Are Adversarial Example Inevitable ?
By LI Haoyang 2020.12.8
Content
Are Adversarial Example Inevitable ?ContentAre Adversarial Example Inevitable? - ICLR 2019NotationProblem SetupAdversarial Example on the Unit SphereAdversarial Example on the Unit CubeSparse Adversarial ExamplesExistence of Adversarial ExamplesCan We Escape Fundamental Bounds?ExperimentsAre Adversarial Examples Inevitable?Inspirations
Are Adversarial Example Inevitable? - ICLR 2019
Ali Shafahi, W. Ronny Huang, Christoph Studer, Soheil Feizi, Tom Goldstein. Are adversarial examples inevitable? ICLR 2019. arXiv:1809.02104
This paper analyzes adversarial examples from a theoretical perspective, and identifies fundamental bounds on the susceptibility of a classifier to adversarial attacks. We show that, for certain classes of problems, adversarial examples are inescapable.

If the image classes each occupy a fraction of the cube greater than , then images exist that are susceptible to adversarial perturbations of -norm at most.
We present an example image class for which there is no fundamental link between dimensionality and robustness, and argue that the data distribution, and not dimensionality, is the primary cause of adversarial susceptibility.
Notation
The notations they use are as follows:
, the unit hypercube in dimensions
, the volume (n-dimensional Lebesgue measure) of a subset .
, the unit sphere embedded in .
, the surface area of
, the size of subset , i.e. the surface area the set covers
, the normalized measure, it can be interpreted as the probability of a uniform random point from the sphere lying in .
-norm, i.e.
Problem Setup
Given data points that lie in a space , the classification problem refers to classify them into different object classes. These classes are defined by probability density functions , where .
A "random" point from class is a random variable with density , which is assumed to be upper bounded by .
A "classifier" function partitions into disjoint measurable subsets, one for each class label.
Definition 1 Consider a point drawn from class , a scalar , and a metric . We say that admits an -adversarial example in the metric if there exists a point with , and .
The neighborhood of expands across the classification boundary.
They consider -norm adversarial examples, and sparse adversarial example, i.e. -norm adversarial example.
Adversarial Example on the Unit Sphere
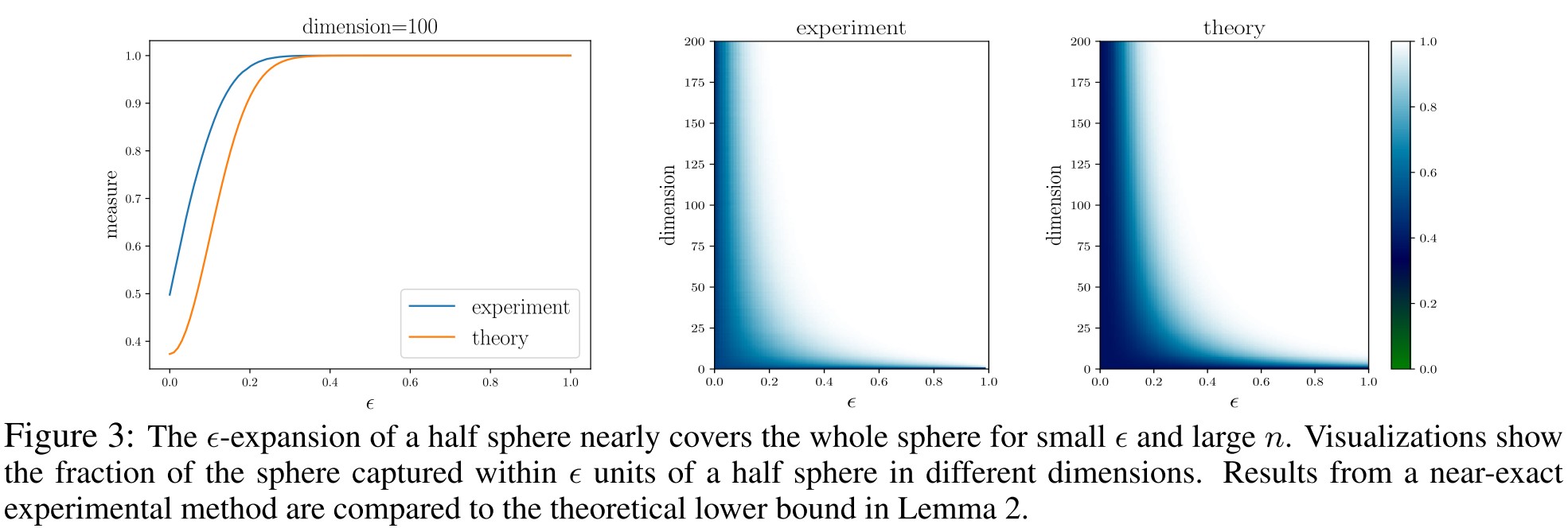
The idea is to show that, provided a class of data points takes up enough space, nearly every point in the class lies close to the class boundary.
Definition 2 The -expansion of a subset with distance metric , denoted , contains all points that are at most units away from . To be precise
This "for some" is ambiguous.....
Lemma 1 (Isoperimetric inequality). Consider a subset of the sphere with normalized measure . When using the geodesic metric, the -expansion is at least as large as the -expansion of a half sphere.
This lemma indicates that when the -nerighborhood has an error rate larger than , the error set is at least as large as a half sphere expanded with an strip.
Lemma 2 (-expansion of half sphere). The geodesic (测地) -expansion of a half sphere has normalized measure at least
Lemmas 1 and 2 together can be taken to mean that, if a set is not too small, then in high dimensions almost all points on the sphere are reachable within a short jump from that set.
If it's not smaller than a half sphere, is it really appropriate to say that it's not too small? This is ambiguous.
Despite its complex appearance, the result below is a consequence of the (relatively simple) isoperimetric inequality.
Theorem 1 (Existence of Adversarial Examples). Consider a classification problem with object classes, each distributed over the unit sphere with density functions . Choose a classifier function that partitions the sphere into measurable subsets. Define the following scalar constants:
- Let denote the magnitude of the supremum of relative to the uniform density, i.e. .
- Let be the fraction of the sphere labeled as by classifier .
Choose some class with . Sample a random data point from . Then with probability at least
one of the following conditions holds:
- is misclassified by , or
- admits an -adversarial example in the geodesic distance
This theorem states that if the semantic classification region of this sphere is smaller than a half sphere, then there is a high probability that any data point inside can reach outside within a small geodesic step of .
Since for any two points and on a sphere,
where and denote the , Euclidean and geodesic distance respectively, therefore, any -adversarial example in the geodesic metric would also be adversarial in the other two metrics, and the bound in Theorem 1 holds regardless of which of the three metrics we choose.
Adversarial Example on the Unit Cube
In a more typical situation, images will be scaled so that their pixels lie in [0, 1], and data lies inside a high-dimensional hypercube (but, unlike the sphere, data is not confined to its surface).
Fortunately, researchers have been able to derive “algebraic” isoperimetric inequalities that provide lower bounds on the size of the -expansion of sets without identifying the shape that achieves this minimum.
Lemma 3 (Isoperimetric inequality on a cube). Consider a measurable subset of the cube , and a -norm distance metric . Let , and let be the scalar that satisfies . Then
where . In particular, if , then we simply have
This lemma states that if the subset occupies more than a half of this space, an -extension of this subset will occupy nearly the whole space.....?
Using this result, we can show that most data samples in a cube admit adversarial examples, provided the data distribution is not excessively concentrated.
Theorem 2 (Adversarial examples on the cube). Consider a classification problem with classes, each distributed over the unit hypercube with density functions . Choose a classifier function that partitions the hypercube into disjoint measurable subsets. Define the following scalar constants:
- Let denote the supremum of .
- Let be the fraction of hypercube partitioned into class by .
Choose some class with , and select an -norm with . Define . Sample a random data point from the class distribution . Then with probability at least
one of the following conditions holds:
- is misclassified by , or
- has an adversarial example , with .
For any , the bound becomes
It's because ...
As long as the class distribution is not overly concentrated, this bound guarantees adversarial examples with relatively "small" relative to a typical vector.
When using the -norm, the bound is still equation 5, but the adversarial examples are only interesting if , where the equation 5 becomes vacuous for large .
I think they want to say that when , the equation 5 rapidly reaches 1 as reaches 1.
They state that using the tighter bound of equation 2, equation 4 can be replaced with
for , where , and .
For this bound to be meaningful with , we need to be relatively small, and to be roughly or smaller. This is realistic for some problems; ImageNet has 1000 classes, and so for at least one class.
Interestingly, under -norm attacks, guarantees of adversarial examples are much stronger on the sphere (Section 3) than on the cube.
One can construct examples of sets with -expansions that nearly match the behavior of equation 5, and so our theorems in this case are actually quite tight.
I do not get the sense of the last few paragraphs of this section.
Sparse Adversarial Examples
Sparse adversarial examples refer to adversarial examples under the metric, i.e.
If a point has an -adversarial example in this norm, then it can be perturbed into a different class by modifying at most pixels (in this case is taken to be a positive integer)
Theorem 2 is fairly tight for p = 1 or 2. However, the bound becomes quite loose for small p, and in particular it fails completely for the important case of p = 0.
Lemma 4 (Isoperimetric inequality on the cube: small ). Consider a measurable subset of the cube , and a -norm distance metric . We have
Theorem 3 (Sparse adversarial examples). Consider the problem setup of Theorem 2. Choose some class with , and sample a random data point from the class distribution . Then with probability at least
one of the following conditions holds:
- is misclassified by , or
- can be adversarially perturbed by modifying at most pixels, while still remaining in the unit hypercube.
Using this equation, the probability for a uniformly distributed MNIST dataset to have an one-pixel adversarial example is more than 0.8....
I think it's misaligned with the experimental results.
Existence of Adversarial Examples
Tighter bounds can be obtained if we only guarantee that adversarial examples exist for some data points in a class, without bounding the probability of this event.
Theorem 4 (Condition for existence of adversarial examples). Consider the setup of Theorem 2. Choose a class that occupies a fraction of the cube . Pick an -norm and set .
Let denote the support (支集) of . Then there is a point with that admits an -adversarial example if
The bound for the case is valid only if .
From wikipedia:
The support of a distribution is the smallest closed interval/set whose complement has probability zero. It may be understood as the points or elements that are actual members of the distribution.
This theorem states that if the distribution distributes large enough, there exists an adversarial example for sure.
When the -norm is used, the bound becomes
The diameter of the cube is , and the bound becomes active for
It can be seen that the bound is active whenever the size of the support satisfies
Remarkably, this holds for large whenever the support of class is larger than (or contains) a hypercube of side length at least .
It seems to say that as long as the data of this class is distributed larger than a small hypercube, there exists an adversarial example.
It is important note, however, that the bound being “active” does not mean there are adversarial examples with a “small” .
Luckily, if we restrict the adversarial examples to defend to be small, it's still solvable seemingly.
Can We Escape Fundamental Bounds?
There are a number of ways to escape the guarantees of adversarial examples made by Theorems 1-4. One potential escape is for the class density functions to take on extremely large values.
Unbounded density functions and low-dimensional data manifolds
In practice, image datasets might lie on low-dimensional manifolds within the cube, and the support of these distributions could have measure zero, making the density function infinite (i.e., )
Adding a “don’t know” class
The analysis above assumes the classifier assigns a label to every point in the cube. If a classifier has the ability to say “I don’t know,” rather than assign a label to every input, then the region of the cube that is assigned class labels might be very small, and adversarial examples could be escaped even if the other assumptions of Theorem 4 are satisfied. In this case, it would still be easy for the adversary to degrade classifier performance by perturbing images into the “don’t know” class.
It does not solve the problem.....
Feature squeezing
If decreasing the dimensionality of data does not lead to substantially increased values for (we see in Section 8 that this is a reasonable assumption) or loss in accuracy (a stronger assumption), measuring data in lower dimensions could increase robustness.
It seems to me that is better to be larger, so the probability lower bound is smaller.....
Computational hardness
It may be computationally hard to craft adversarial examples because of local flatness of the classification function, obscurity of the classifier function, or other computational difficulties.
This is the defense of gradient masking....But it does not solve the problem either.
Experiments
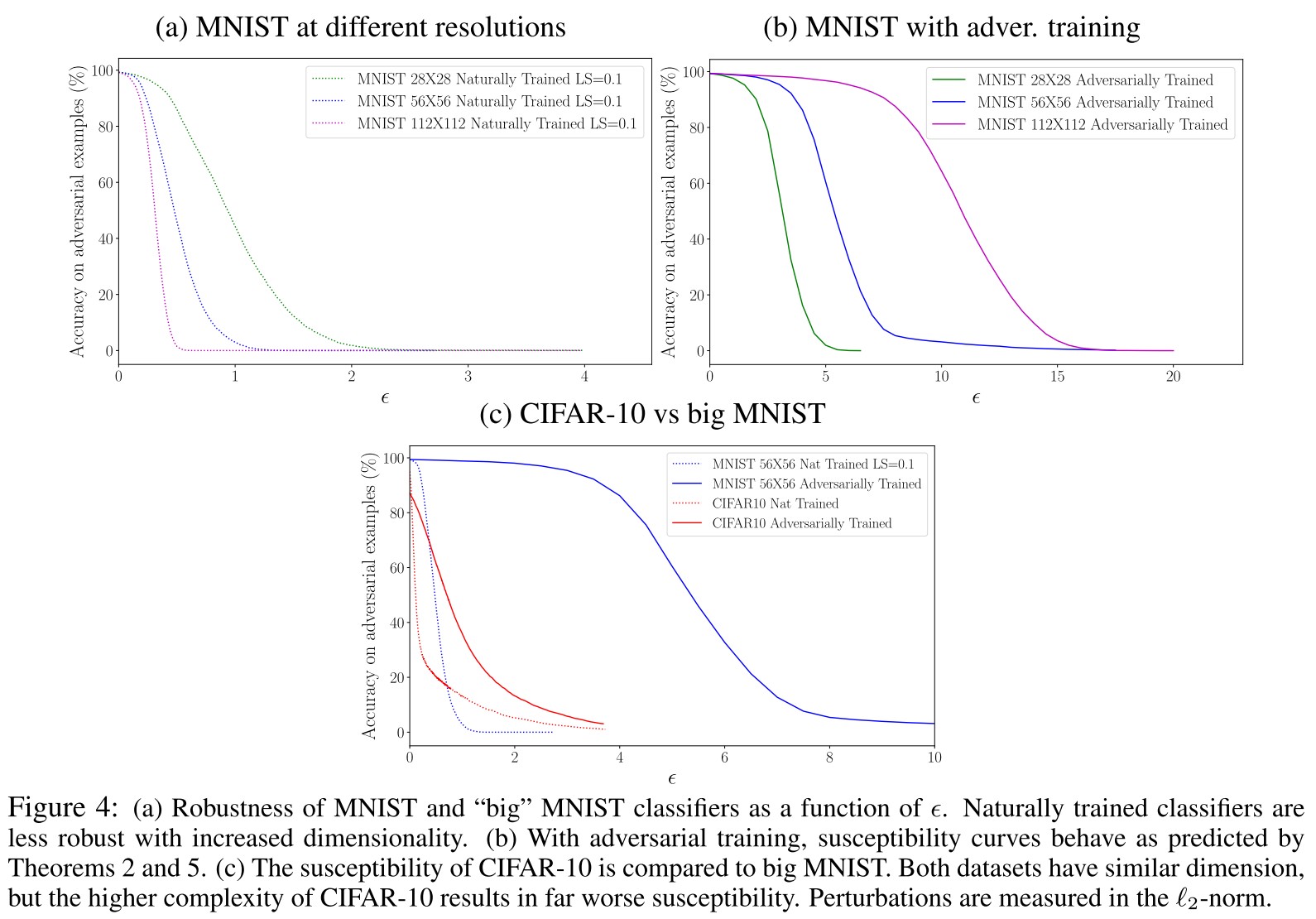
It is commonly thought that high-dimensional classifiers are more susceptible to adversarial examples than low-dimensional classifiers. This perception is partially motivated by the observation that classifiers on highresolution image distributions like ImageNet are more easily fooled than low resolution classifiers on MNIST.
We will see below that high dimensional distributions may be more concentrated than their low-dimensional counterparts.
The theorem below shows that these fundamental limits do not depend in a non-trivial way on the dimensionality of the images in big MNIST, and so the relationship between dimensionality and susceptibility in Figure 4a results from the weakness of the training process.
Theorem 5 Suppose and are such that, for all MNIST classifiers, a random image from class has an -adversarial example (in the -norm) with probability at least . Then for all classifiers on b-MNIST, with integer , a random image from has a -adversarial example with probability at least .
Likewise, if all -MNIST classifiers have -adversarial examples with probability for some , then all classifiers on the original MNIST distribution have -adversarial examples with probability .
They want to state that the vulnerability stems from data distribution and it is trivially related to dimensionality.
Theorem 5 predicts that the perturbation needed to fool all 56 × 56 classifiers is twice that needed to fool all 28 × 28 classifiers. This is reasonable since the -norm of a 56 × 56 image is twice that of its 28 × 28 counterpart.
As shown in Figure 4b:
As predicted by Theorem 5, the 112×112 classifier curve is twice as wide as the 56×56 curve, which in turn is twice as wide as the 28×28 curve. In addition, we see the kind of “phase transition” behavior predicted by Theorem 2, in which the classifier suddenly changes from being highly robust to being highly susceptible as passes a critical threshold.
For these reasons, it is reasonable to suspect that the adversarially trained classifiers in Figure 4b are operating near the fundamental limit predicted by Theorem 2.
This is a theoretically backup for adversarial training.....
But then why are high-dimensional classifiers so easy to fool?
The smallest possible value of is 1, which only occurs when images are “spread out” with uniform, uncorrelated pixels. In contrast, adjacent pixels in MNIST (and especially big MNIST) are very highly correlated, and images are concentrated near simple, low-dimensional manifolds, resulting in highly concentrated image classes with large .
is defined as the supremum of a density function , how can it be larger than 1?
As shown in Figure 4c:
We can reduce and dramatically increase susceptibility by choosing a more “spread out” dataset, like CIFAR-10, in which adjacent pixels are less strongly correlated and images appear to concentrate near complex, higher-dimensional manifolds.
The former problem lives in 3136 dimensions, while the latter lives in 3072, and both have 10 classes. Despite the structural similarities between these problems, the decreased concentration of CIFAR-10 results in vastly more susceptibility to attacks, regardless of whether adversarial training is used.
Informally, the concentration limit can be interpreted as a measure of image complexity. Image classes with smaller are likely concentrated near high-dimensional complex manifolds, have more intra-class variation, and thus more apparent complexity.
An informal interpretation of Theorem 2 is that “high complexity” image classes are fundamentally more susceptible to adversarial examples.
The interpretation is reasonable, but the meaning of seems to be ambiguous.
Are Adversarial Examples Inevitable?
The question of whether adversarial examples are inevitable is an ill-posed one. Clearly, any classification problem has a fundamental limit on robustness to adversarial attacks that cannot be escaped by any classifier. However, we have seen that these limits depend not only on fundamental properties of the dataset, but also on the strength of the adversary and the metric used to measure perturbations. This paper provides a characterization of these limits and how they depend on properties of the data distribution. Unfortunately, it is impossible to know the exact properties of real-world image distributions or the resulting fundamental limits of adversarial training for specific datasets. However, the analysis and experiments in this paper suggest that, especially for complex image classes in high-dimensional spaces, these limits may be far worse than our intuition tells us.
Inspirations
They give a comprehensive analysis of the existence of adversarial examples. They point out that the higher adversarial vulnerability of higher dimensional data stems from the training process and use adversarially trained models demonstrate that fundamentally the adversarial perturbation required increases as dimension increases.
Thus, fundamentally, the adversarial vulnerability stems from data distribution, i.e. the concentration of data points from each class.
This explains why CIFAR-10 is much more difficult than MNIST for adversarial robustness.