Adversarial Vulnerability
By LI Haoyang 2020.10.27
Adversarial VulnerabilityAdversarial vulnerability for any classifier - NIPS 2018SettingGenerator and classifierRobustnessUpper bounds on robustnessRelation between in-distribution robustness and unconstrained robustnessTransferability of perturbationsApproximate generative modelExperimentsInspirationsDerivation of theoremsGaussian isoperimetric inequalityTheoremTheorem 1TheoremDerivationTheorem 2TheoremProof
Adversarial vulnerability for any classifier - NIPS 2018
Paper: http://papers.nips.cc/paper/7394-adversarial-vulnerability-for-any-classifier
Alhussein Fawzi, Hamza Fawzi, Omar Fawzi. Adversarial vulnerability for any classifier. NIPS 2018.
In this paper, we study the phenomenon of adversarial perturbations under the assumption that the data is generated with a smooth generative model. We derive fundamental upper bounds on the robustness to perturbations of any classification function, and prove the existence of adversarial perturbations that transfer well across different classifiers with small risk.
Setting
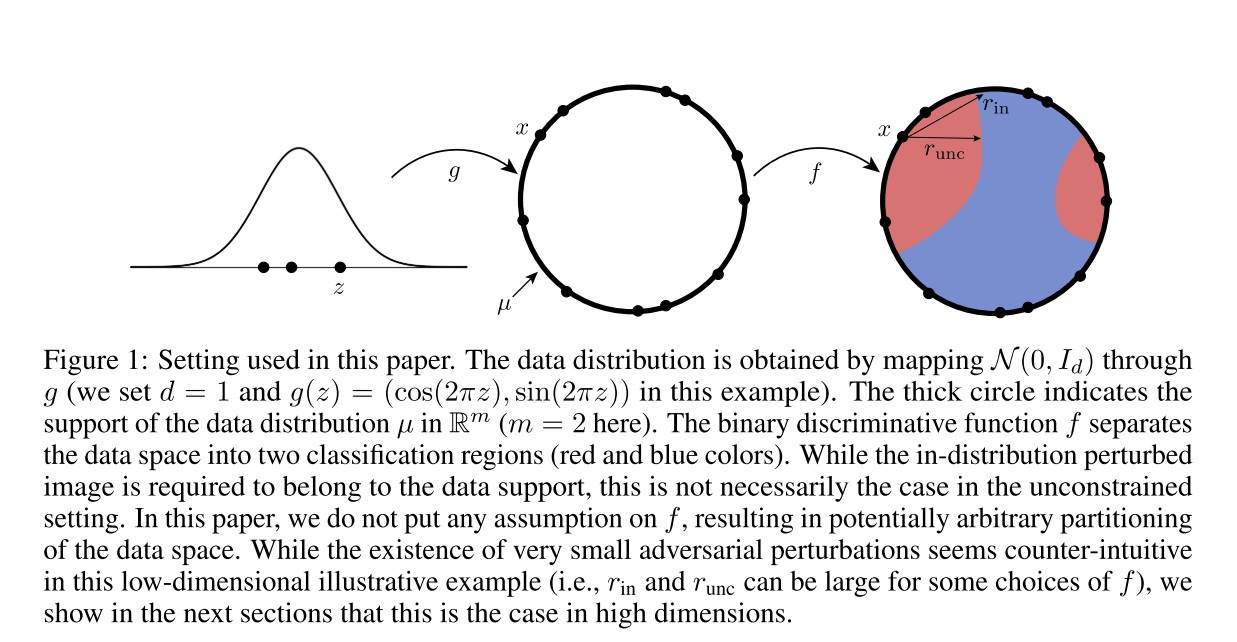
Generator and classifier
A generative model maps latent vectors into the space of images of pixels, i.e.
To generate an image according to the distribution of natural images , a random vector is sampled from a Gaussian distribution and then mapped to the space of image, i.e. .
A classifier maps images in to discrete labels , i.e.
The discriminator partitions into sets , each of which corresponds to a different predicted label.
The relative proportion of points in class is equal to
i.e. the Gaussian measure of in .
The goal of this paper is to study the robustness of to additive perturbations under the assumption that the data is generated according to .
Robustness
They define two notions of robustness.
In-distribution robustness
For , the in-distribution robustness is defined as
In short, the minimal perturbation added to original image that change the classification result while remain the perturbed image in the original distribution of images.
Unconstrained robustness
The unconstrained robustness is the general definition of adversarial perturbations, i.e.
It is easy to see that this robustness definition is smaller than the in-distribution robustness, i.e. . (why?)
They assume that the generative model is smooth in the sense that it satisfies as modulus of continuity property:
Assumption 1 We assume that admits a monotone invertible modulus of continuity , i.e.
Note that the above assumption is milder than assuming Lipschitz continuity. In fact, the Lipschitz property corresponds to choosing to be a linear function of . In particular, the above assumption does not require that , which potentially allows us to model distributions with disconnected support.
Upper bounds on robustness
Theorem 1. Let be an arbitrary classification function defined on the image space. Then, the function of datapoints having robustness less than satisfies
where is the cdf (累积分布函数) of , i.e. , and .
In particular, if for all , (the classes are not too unbalanced), we have
To see the dependence on the number of classes more explicitly, consider the setting where the classes are equiprobable, i.e. for all , then
Based on Theorem 1, there are following results
Interpretaion with
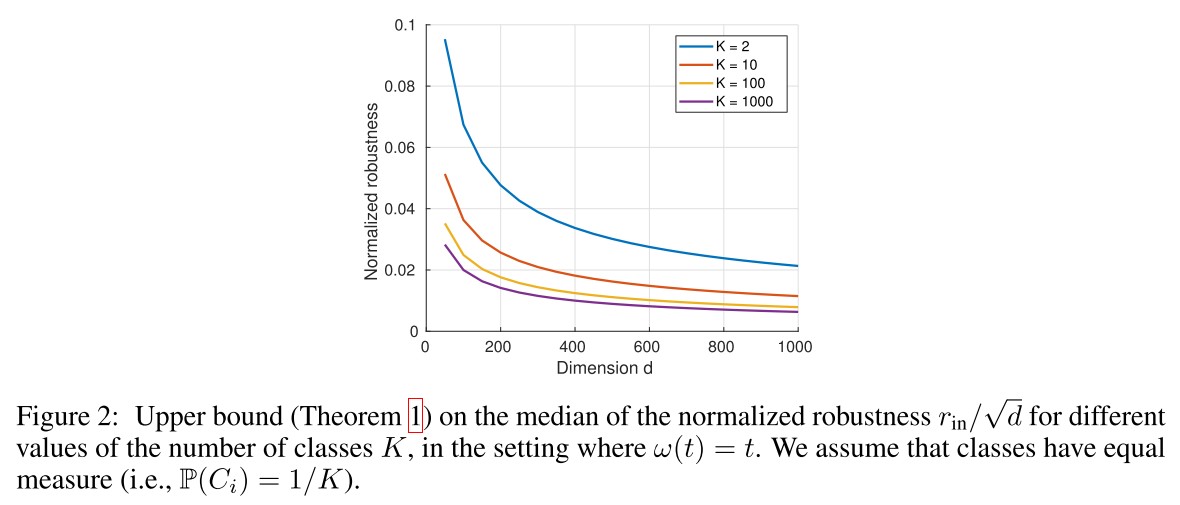
Our result shows that when is large and is smooth (i.e. , is the Lipschitz constant), there exist small adversarial perturbations that can fool arbitrary classifiers .
Dependence on
In other words, it is easier to find adversarial perturbations in the setting where the number of classes is large, than for a binary classification task.
Classification-agnostic bound
Our bounds hold for any classification function .
How tight is the upper bound?
This suggests that classifiers are maximally robust when the induced classification boundaries in the latent space are linear.
Relation between in-distribution robustness and unconstrained robustness
It's possible to construct a family of classifiers for which .
For a given classifier in the image space, define the classifier constructed in a nearest neighbor strategy:
Theorem 2. For the classifier , we have .
This result shows that if a classifier has in-distribution robustness , then we can construct a classifier with unconstrained robustness , through a simple modification of the original classifier .
This suggests that the unconstrained robustness can be increased by increasing in-distribution robustness.
Transferability of perturbations
Theorem 3 (Transferability of perturbations). Let be two classifiers. Assume that (e.g. if and have a risk bounded by for the data set generated by ). In addition, assume that for all , then
Compared to Theorem 1 which bounds the robustness to adversarial perturbations, the extra price to pay here to find transferable adversarial perturbations is the term, which is small if the risk of both classifiers is small.
This suggests that if both classifiers are easy to be fooled, it's not that difficult to find a transferable adversarial example.
Approximate generative model
Theorem 4. We use the same notations as in Theorem 1. Assume that the generator provides a approximation of the true distribution in the -Wasserstein sense on the metric space ; that is, (where is the pushforward of via ), the following inequality holds provided is concave
where is the unconstrained robustness in the image space. In particular, for equiprobable classes, we have
In words, when the data is defined according to a distribution which can be approximated by a smooth, high-dimensional generative model, our results show that arbitrary classifiers will have small adversarial examples in expectation.
We also note that as grows, this bound decreases and even goes to zero under the sole condition that is continuous at . Note however that the decrease is slow as it is only logarithmic.
This suggests that for a classification of infinity classes, the expected adversarial perturbation can be very small.
Experiments

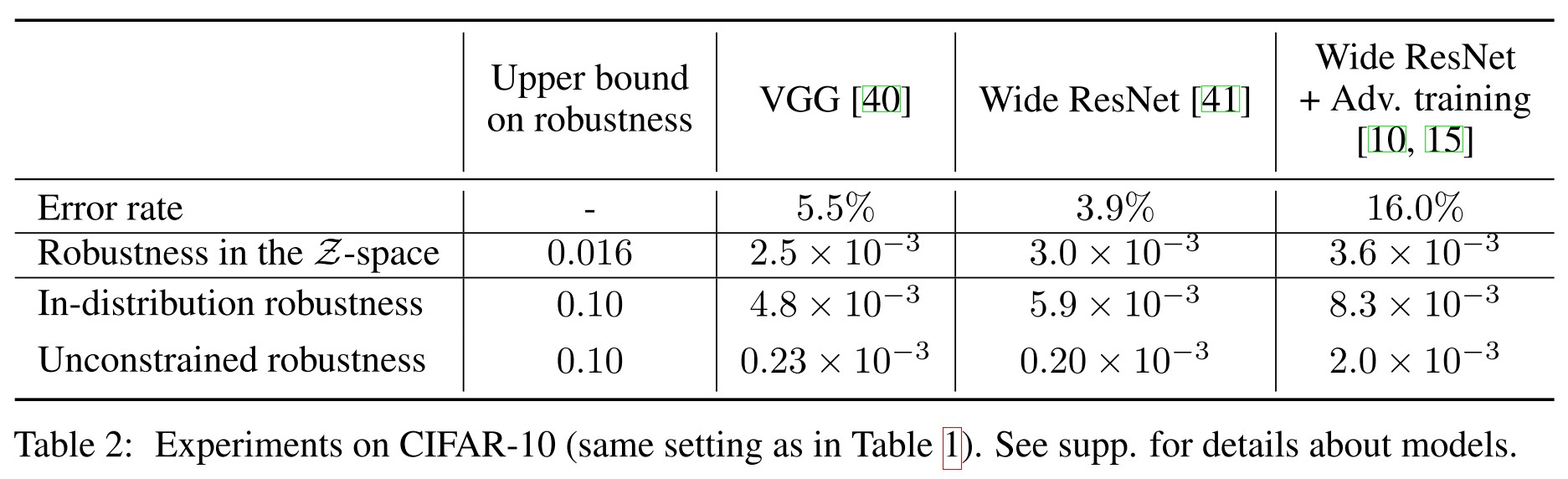
Inspirations
I admit that I don't completely understand this paper.
From the general idea, this paper suggests the following potentials
- Higher-dimensional data and more classes introduce less robustness.
- Unconstrained robustness (general robustness) can be increased by increasing in-distribution robustness (It seems to suggest that an accurate model is also important in terms of robustness?)
- A classifier is more robust if the boundary in latent space is more linear.
Derivation of theorems
Gaussian isoperimetric inequality
The standard Gaussian distribution is
Theorem
Let be the Gaussian measure on . Let and let . If , then .
In words, is a subset of points in such that every point in has at least a neighbor in closer than in terms of , the theorem says that if the probability that is sampled is , the probability that is sampled is higher than .
Theorem 1
Theorem
Let be an arbitrary classification function defined on the image space. Then, the function of datapoints having robustness less than satisfies
where is the cdf (累积分布函数) of , i.e. , and .
In particular, if for all , (the classes are not too unbalanced), we have
To see the dependence on the number of classes more explicitly, consider the setting where the classes are equiprobable, i.e. for all , then
Derivation
First, define
In short, is the distance between and the closest data in , therefore, is a set of data points classified as such that their closest distances with data points in other classes are less than , it's a set of out-most data points.
Then, define the following sets in the -space
Remind that maps the upper bound into the -space.
It's easy to verify that .
Thus, we have
Since is a superset of , the probability of the former is larger than the latter.
Remind the definition of :
We have
Remind again, is the set of points that fall into the out-most band, and is the minmal distance to move a point from the region corresponding to any class to another region classified some classes else, hence the equation above.
Note that is the set of points that are at distance at most from . (by definition)
By the Gaussian isoperimetric inequality applied with and , ()we have
As are disjoint for different , we have
And, since and , there stands the first equation in theorem 1
Intuitively, it says the probability that there exists a data point in -space whose distance to the boundary is closer than is larger than a total probability gain along .
Theorem 2
Theorem
For a given classifier in the image space, define the classifier constructed in a nearest neighbor strategy:
For the classifier , we have .
The classifier classifies as the class of its nearest neighbor in distribution.
Proof
Let and . Let be such that . By definition of , we have . As such, using the triangle inequality, we get
Taking the minimum over all such that , we obtain