Invertible Residual Networks
By LI Haoyang 2020.12.1
Content
Invertible Residual NetworksContentInvertible Residual Networks - ICML 2019Enforcing invertibility in ResNetsSatisfying the Lipschitz constraintNormalizing flow with i-ResNetsApproximation of log-determinantAlgorithmExperimentsInvertible classificationGenerative modelingInspirations
Invertible Residual Networks - ICML 2019
Code: https://github.com/jhjacobsen/invertible-resnet
Jens Behrmann, Will Grathwohl, Ricky T. Q. Chen, David Duvenaud, Jörn-Henrik Jacobsen. Invertible Residual Networks. ICML 2019. arXiv:1811.00995
We show that standard ResNet architectures can be made invertible, allowing the same model to be used for classification, density estimation, and generation.
In contrast, our approach only requires adding a simple normalization step during training, already available in standard frameworks.
They make the standard ResNet invertible by adding a simple normalization step during training.
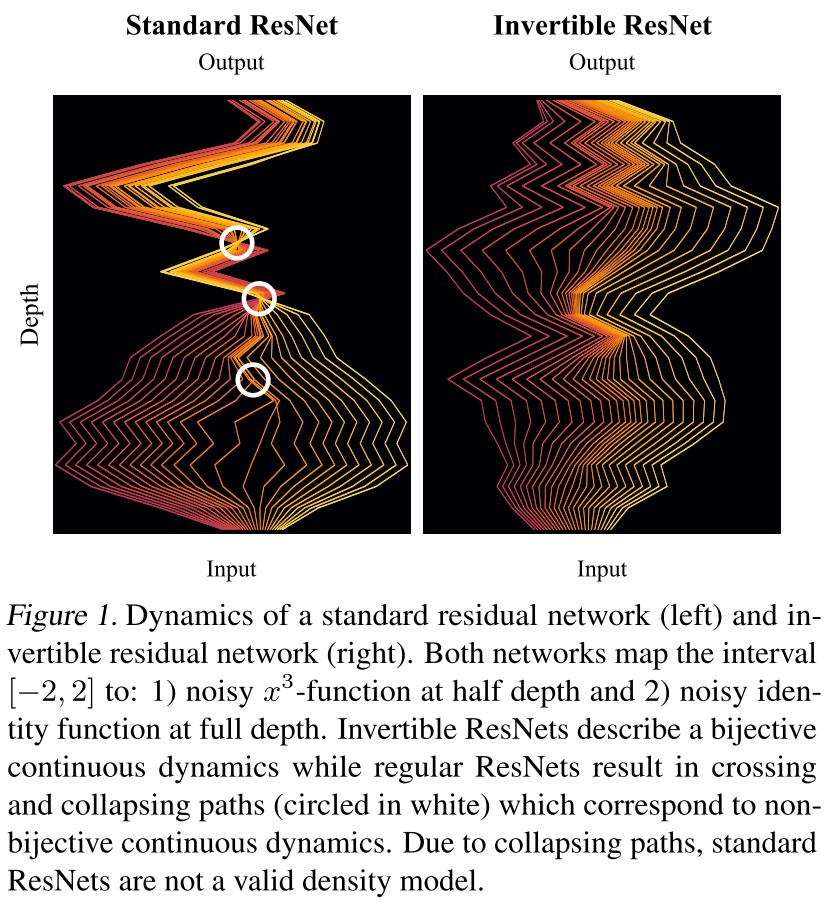
This approach allows unconstrained architectures for each residual block, while only requiring a Lipschitz constant smaller than one for each block.
Enforcing invertibility in ResNets
The architectures of ResNet are very similar to Euler's method for ODE initial value problems:
where:
- represents activations or states
- represents layer indices or time
- is a step size
- is a residual block
This connection has attracted research at the intersection of deep learning and dynamical systems.
Reversely, solving the dynamics backwards in time would implement an inverse of the corresponding ResNet, i.e.
Theorem 1 (Sufficient condition for invertible ResNet). Let with denote a ResNet with blocks . The ResNet is invertible if
where is the Lipschitz-constant of .
Why?

The inverse of ResNet block can be obtained through a simple fixed-point iteration, as shown in Algorithm 1.
From the Banach fixed-point theorem, there is
the convergence rate is exponential in the number of iterations if using the output as the initial point, and a smaller Lipschitz constants will yield faster convergence.
If , then , and .
A contractive residual block also renders the residual layer bi-Lipschitz.
Lemma 2 (Lipschitz constants of Forward and Inverse). Let with denote the residual layer. Then it holds
Hence by design, invertible ResNets offer stability guarantees for both their forward and inverse mapping.
As long as each block has a Lipschitz constant smaller than one, it's possible to use simple iterations to find the inverse.
Satisfying the Lipschitz constraint
They implement residual blocks as a composition of contractive nonlinearities (e.g. ReLU, ELU, tanh) and linear mappings.
For a network with three convolutional layers, i.e.
There is
where denotes the spectral norm.
They directly estimate the spectral norm of by performing power-iteration using and , yielding an under-estimate , using which they normalize the weight via
where is a scaling coefficient.
They show that holds in all cases, since is not guaranteed with the under-estimate .
Normalizing flow with i-ResNets
For data , we can define a simple generative model by first sampling where and then defining with some function .
First map an artificial distribution into data distribution.
If is invertible, define , we can compute the likelihood of any under this model using the change of variables formula:
where is the Jacobian of evaluated at .
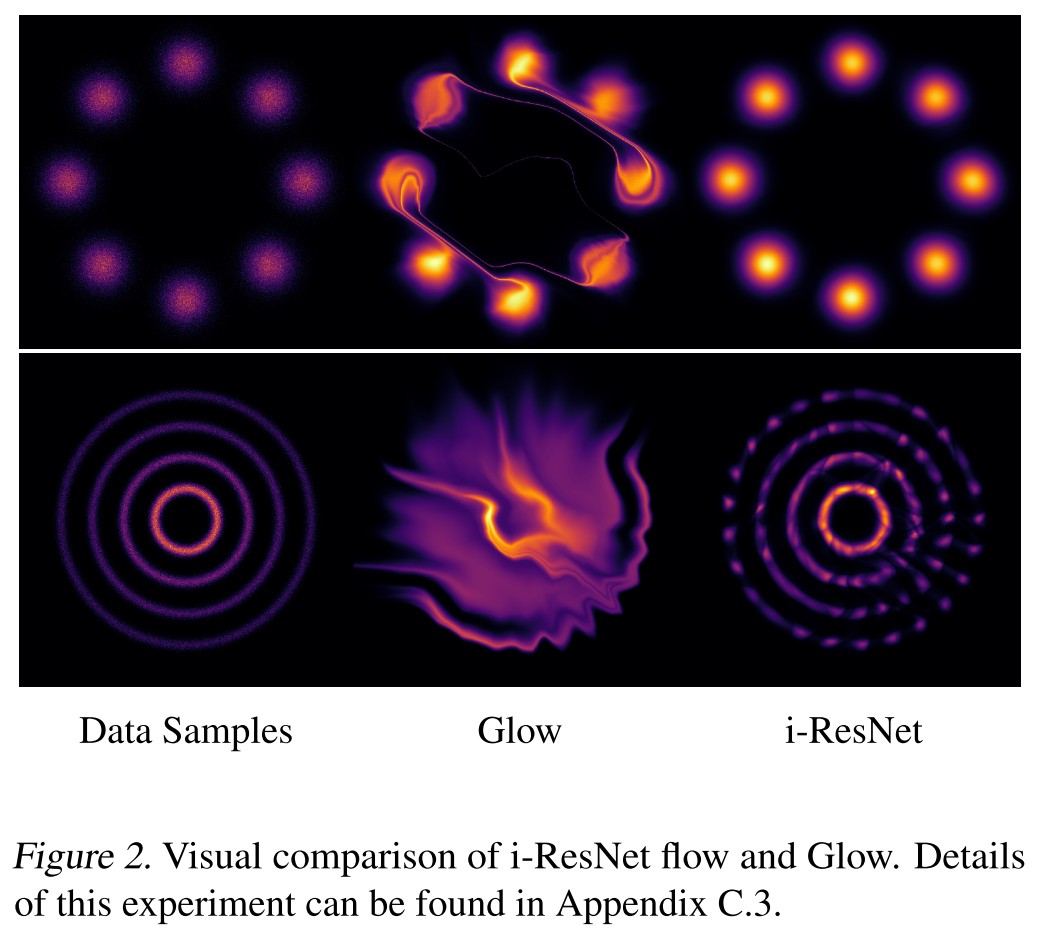
As shown in Figure 2, using i-ResNet is better than Glow.
Approximation of log-determinant
Computing naively has a time complexity of , in order to scale to higher dimensions, they propose to approximate it.
The Lipschitz constrained perturbations of the identity yield positive determinants, i.e.
and for non-singular matrix , there exists
Combining them, there is
Thus for , it becomes
The trace of matrix logarithm can be expressed by a power series
which converges if .
Hence, due to the Lipschitz constraint, we can compute the log-determinant via the above power series with guaranteed convergence.
Due to for the residual block of each layer , the log-determinant of gradient can be upper and lower bounded
Thus, both the number of layers T and the Lipschitz constant affect the contraction and expansion bounds of i-ResNets and must be taken into account when designing such an architecture
Algorithm

Using the power series to compute the log-determinant still has three main drawbacks:
- Computing exactly costs , or approximately needs evaluations of as each entry of the diagonal of the Jacobian requires the computation of a separate derivative of .
- Matrix powers are needed, requiring the knowledge of the full Jacobian.
- The series is infinite.
To overcome 1 and 2, they use vector-Jacobian products and the Hutchinsons trace estimator to estimate the trace of a matrix stochasticly, i.e.
where the distribution needs to fulfill and . (A normal distribution?)
To overcome 3, they truncate the series at index , i.e.
They give an error bound for this truncation.
Theorem 3 (Approximation error of Loss). Let denote the residual function and the Jacobian as before. Then, the error of a truncated power series at term is bounded as
Smaller Lipschitz constant, longer term and lower dimension yield a smaller error.
They also give a convergence analysis.
Theorem 4 (Convergence Rate of Gradient Approximation). Let denote the parameters of network , let be as before. Further, assume bounded inputs and a Lipschitz activation function with Lipschitz derivative. Then, we obtain the convergence rate
where and the number of terms used in the power series.
In practice, only 5-10 terms must be taken to obtain a bias less than .001 bits per dimension, which is typically reported up to .01 precision (See Appendix E).
Experiments
Invertible classification

Using Algorithm 1.
We invert each residual connection using 100 iterations (to ensure convergence).
We see that i-ResNets can be inverted using this method whereas with standard ResNets this is not guaranteed (Figure 7 top). Interestingly, on MNIST we find that standard ResNets are indeed invertible after training on MNIST (Figure 7 bottom).

Our proposed invertible ResNets perform competitively with the baselines in terms of classification performance.
In summary, we observe that invertibility without additional constraints is unlikely, but possible, whereas it is hard to predict if networks will have this property.
Generative modeling
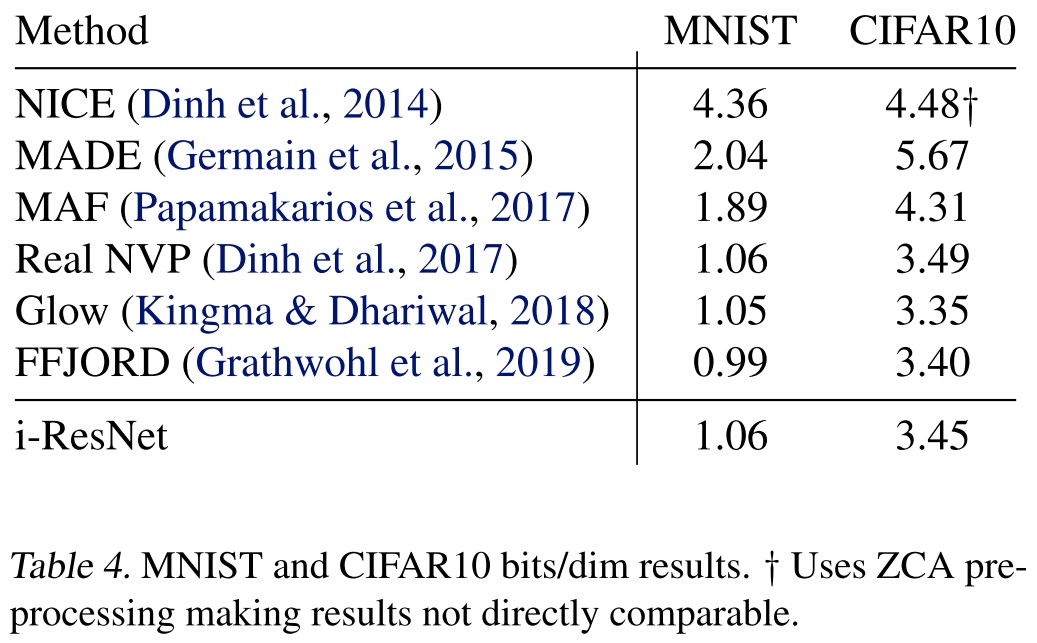

As shown in Table 4
While our models did not perform as well as Glow and FFJORD, we find it intriguing that ResNets, with very little modification, can create a generative model competitive with these highly engineered models.
Inspirations
It's just amazing that using such simple constraint can make a ResNet invertible.
Note that this network constrains the Lipschitz constant for each residual block to be smaller than one, which is similar to some technique in adversarial defense, and the ability to reconstruct images from features is also manifested in adversarially trained networks, I think there is some work that combines them.