for fast density estimation, MAF is better.
For several autoregressive flows the universality property has been proven [Huang et al., 2018; Jaini et al., 2019a].
Informally, universality means that the flow can learn any target density to any required precision given sufficient capacity and data.
Residual Flows
Residual networks are compositions of the function of the form:
Such a function is called a residual connection, and here the residual block is a feed-forward neural network of any kind.
The first attempts to build a reversible network architecture based on residual connections were made in RevNets [Gomez et al., 2017] and iRevNets [Jacobsen et al., 2018].
Consider a disjoint partiton of denoted by for the input and for the output, and define a function:
where and are residual blocks. This network is invertible but computation of the Jacobian is inefficient.
A different point of view on reversible networks comes from a dynamical systems perspective via the observation that a residual connection is a discretization of a first order ordinary differential equation.
To make the residual connection invertible, a sufficient condition is found that
Propostion 7. A residual connection is invertible, if the Lipschitz constant of the residual block is .
There is no analytically closed form for the inverse, but it can be found numerically using fixed-point iterations (which, by the Banach theorem, converge if we assume Lip(F) < 1).
The specific architecture proposed by Behrmann et al. [2019], called iResNet, uses a convolutional network for the residual block. It constrains the spectral radius of each convolutional layer in this network to be less than one.
Infinitesimal (Continuous) Flows
The residual connection can be viewed as discretizations of a first order ordinary differential equation (ODE):
where is a function which determines the dynamic (the evolution function), is a set of parameters and is a parametrization.
The discretization of this quation (Euler's method) is
which is equivalent to a residual connection with a residual block .
This similarity is marvelous.
The rest of this part is a little out of my understanding... for now.
Discussion and Open Problems
Inductive biases
No more than prior, structure and loss function.
Role of the base measure
The base measure of a normalizing flow is generally assumed to be a simple distribution (e.g., uniform or Gaussian).
Theoretically the base measure shouldn’t matter: any distribution for which a CDF can be computed, can be simulated by applying the inverse CDF to draw from the uniform distribution.
However in practice if structure is provided in the base measure, the resulting transformations may become easier to learn.
Form of diffeomorphisms
The majority of the flows explored are triangular flows (either coupling or autoregressive architectures).
A natural question to ask is: are there other ways to model diffeomorphisms which are efficient for computation? What inductive bias does the architecture impose?
Loss function
The majority of the existing flows are trained by minimization of KL-divergence between source and the target distributions (or, equivalently, with log-likelihood maximization).
However, other losses could be used which would put normalizing flows in a broader context of optimal transport theory.
Generalisation to non-Euclidean spaces
This part is out of my mathematical level.... for now.
Inspirations
The core idea of a flow is to model distribution without information loss by insuring that the model is invertible.
Most flows are designed to be invertible, but it can also be converted from a general neural networks. The following two kinds of flows are particularly interesting to me:
Coupling flows
It sustains the invertibility by keeping part of information unchanged.
Invertible Residual Network
It insures the invertibility as long as the residual block has a Lipschitz constant smaller than 1.