First-order Adversarial Vulnerability
By LI Haoyang 2020.11.16
Content
First-order Adversarial VulnerabilityContentFirst-order Adversarial Vulnerability - ICML 2019From Adversarial Examples to Large GradientsA new old regularizer (defenses inspired by Lemma 2)Link to adversarially augmented trainingEvaluate Adversarial VulnerabilityOne Neuron with Many InputsFormal Statements for Deep NetworksEmpirical ResultsFirst-Order Approximation, Gradient Penalty, Adversarial AugmentationVulnerability’s Dependence on Input DimensionFurther ExperimentsInspirations
First-order Adversarial Vulnerability - ICML 2019
Code:https://github.com/facebookresearch/AdversarialAndDimensionality
Carl-Johann Simon-Gabriel, Yann Ollivier, Léon Bottou, Bernhard Schölkopf, David Lopez-Paz. First-order Adversarial Vulnerability of Neural Networks and Input Dimension. ICML 2019. arXiv:1802.01421
We show that adversarial vulnerability increases with the gradients of the training objective when viewed as a function of the inputs.
Surprisingly, vulnerability does not depend on network topology.
We empirically show that this dimension dependence persists after either usual or robust training, but gets attenuated with higher regularization.
Their contributions:
- We show an empirical one-to-one relationship between average gradient norms and adversarial vulnerability.
- We formally prove that, at initialization, the first-order vulnerability of common neural networks increases as with input dimension .
- We empirically show that this dimension dependence persists after both usual and robust (PGD) training, but gets dampened and eventually vanishes with higher regularization.
- We observe that further training after the training loss has reached its minimum can provide improved test accuracy, but severely damages the network’s robustness.
- We notice a striking discrepancy between the gradient norms (and therefore the vulnerability) on the training and test sets respectively.
From Adversarial Examples to Large Gradients
Adversarial example is a small perturbation of the inputs that creates a large variation of outputs.
Given a classifier and an input image , an adversarial image is constructed by adding a perturbation such that and .
Definition 1 Given a distribution over the input-space, we call adversarial vulnerability of a classifier to an -sized -attack the probability that there exists a perturbation of such that
The adversarial () damage is defined as the average increase-after-attack, i.e. of a loss . When is the 0-1 loss , adversarial damage is the accuracy-drop after attack, which lower bounds adversarial vulnerability.
The accuracy-drop rules out natural adversarial examples, thus lower bounds the adversarial vulnerability.
In practice, a smoother surrogate loss is used instead of the non-differentiable 0-1 loss. Hence, a classifier will be robust if, on average over , a small adversarial perturbation of creates only a small variation of the loss. (It can also be the case of obfuscated gradient.)
If , then a first order Taylor expansion in shows that
where denotes the gradient of with respect to and denotes the dual norm of .
The dual norm is defined as:
which obviously explains the last equality.
The dual norm of is , and the dual norm of is , such that .
This leads to the following lemma.
Lemma 2 At first order approximation in , an -sized adversarial attack generated with norm increase the loss at point by , where is the dual norm of . In particular, an -sized -attack increases the loss by , where and .
Moreover, we will see that the first-order predictions closely match the experiments.
This lemma shows that adversarial vulnerability depends on three main factors:
, the chosen norm of threat model
A measure of sensibility to image perturbations.
, the size of attack
A sensibility threshold.
, the expected dual norm of
The classifier's expected marginal sensibility to a unit perturbation.
For a given pixel-wise order of magnitude of the perturbations , the -norm of the perturbation will scale like , which suggests that the threshold used with -attacks can be written as
in which, denotes a dimension independent constant.
This scaling also preserves the average signal-to-noise ratio .
A new old regularizer (defenses inspired by Lemma 2)
Lemma 2 shows that the loss of the network after an -sized -attack is
It is thus natural to take this loss-after-attack as a new training objective.
In the case that , this new loss reduces to an old regularization scheme proposed by Drucker & LeCun (1991) called double backpropagation.
A priori, we do not know what will happen for attacks generated with other norms; but our experiments suggest that training with one norm also protects against other attacks.
Link to adversarially augmented training
When augmenting the training set with online generated -sized -attacks , the training objectively is
referred as adversarially augmented training by the authors. (Generally known as adversarial training.)
They prove that this 'old-plus-post-attack' loss simply reduces to the loss-after-attack loss using the first order Taylor expansion.
Proposition 3 Up to first-order approximations in , . Said differently, for small enough , adversarially augmented training with -sized -attacks amounts to penalizing the dual norm of with weight . In particular, double-backpropagation corresponds to training with -attacks, while FGSM-augmented training corresponds to an -penalty on .
This correspondence between training with perturbations and using a regularizer can be compared to Tikhonov regularization: Tikhonov regularization amounts to training with random noise Bishop (1995), while training with adversarial noise amounts to penalizing .
Evaluate Adversarial Vulnerability
One Neuron with Many Inputs
Suppose for a moment that the coordinates of have typical magnitude , then scales like , consequently
The second and the last are bridged by and .
It shows that to be robust against any type of -attack at any input-dimension , the average absolute value of the coefficients of must grow slower than . (Is it true?)
The neural weights are usually initialized with a variance that is inversely proportional to the number of inputs per neuron.
Consider the case when one output neuron is connected to all input pixels, given the initialization with a variance of , the average absolute value grows like , thus the adversarial vulnerability increases like .
Intuitively, the above sounds reasonable, but a more detailed illustration is needed to be more convincing.
This toy example shows that the standard initialization scheme, which preserves the variance from layer to layer, causes the average coordinate-size to grow like instead of . When an -attack tweaks its -sized input perturbations to align with the coordinate-signs of , all coordinates of add up in absolute value, resulting in an output-perturbation that scales like and leaves the network increasingly vulnerable with growing input-dimension.
Formal Statements for Deep Networks
These statements are based on the following set of hypotheses:
- H1 Non-input neurons are followed by a ReLU killing half of its inputs, independently of the weights.
- H2 Neurons are partitioned into layers, meaning groups that each path traverses at most once.
- H3 All weights have 0 expectation and variance 2/(in-degree) (‘He-initialization’).
- H4 The weights from different layers are independent.
- H5 Two distinct weights from a same node satisfy .
Not covering all cases, but reasonable.
Nevertheless, they do not hold after training. That is why all our statements in this section are to be understood as orders of magnitudes that are very well satisfied at initialization both in theory and practice.
Theorem 4 (Vulnerability of Fully Connected Nets) Consider a succession of fully connected layers with ReLU activations which takes inputs of dimension , satisfies assumptions , and outputs logits that get fed to a final cross-entropy-loss layer . Then the coordinated of grow like , and
These networks are thus increasingly vulnerable to -attacks with growing input-dimension.
For a given path , let the path-degree be the multiset of encountered in-degrees along path . For a fully connected network, this is the unordered sequence of layer-sizes preceding the last path-node, including the input-layer.
Choose a path of calculation, put each node's in-degrees into a set.
Consider the multiset of all path-degrees when varies among all paths from input to output . The symmetry assumption is
() All input nodes have the same multiset of path-degrees from to .
Intuitively, this means that the statistics of degrees encountered along paths to the output are the same for all input nodes. This symmetry assumption is exactly satisfied by fully connected nets, almost satisfied by CNNs (up to boundary effects, which can be alleviated via periodic or mirror padding) and exactly satisfied by strided layers, if the layersize is a multiple of the stride.
Theorem 5 (Vulnerability of Feedforward Nets). Consider any feedforward network with linear connections and ReLU activation functions. Assume the net satisfies assumptions and output logits that get fed to the cross-entropy-loss . Then is independent of the input dimension and . Moreover, if the net satisfies the symmetry assumption , then , and .
The main proof idea is that in the gradient norm computation, the He initialization exactly compensates the combinatorics of the number of paths in the network, so that this norm becomes independent of the network topology.
Corollary 6 (Vulnerability of CNNs) In any succession of convolution and dense layers, strided or not, with ReLU activations, that satisfies assumptions and outputs logits that get fed to the cross-entropy-loss , the gradient of the logit-coordinates scale like and (7) (results in theorem 4) is satisfied. It is hence increasingly vulnerable with growing input-resolution to attacks generated with any -norm.
Although the principles of our analysis naturally extend to residual nets, they are not yet covered by our theorems.
Current weight initializations (He-, Glorot-, Xavier-) are chosen to preserve the variance from layer to layer, which constrains their scaling to 1/√ in-degree.
Also note that rescaling all weights by a constant does not change the classification decisions, but it affects cross-entropy and therefore adversarial damage.
Empirical Results
First-Order Approximation, Gradient Penalty, Adversarial Augmentation
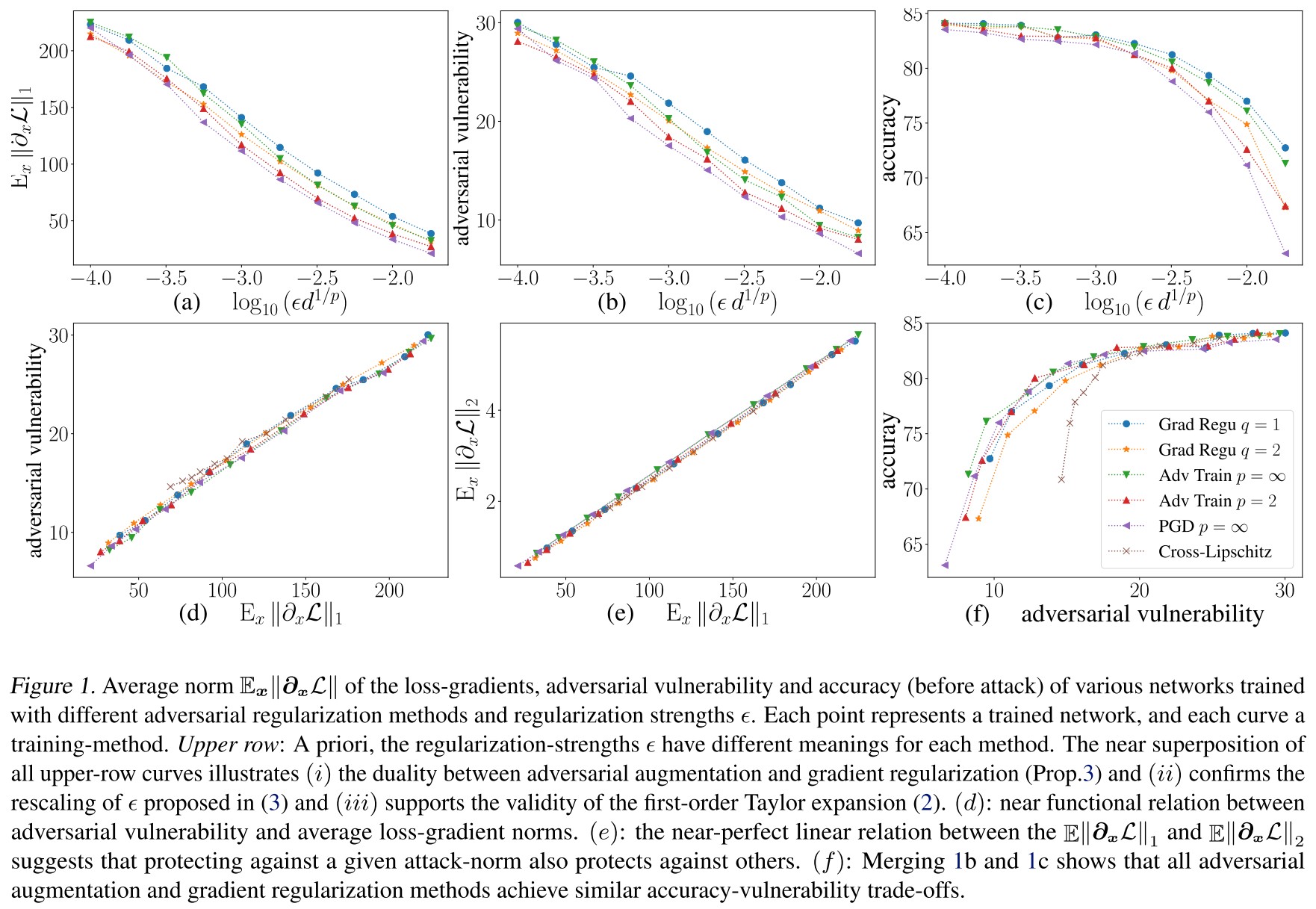
We train several CNNs with same architecture to classify CIFAR-10 images (Krizhevsky, 2009). For each net, we use a specific training method with a specific regularization value .
Note that our goal here is not to advocate one defense over another, but rather to check the validity of the Taylor expansion, and empirically verify that first order terms (i.e., gradients) suffice to explain much of the observed adversarial vulnerability.
As shown in Figure 1, they have following conclusions:
Confirming first order expansion and large first-order vulnerability
- the efficiency of the first-order defense against iterative (non-first-order) attacks (Fig.1&4a).
- the striking similarity between the PGD curves (adversarial augmentation with iterative attacks) and the other adversarial training training curves (one-step attacks/defenses).
- the functional-like dependence between any approximation of adversarial vulnerability and (Fig.4b), and its independence on the training method
- the excellent correspondence between the gradient regularization and adversarial augmentation curves (see next paragraph).
Gradient regularization matches adversarial augmentation
Confirming correspondence of norm-dependent thresholds
Accuracy-vulnerability trade-off: confirming large first-order component of vulnerability
The regularization-norm does not matter
Vulnerability’s Dependence on Input Dimension
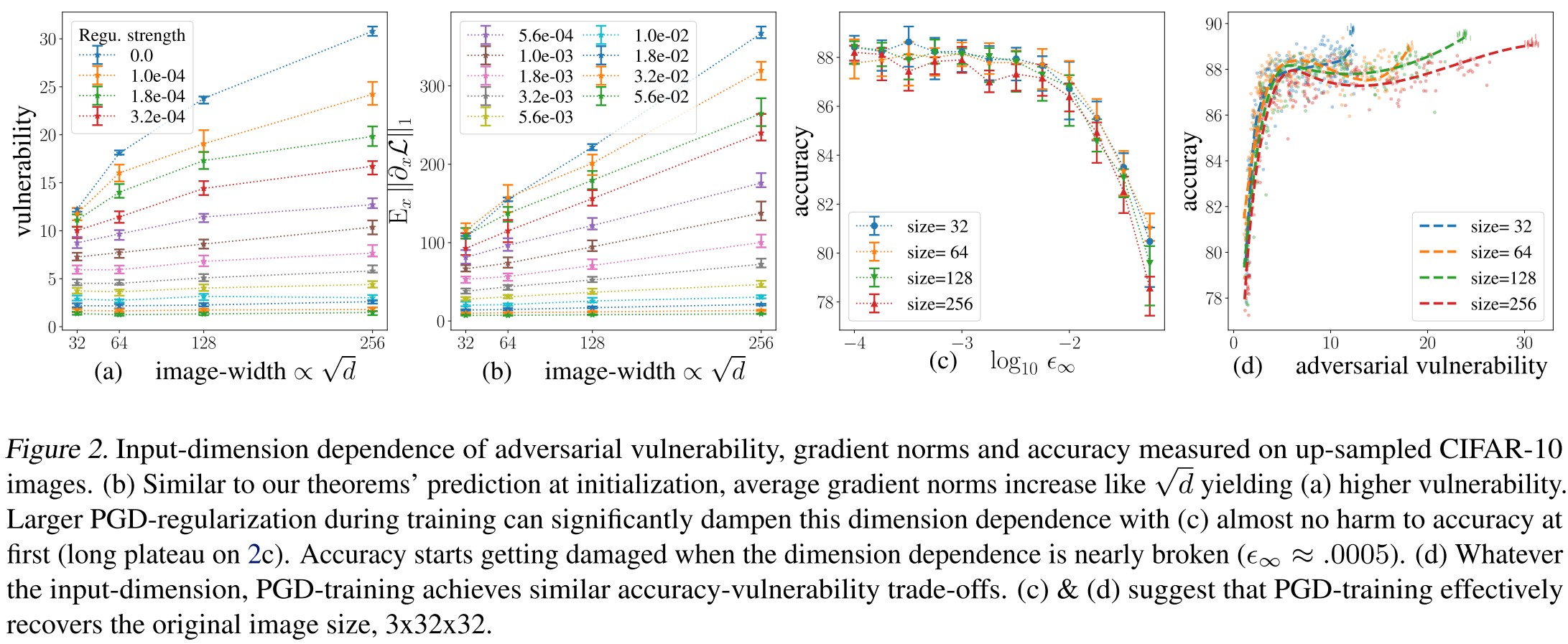
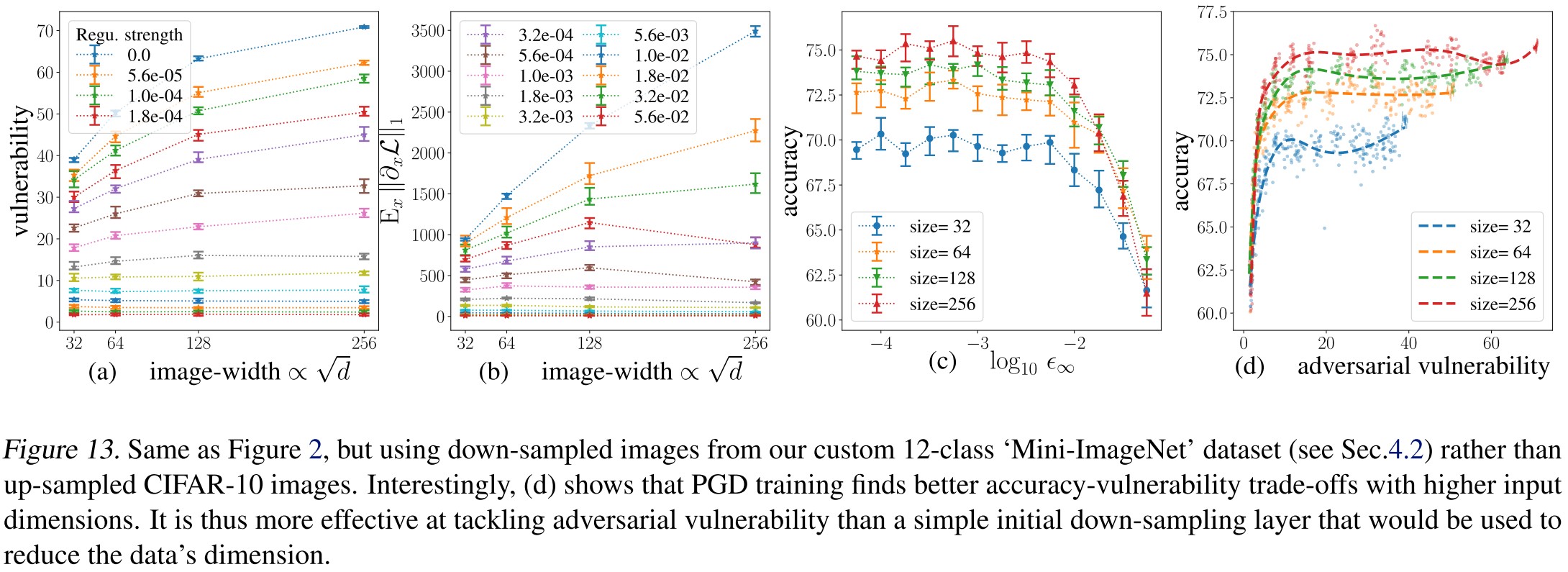
Theorems 4-5 and Corollary 6 predict a linear growth of the average -norm of with the square root of the input dimension , and therefore an increased adversarial vulnerability (Lemma 2).
As shown in Figure 2 and Figure 13, they have the following conclusions:
Gradients and vulnerability increase with . ( Figure 2 (a) and (b))
Accuracies are dimension independent ( Figure 2 (c))
This hints to defend using dimension manipulation.
PGD effectively recovers original input dimension ( Figure 2 (d))
Higher dimensions have a longer plateau to the right, because without regularization, vulnerability increases with input dimension.
The curves overlap when moving to the left, meaning that the accuracy vulnerability trade-offs achieved by PGD are essentially independent ofthe actual input dimension.
PGD training outperforms down-sampling (Figure 13.)
Further Experiments
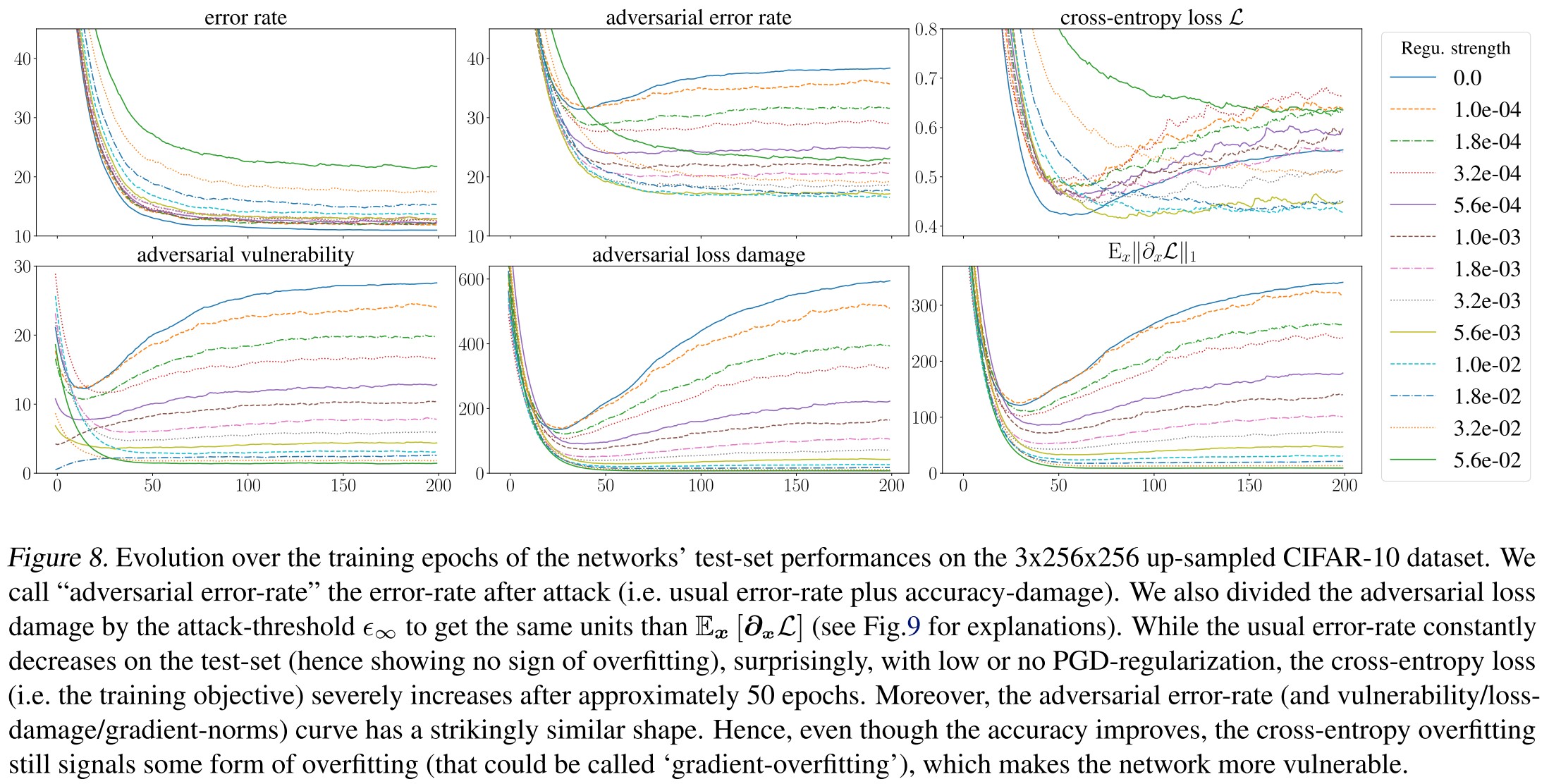
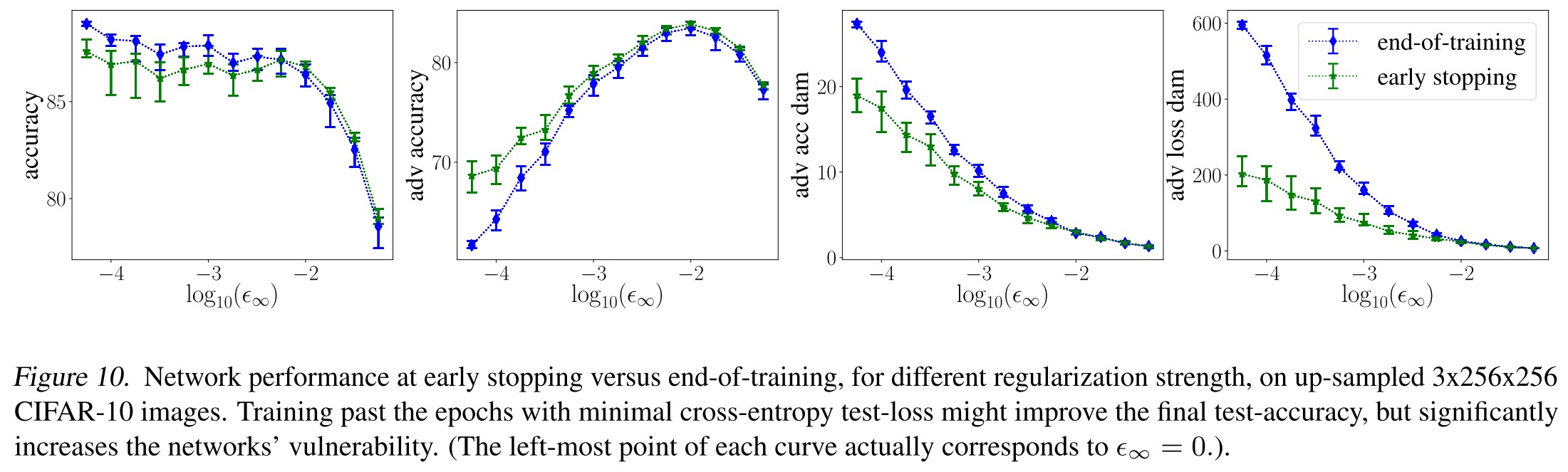
As shown in Figure 8, they have the following conclusions:
Non-equivalence of loss- and accuracy-damage. (Figure 8 a & c)
The test-error continues to decrease all over training, while the cross-entropy increases on the test set from epoch ≈ 40 and on.
Intriguing.
Early stopping dampens vulnerability
Since cross-entropy overfits, early stopping effectively acts as a defense. (Figure 10)
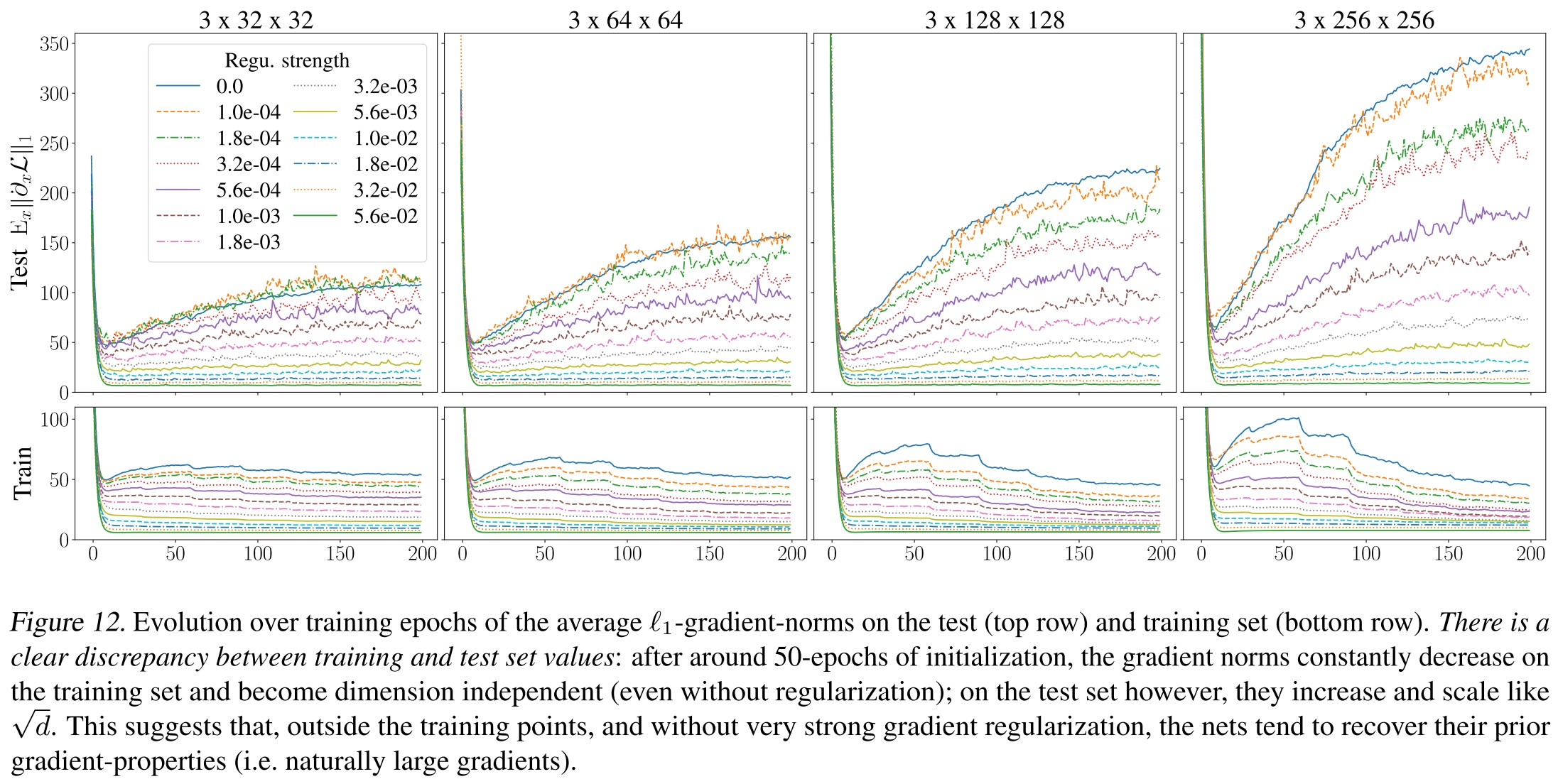
As shown in Figure 12,
Gradient norms do not generalize well
This discrepancy increases over training (gradient norms decrease on the training data but increase on the test set).
Inspirations
This paper is very informative. It bridges up the regularization with adversarial training and give many fruitful insights.
I think the subsequent defenses can cut in from the following perspectives:
- The dimension of inputs
- Regularization of gradients (JARN, GradAlign, etc.)
- New structure
- Improvement of adversarial training (as verified by this paper)