Feature Purification : an Explanation for Adversarial Training
By LI Haoyang 2020.12.10
Content
Feature Purification : an Explanation for Adversarial TrainingContentFeature Purification: How Adversarial Training Performs Robust Deep Learning - 2020The Principle of Feature PurificationWhy clean training learns non-robust features? Which part of the features are “purified” during adversarial training?Computational ComplexityPreliminariesNotationsSparse coding modelClean and robust errorWarmup IntuitionsLinear learners are not robustHigh-complexity models are more robustLearning robust classifier using neural networkLearner Network and Adversarial TrainingClean TrainingAdversarial TrainingMain ResultsClean TrainingFeature PurificationAdversarial TrainingL∞ Robustness and Lower Bound for Low-Complexity ModelsOverview of the Training ProcessLottery ticket winningDense mixtureMore experiments resultsInspirations
Feature Purification: How Adversarial Training Performs Robust Deep Learning - 2020
Zeyuan Allen-Zhu, Yuanzhi Li. Feature Purification: How Adversarial Training Performs Robust Deep Learning. arXiv preprint 2020. arXiv:2005.10190
In this paper, we present a principle that we call feature purification, where we show one of the causes of the existence of adversarial examples is the accumulation of certain small dense mixtures in the hidden weights during the training process of a neural network; and more importantly, one of the goals of adversarial training is to remove such mixtures to purify hidden weights.
They study the learning process of adversarial training and propose the idea of feature purification as a principle of robust deep learning, i.e. trying to answer the following questions:
Why do adversarial examples exist when we train the neural networks using the original training data set? How can adversarial training further “robustify” the trained neural networks against these adversarial attacks?
For a simplified standard model, they prove that:
- Training over the original data is indeed non-robust to small adversarial perturbations of some radius.
- Adversarial training, even with an empirical perturbation algorithm such as FGM, can in fact be provably robust against any perturbations of the same radius.
They also give a complexity lower bound, showing that a model under this complexity bound cannot yield robustness regardless of training algorithms.
A similar idea like feature purification was actually adopted as a defense itself several years ago by PixelDefend, which was later breached and classified as one of gradient masking methods.
This paper seems to indicate that adversarial training also utilizes feature purification, but in a better way.
The Principle of Feature Purification

The Principle of Feature Purification During adversarial training, the neural network will neither learn new, robust features nor remove existing, non-robust features learned over the original data set. Most of the works of adversarial training is done by purifying a small part of each learned feature after clean training.
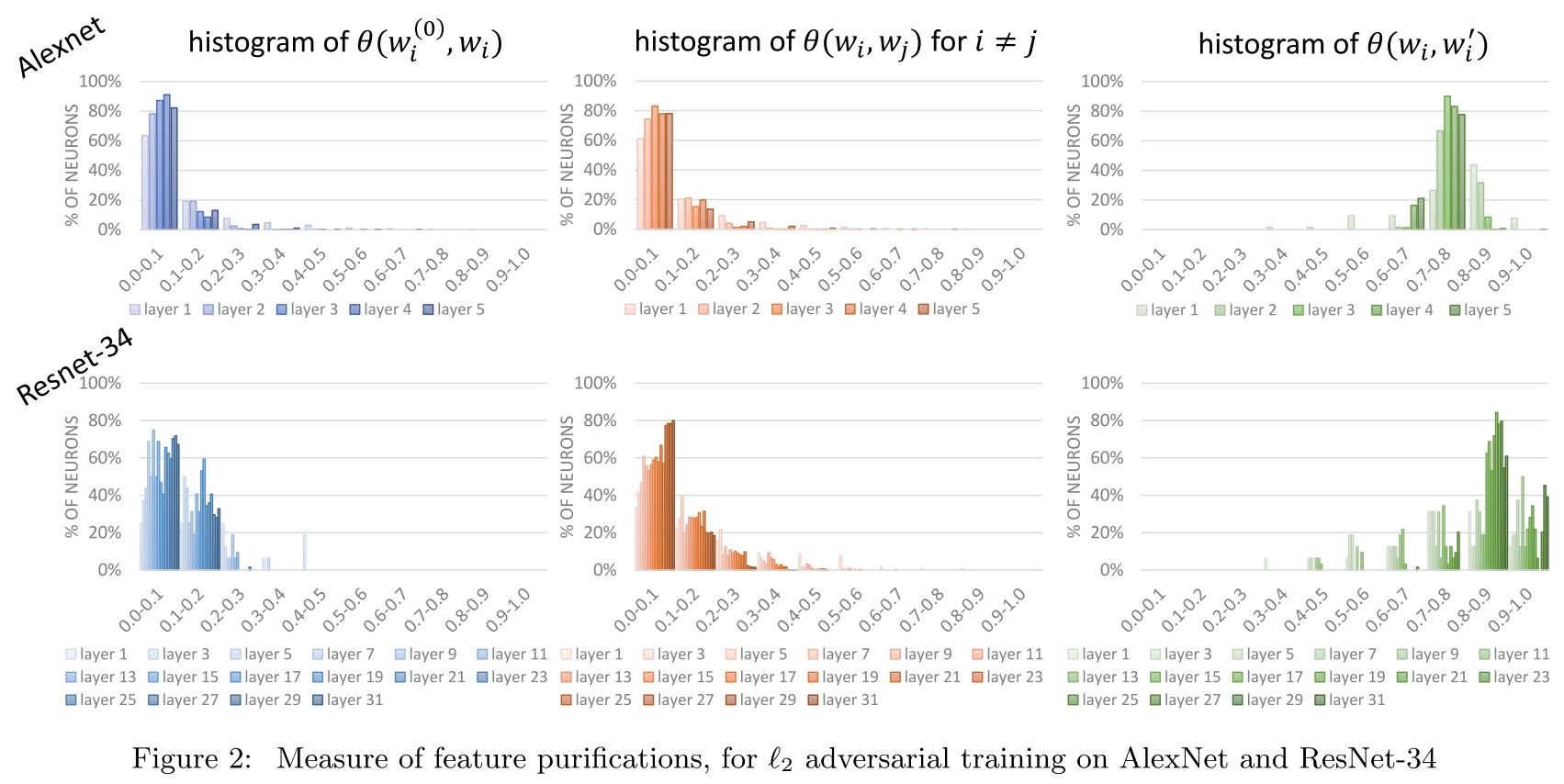
Using the following notations:
- , the weight vector of the -th neuron at initialization.
- , the weight vector after clean training.
- , the weight vector after adversarial training using as initialization.
And the following provisional measure of correlation between "features":
i.e. the absolute value of cosine similarity.
They have the following claims:
- For most neurons: for a small constant (such as 0.2).
- For most neurons: for a large constant (such as 0.8).
- For most pairs of different neurons: for a small constant (such as 0.2).
A small cosine similarity implies a large difference.
As a result, this principle implies that both clean training and adversarial training discover hidden weights fundamentally different from the prescribed initialization .
They propose that clean training already discover a big portion of the robust features while adversarial training further purifies them.
Well, two weights both differ from initialization and they are relatively similar, so it indicates that adversarial training purifies the weights....It's a little shaky.
Why clean training learns non-robust features? Which part of the features are “purified” during adversarial training?
As we shall formally discuss in Section 6.2, training algorithms such as gradient descent will, at every step, add to the current parameters a direction that maximally correlates with the labeling function on average.
They refer this part of weight that correlates with the average of training data as dense mixture. Since under natural assumptions of the data such as the sparse coding model, i.e. inputs come from sparse combinations of hidden dictionary words/vectors, such dense mixtures cannot have any high correlation with any individual, clean example, thus the network can still generalize well on the original dataset.
However, we show that these portions of the features are extremely vulnerable to small, adversarial perturbations along the “dense mixture” directions. As a result, one of the main goals of adversarial training, as we show, is to purify the neurons by removing such dense mixtures.
Moreover, in our setting, these dense mixtures in the hidden weights of the network come from the sparse coding structure of the data and the gradient descent algorithm.
They state that the cleanly trained model tends to learn an average of the training data, namely dense mixture which leads to the adversarial vulnerability.
Computational Complexity
We also prove a lower bound that, for the same sparse coding data model, even when the original data is linearly-separable, any linear classifier, any low-degree polynomial, or even the corresponding neural tangent kernel (NTK) of our studied two-layer neural network, cannot achieve meaningful robust accuracy (although they can easily achieve high clean accuracy).
The main intuition is that low complexity models, including the neural tangent kernel, lacks the power to zero out low magnitude signals to improve model robustness, as illustrated in Figure 3 and Section 3.
Preliminaries
Notations
- , or , the -norm of a vector
- , the -norm of a vector
- , the -th column of a matrix
- , the largest sum of columns of the matrix
- , the largest sum of rows of the matrix
- , the degree is some not-specified constant
- for and for
What is this ?
Sparse coding model
They consider the training data generated from
for a dictionary , where the hidden vector and is the noise.
They focus on and is a unitary matrix.
They assume the hidden vector is "sparse", i.e. for :
Assumption 2.1 (distribution of hidden vector ). The coordinates of are independent, symmetric random variables, such that . Moreover,
The first condition is a regularity condition, requiring that .
The second and third condition says that there is a non-trivial probability where attains the maximum value, and a (much) larger probability that is non-zero but has a small value.
???
Fact 2.2 Under Assumption 2.1, w.h.p., is a sparse vector.
They study the simplest binary classification problem, where the labelling function is linear over the hidden vector , i.e.
For simplicity, they assume , i.e. all the coordinates of have relatively equal contributions.
Clean and robust error
The goal of clean training is to learn a model so that is as close to as possible. The classification error on the original data set is defined as:
Consider the robust error against adversarial perturbations. For a value and a norm , the robust error of the model is defined as
Warmup Intuitions
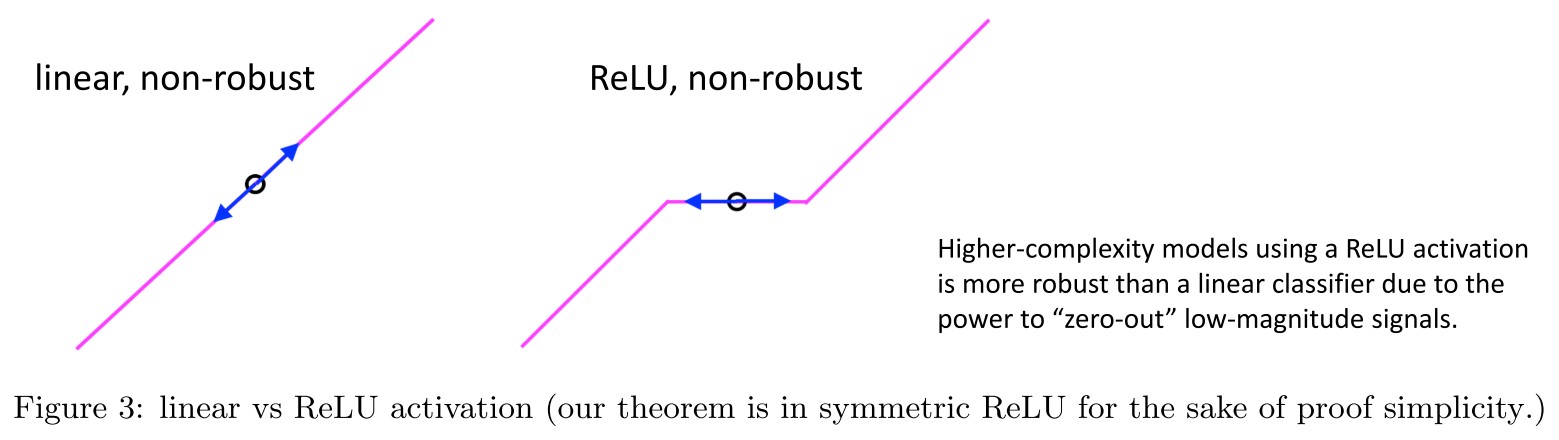
Linear learners are not robust
This is anti-intuitive......
A direct approach to classify the given dataset is to use a linear classifier as
and use the sign to predict label. They point out that there are two issues of this classifier:
When is as large as , such classifier cannot even classify in good accuracy, i.e.
while typically and by assumption. Thus when , the signal is overwhelmed by the noise.
Even when , i.e. the original data is perfectly linearly classifiable, linear classifier is also not robust to small perturbations, i.e.
one can design an adversarial perturbation for a large constant that can change the sign of the linear classifier for most inputs, given that .
Well, I think it's DeepFool, orthogonal perturbation to the decision boundary.
Since , this linear classifier is not even robust to adversarial perturbations of norm .
It's obtained by taking the norm into the form of perturbation.
I think the first claim is weird here, the first issue states that when the noise is comparable with signal, the classifier fails, which is not the problem of linearity as far as I can see. For data with many noise, a complicated classifier also fails.
High-complexity models are more robust
Another approach is to use a higher-complexity model:
Since , as long as the signal is non-zero, with high probability.
By Fact 2.2, w.h.p. the signal is -sparse, i.e. there are at most coordinates with the indicators to be 1, therefore this high complexity model has robust accuracy against any adversarial perturbation of radius .
How ???
Learning robust classifier using neural network

Their goal is to show that a two-layer neural networks can learn a robust function after adversarial training, such as
in which:
In this paper, we present a theorem stating that adversarial training of a (wlog. symmetric) two-layer neural network can indeed recover a neural network of this form.
In other words, after adversarial training, the features learned by the hidden layer of a neural network can indeed form a basis (namely, ) of the input where the coefficients are sparse.
It learns a set of basises ! Are they orthogonal ? If so, then it's connected back to Parseval Network and Lipschitz Regularization.
Learner Network and Adversarial Training
They consider a simple, two layer symmetric neural network with ReLU activation, i.e.
where , and
- , the hidden weight (feature) of the -th neuron
- , the negative bias
- is a smoothing of the original ReLU, also known as pre-activation noise; equivalently with .
They use to denote .
They fix throughout the training for simplicity.
They use to denote the hidden weights at time , and to denote the network at iteration , i.e.
Given a training set together with one sample of pre-activation noise for each , they define:
The first one is the standard logistic loss, the second one is the population risk and the third one is the empirical risk.
They consider a strong regularier:
and a fixed :
for simplicity.
Definition 4.1 In our case, the (clean, population) classification error at iteration is
We also introduce a notation (the logistic gradient)
and observe
What is this ???
Clean Training

Details seems redundant, so it's omitted.
Adversarial Training

Definition 4.2. An (adversarial) perturbation algorithm (a.k.a. attacker) maps the current network (which includes hidden weights , output weights , bias and smoothing parameter ), an input , a label , and some internal random string , to satisfying
for some norm. We say is an perturbation algorithm of radius if , and perturbation algorithm of radius if .
For simplicity, they assume satisfies for fixed , either , or is a -Lipschitz continuous function in .
The FGM attack satisfies the above properties, defined as
where is the dual norm of .
Definition 4.3. The robust error at iteration , against arbitrary perturbation of radius , is
In contrast, the empirical robust classification error against algorithm is
Main Results
Clean Training
Theorem 5.1 (clean training, sketched). There exists an absolute constants such that for every constant , every and with , given many training data, for every random initialization weight , for every learning rate , if we define , then for every , the following holds with high probability:
The network with hidden weights learned by clean training Algorithm 1 satisfies:
Global feature learning: for every ,
and
It states that weights are different from initialization and the differences among weights across layers are proportional to the scale of weight (?)
Clean training has good clean accuracy: for every ,
Clean training is not robust to small adversarial perturbations: for every , every , using perturbation (which does not depend on ),
Theorem 5.1 indicates that in our setting, clean training of the neural network has good clean accuracy but terrible robust accuracy. Such terrible robust accuracy is not due to over-fitting, as it holds even when a super-polynomially many iterations and infinitely many training examples are used to train the neural network
Theorem 5.2 (clean training features, sketched). For every neuron , there is a fixed subset of size , such that, for every ,
where:
for some small constant
for at least many neurons , it satisfies and . Moreover,
???
Theorem 5.2 says that each neuron will learn constantly many (allegedly large) components in the directions , and its components in the remaining directions are all small.
Theorem 5.2 shows that instead of learning the pure, robust features , intuitively, ignoring the small factors, focusing only on those neurons with , and assuming for simplicity all the 's are of similar (positive) magnitude, then, clean training will learn neurons:
It seems to say that in clean training the model learns the bias of the dataset. If so, then it explains for poor o.o.d. performance.
Feature Purification

One critical observation is that such dense mixture has low correlation with almost all inputs from the original distribution, so it has negligible effect for clean accuracy.
However, such dense mixture is extremely vulnerable to small but dense adversarial perturbations of the input along this direction , making the model non-robust.
As shown in Figure 5:
As we point out, such “dense adversarial perturbation” directions do not exist in the original data. Thus, one has to rely on adversarial training to remove dense mixtures to make the model robust.
They also state the source of dense mixture:
At a high level, in each iteration, the gradient will bias towards the direction that correlates with the labeling function ; and since in our model, such directions should be , so it a dense mixture direction and will be accumulated across time.
It seems to indicate that labeling function misguides the learning algorithm to learn the dense mixture.
Adversarial Training

Theorem 5.3 (adversarial training, sketched). In the same setting as Theorem 5.1, suppose is an perturbation algorithm with radius . Suppose we run clean training Algorithm 1 for iterations followed with adversarial training Algorithm 2 for iterations.
The following holds with high probability:
Empirical robust accuracy: for
Provable robust accuracy: when is the fast gradient method (FGM), for
Feature (local) purification: for every ,
???
More surprisingly, Theorem 5.3b says when a good perturbation algorithm such as FGM is used, then not only the robustness generalizes to unseen examples, it also generalizes to any worst-case perturbation algorithm.
As shown in Figure 6:
Our theorem shows one of the main goals of adversarial training is to remove dense mixtures to make the network more robust. Therefore, before adversarial training, the adversarial perturbations are dense in the basis of ; and after adversarial training, the adversarial perturbations ought to be more sparse and aligned with inputs from the original data set.
It says that adversarial training does not eliminate the adversarial perturbations, instead, it spreads the adversarial perturbations, making the perturbations semantically meaningful, violating the imperceptibility.
L∞ Robustness and Lower Bound for Low-Complexity Models
Theorem 5.4 ( adversarial training, sketched). Suppose . There exists constant , such that, in the same setting as Theorem 5.3, except now for any , and is an -perturbation algorithm with radius . Then, the same Theorem 5.3 and Theorem 5.1 still hold and imply:
- clean training is not robust against -perturbation with radius .
- adversarial training is robust against any -perturbation of radius
This gives a gap because can be made arbitrarily small.
???
Definition 5.5 The feature mapping of the neural tangent kernel for out two-layer network is
Therefore, given weights , the NTK (neural tangent kernel) function is given as
Without loss of generality, assume each .
???
They prove the following:
Theorem 5.6 (lower bound). For every constant , suppose , then there is a constant such that when , considering -perturbation with radius , we have w.h.p. over the choice of , for every in the above definition, the robust error
And the following corollary:
Corollary 5.7 (lower bound). In the same setting as Theorem 5.6, if is a constant degree polynomial, then we have the robust error .
I cannot get any sense.....
Overview of the Training Process
Lottery ticket winning
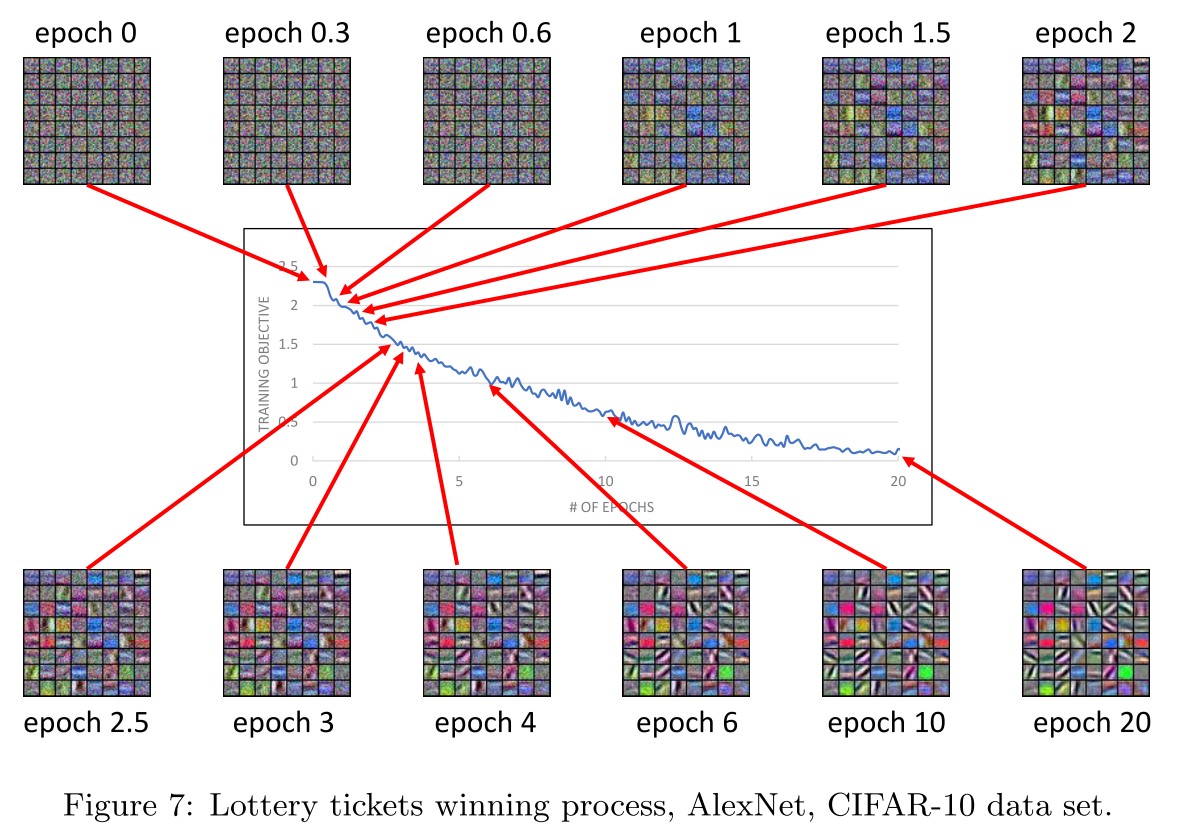
In other words, even with very mild over-parameterization ,by the property of random Gaussian initialization, there will be some “potentially lucky neurons” in (ii), where the maximum correlation to one of the features is slightly higher than usual
Lottery tickets winning process For every , at every iteration , if , then will grow faster than for every , until becomes sufficiently larger than all the other .
In other words, if neuron wins the lottery ticket at random initialization, then eventually, it will deviate from random initialization and grow to a feature that is more close to (a scaling of) .
Some neurons will be lucky to resemble the feature mostly at begining and grows into the feature responsible neuron.
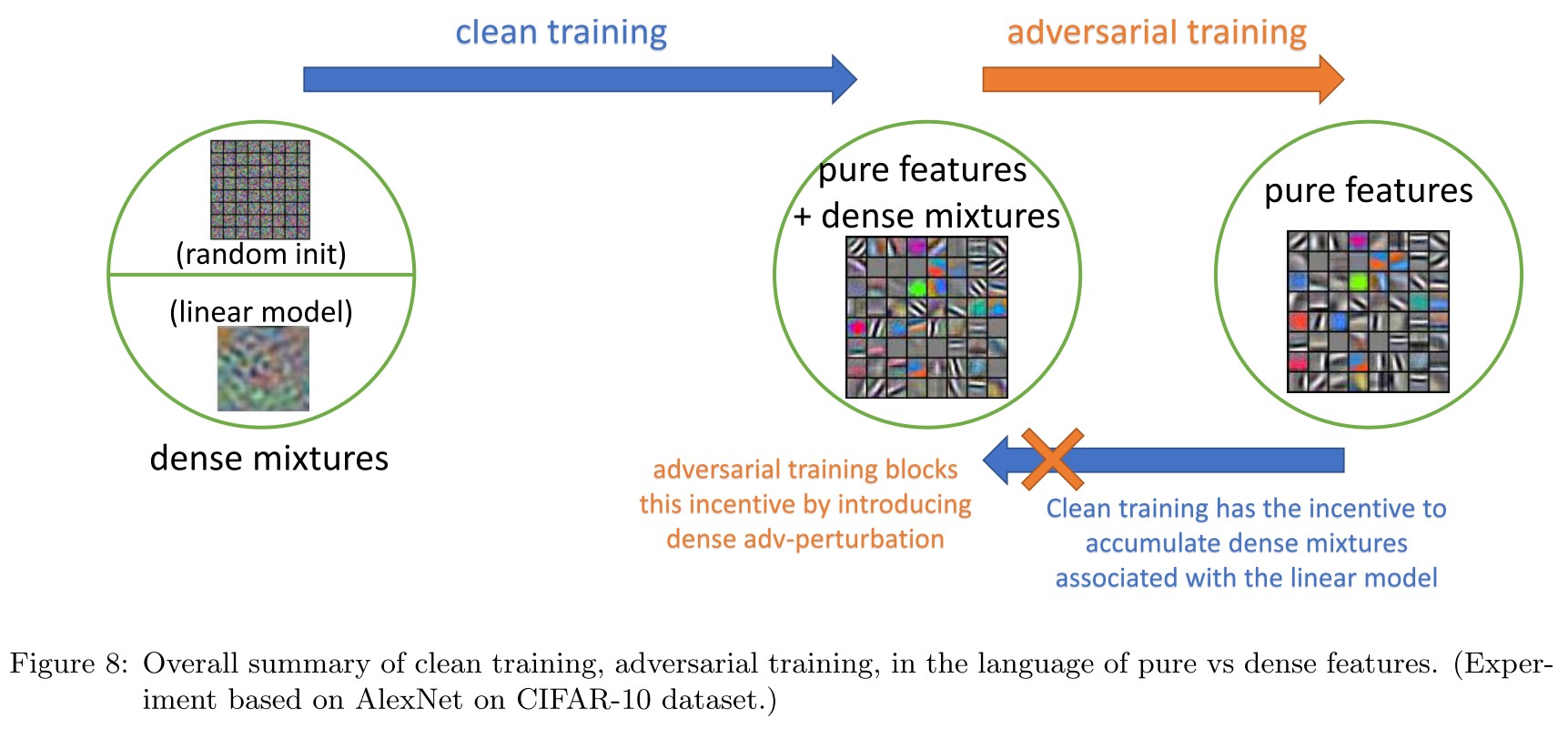
Dense mixture
We shall prove that in this phase, gradient descent will also accumulate, in each neuron, a small “dense mixture” that is extremely vulnerable to small but adversarial perturbations.
If a neuron i wins the lottery ticket for feature near random initialization, then it will keep this “lottery ticket” throughout the training.
But they show that that even for the “lucky neuron” that wins the lottery ticket, the hidden weight of this neuron will look like:
i.e. the weight will be like , where is a "dense mixture":
Their key observation is that is small and dense, i.e. with high probability:
This dense mixture will not be correlated with any particular natural input, and thus the existence of these mixtures will have negligible contribution to the output of ft on clean data.
But it's possible to create a correlated perturbation along the dense direction , i.e.
Thus, at this phase, even when the network has a good clean accuracy, it is still non-robust to these small yet dense adversarial perturbations.
Moreover, this perturbation direction is “universal”, in the sense that it does not depend on the randomness of the model at initialization, or the randomness we use during the training. This explains transfer attacks in practice: that is, the adversarial perturbation found in one model can also attack other models that are independently trained.
Since Eq. (6.2) suggests most original inputs have negligible correlations with each dense mixture, during clean training, gradient descent will have no incentive to remove those mixtures.
They point out that it's a property of gradient descent:
We emphasize that this is indeed a special property of gradient descent.
(Stochastic) gradient descent, as a local update algorithm, only exams the local correlation between the update direction and the labeling function, and it does not exam whether this direction can be used in the final result.
In fact, even if we use as initialization as opposed to random initialization, continuing clean training will still accumulate these small but dense mixtures.
Local learning accumulates noise?
More experiments results
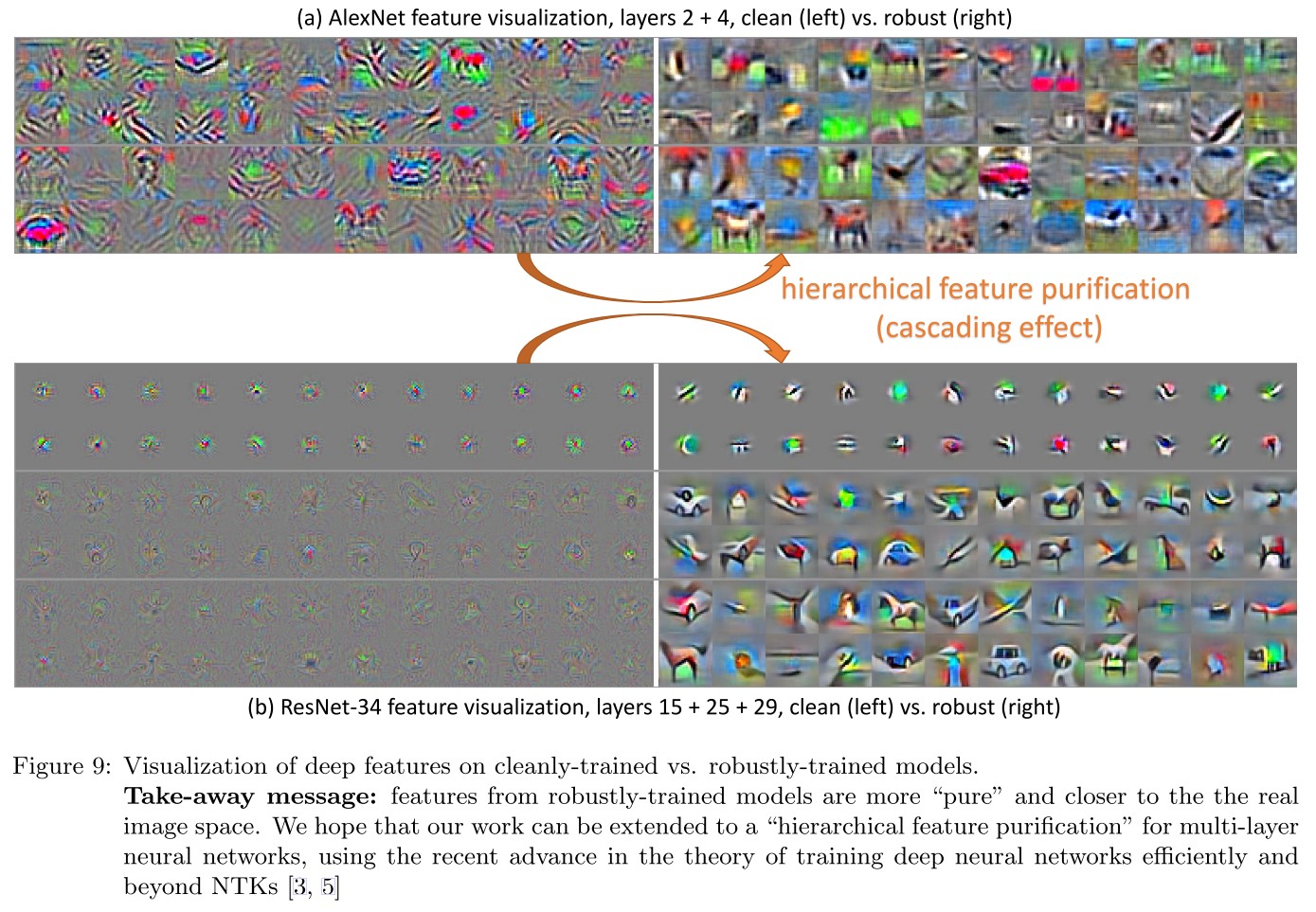
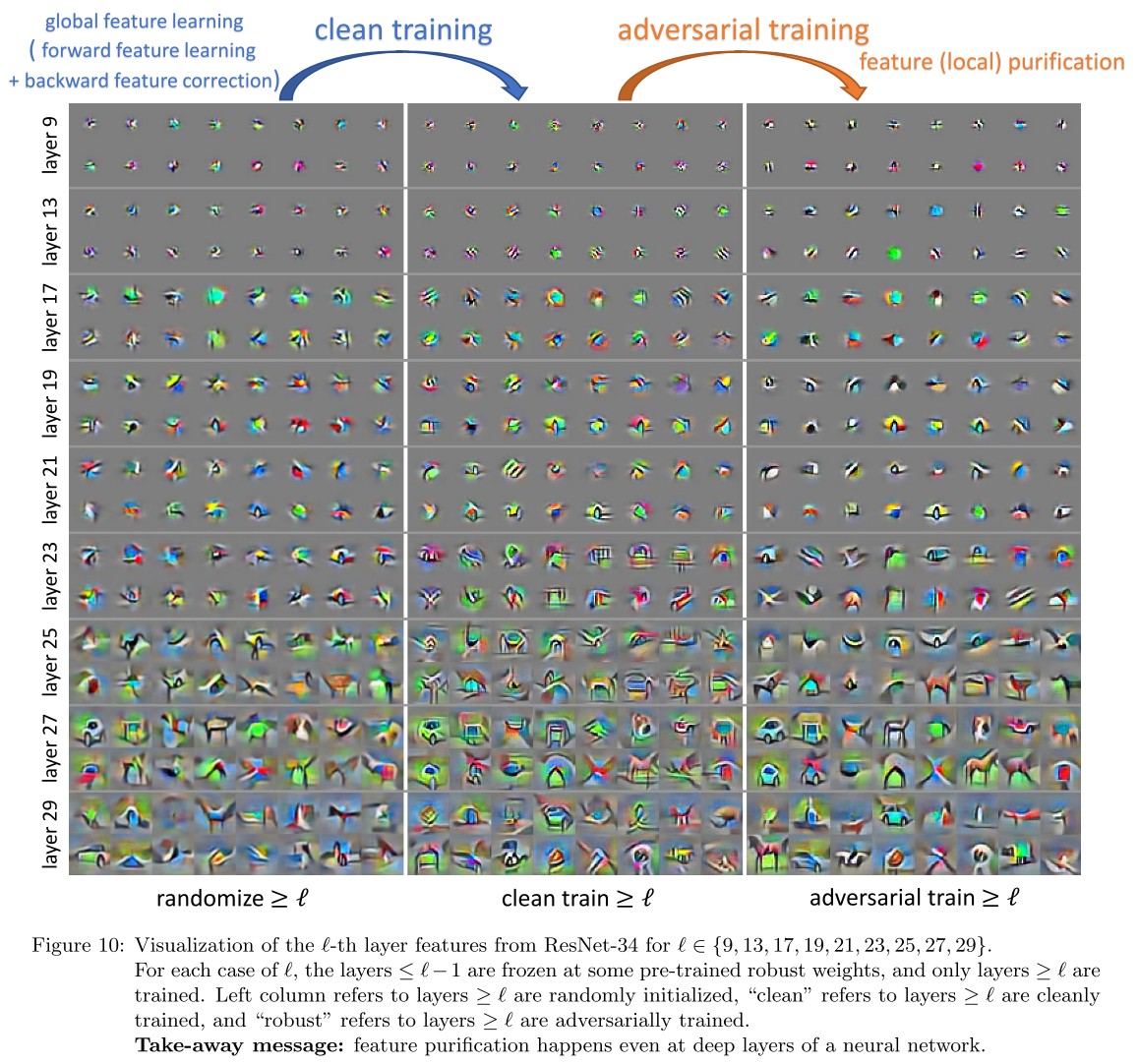

Inspirations
They propose a principle named as feature purification to describe what adversarial training is doing to the cleanly trained models.
They point out that gradient descent will accumulate dense mixtures correlated to the labeling function into the features learned, which is less correlated with inputs, therefore hurting no accuracy, but correlated perturbations towards the direction of dense mixtures lead to mistakes, making the model adversarially vulnerable.
Adversarial training instead is able to remove these dense mixtures, thus purifying the features learned by model.
It seems that adversarial training indeed does not eliminate adversarial examples, but amplify the perturbations required and spread the perturbations in a semantically meaningful way.
It also seems to indicate that a better labeling function can improve adversarial robustness.