Orthogonal Convolution
By LI Haoyang 2020.10.19
Content
Orthogonal ConvolutionContentOCNNKernel Orthogonality VS Orthogonal CNNOrthogonal ConvolutionConvolution as a matrix-vector multiplicationConvolutional orthogonalityPerformanceRobustness under Adversarial AttackInspirations
OCNN
Paper: https://arxiv.org/abs/1911.12207v1
Code: https://github.com/samaonline/Orthogonal-Convolutional-Neural-Networks
Jiayun Wang Yubei Chen Rudrasis Chakraborty Stella X. Yu. Orthogonal Convolutional Neural Networks. CVPR 2020
Kernel Orthogonality VS Orthogonal CNN
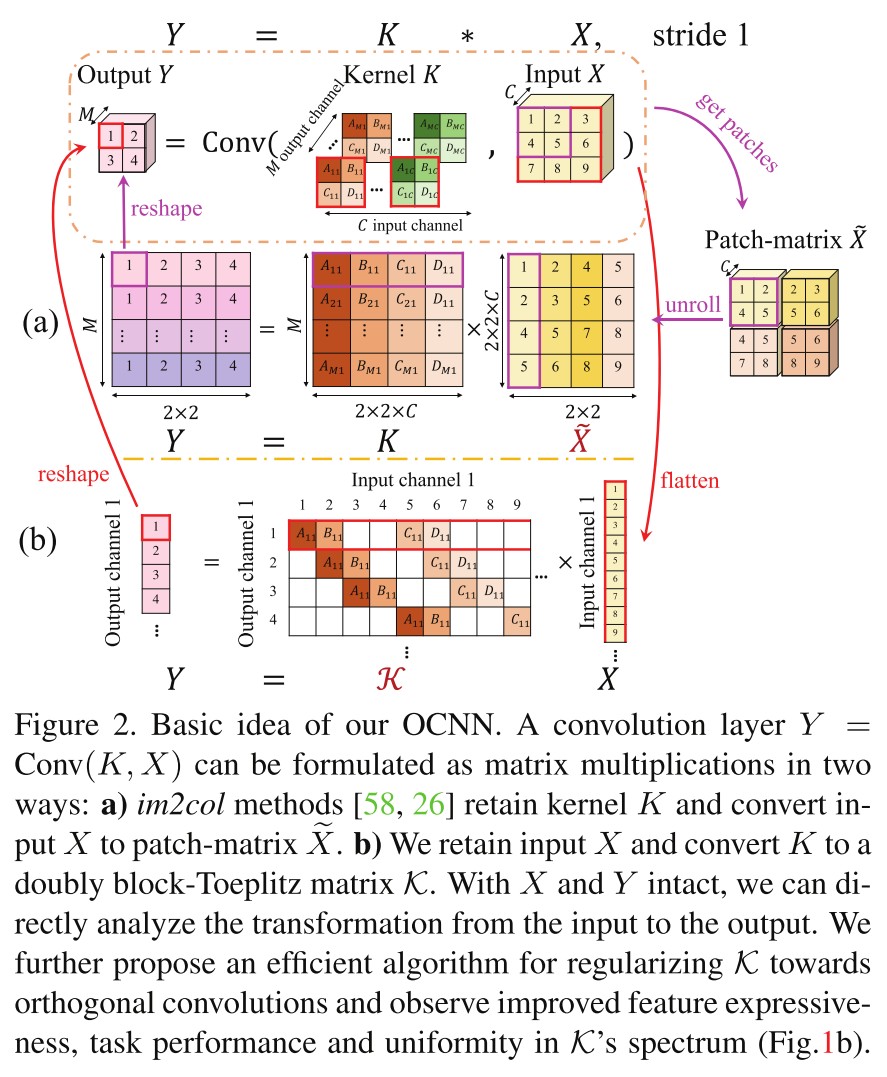
For a convolution layer , the differences are:
Kernel orthogonality
It views the convolution as multiplication between the kernel matrix and the im2col matrix , i.e. .
The orthogonality is enforced by penalizing the disparity between the Gram matrix of kernel and the identity matrix, i.e. .
Orthogonal convolution
It keeps the input and the output intact by connecting them with a doubly block-Toeplitz (DBT) matrix of filter , i.e. and enforces the orthogonality of directly.
Orthogonal Convolution
Convolution as a matrix-vector multiplication
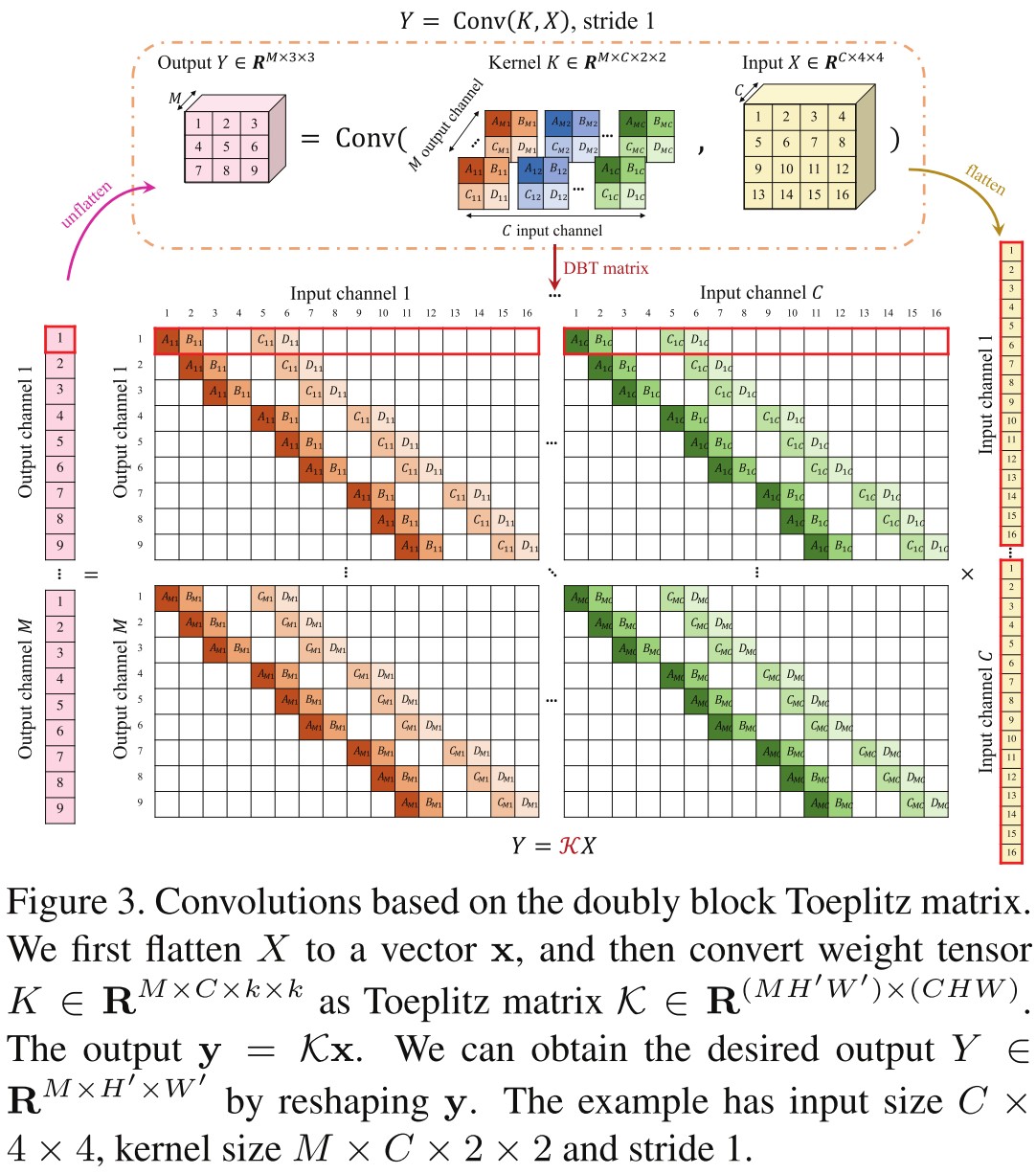
For a convolution layer with input tensor and kernel , which can be viewed as different filters .i.e. , the convolution's output tensor is , where . Since convolution is linear, it can be rewritten in a matrix-vector form:
In which, and are the flattened version of and .
Each row of has non-zero entries corresponding to a particular filter , it can be constructed as a doubly block-Toeplitz (DBT) matrix from kernel tensor .
Convolutional orthogonality
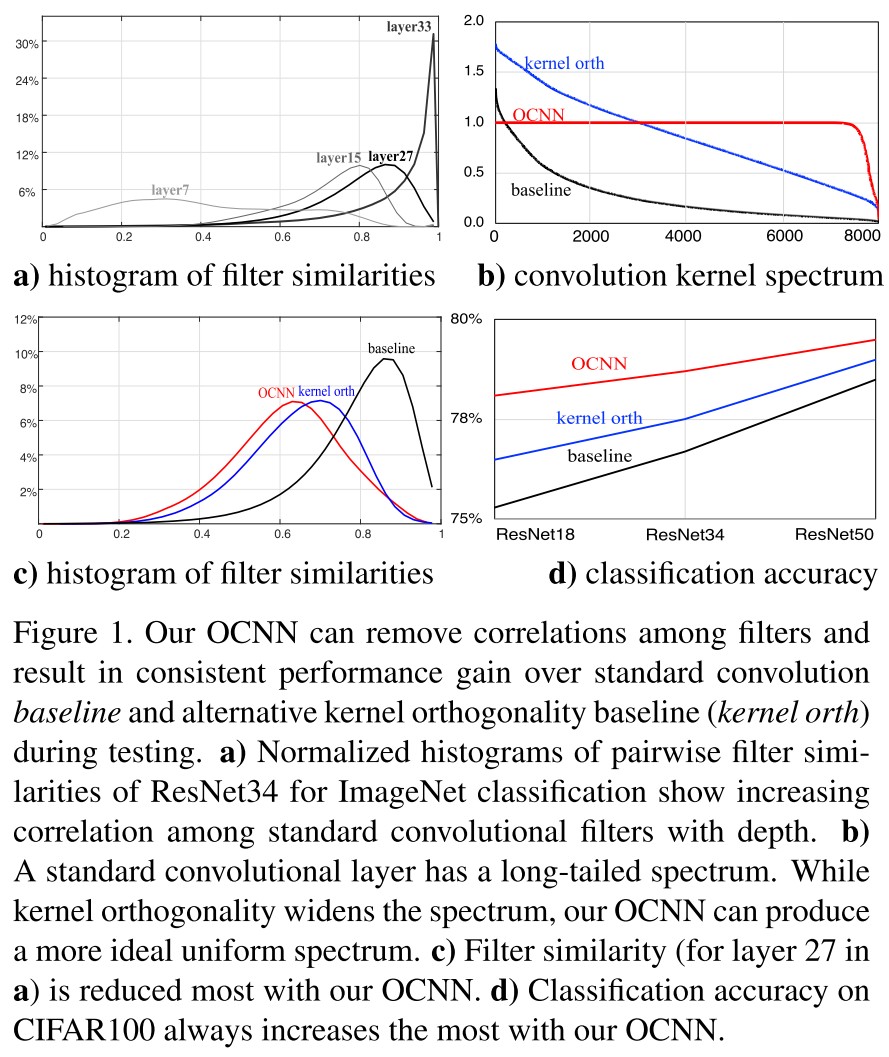
To increase the orthogonality of convolution, their approach is to regularize the spectrum of to be uniform.
The uniform spectrum requires a row orthogonal convolution for a fat matrix case () and a column orthogonal convolution for a tall matrix case () where is a normalized frame and preserves the norm.
Row Orthogonality
Each row of is a flattened filter , denoted as .
The row orthogonality condition is:
For the patches whose flattened version do not overlap, the corresponding rows are naturally orthogonal, i.e. those of or .
By implementation, they can utilize the spatial symmetry to vary only, with fixed . The region to check orthogonality can be realized by the original convolution with padding: , where the denotes the stride.
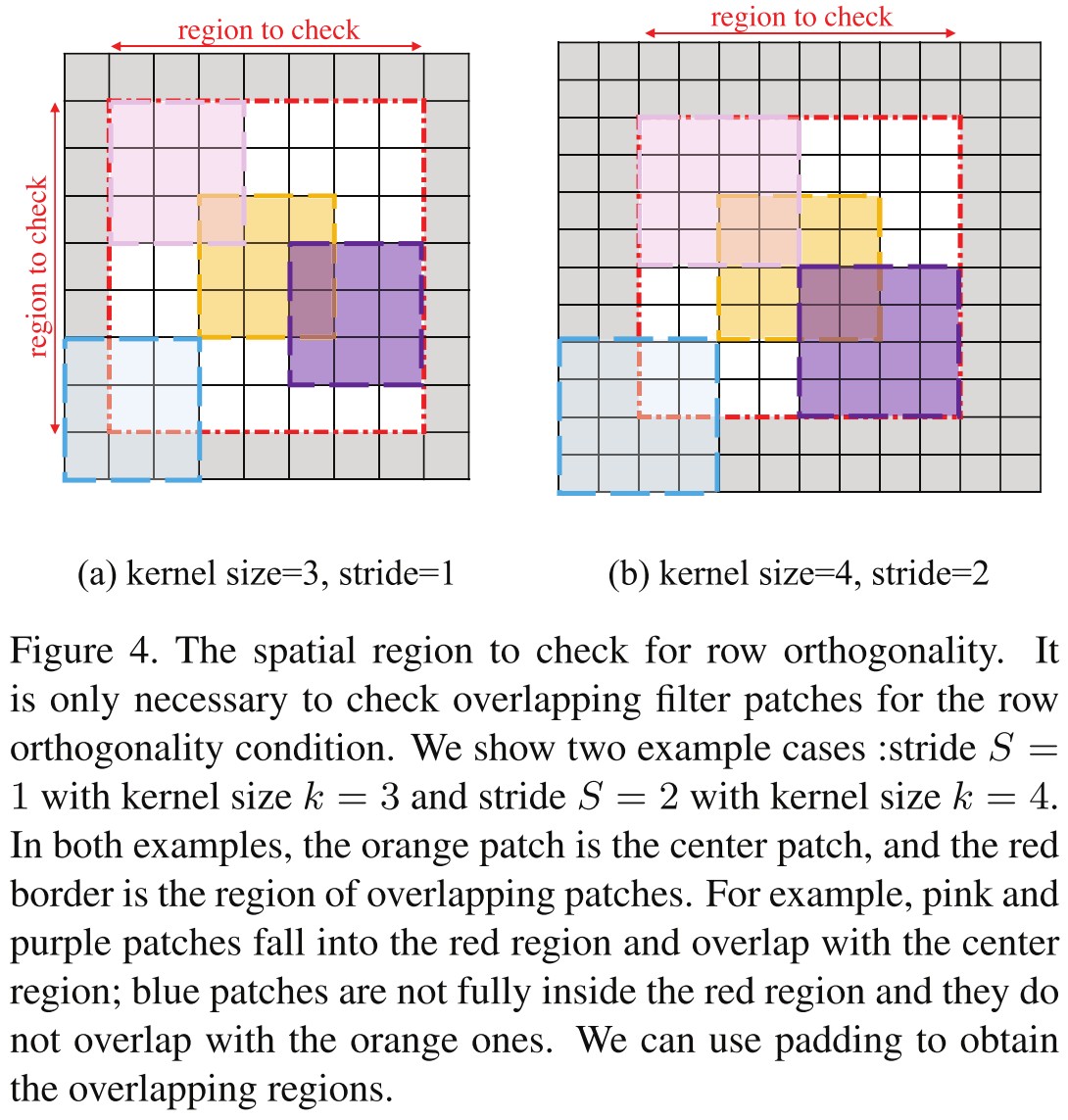
Then the condition is equivalent to the following self-convolution:
In which, is tensor who has zero entries except for center entries as an identity matrix.
Column Orthogonality
One can obtain a column of by the following equation:
In which, is the flattened vector of an artificial input , who has all zero except an 1 entry at .
The column orthogonality condition is:
There is also a simpler equivalent of this condition (with stride 1):
In which, is the input-output transposed , i.e. , has all zeros except for the center entries as an identity matrix.
The kernel row and column orthogonality is a special case of the conditions above when the stride is :
In which, and are identity matrices.
This condition is clearly necessary but not sufficient for the orthogonal convolution conditions.
Given the following Lemma:
Lemma 1. The row orthogonality and column orthogonality are equivalent in the MSE sense, i.e. , where is a constant.
The finally loss with regularization is:
Performance
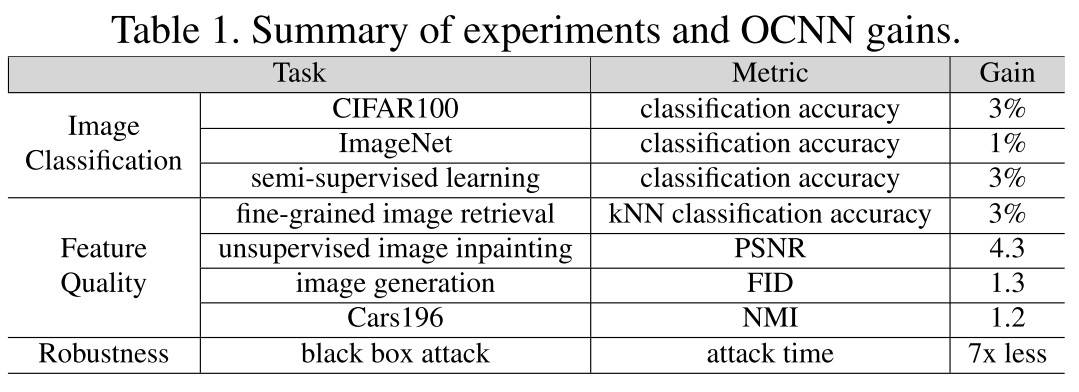
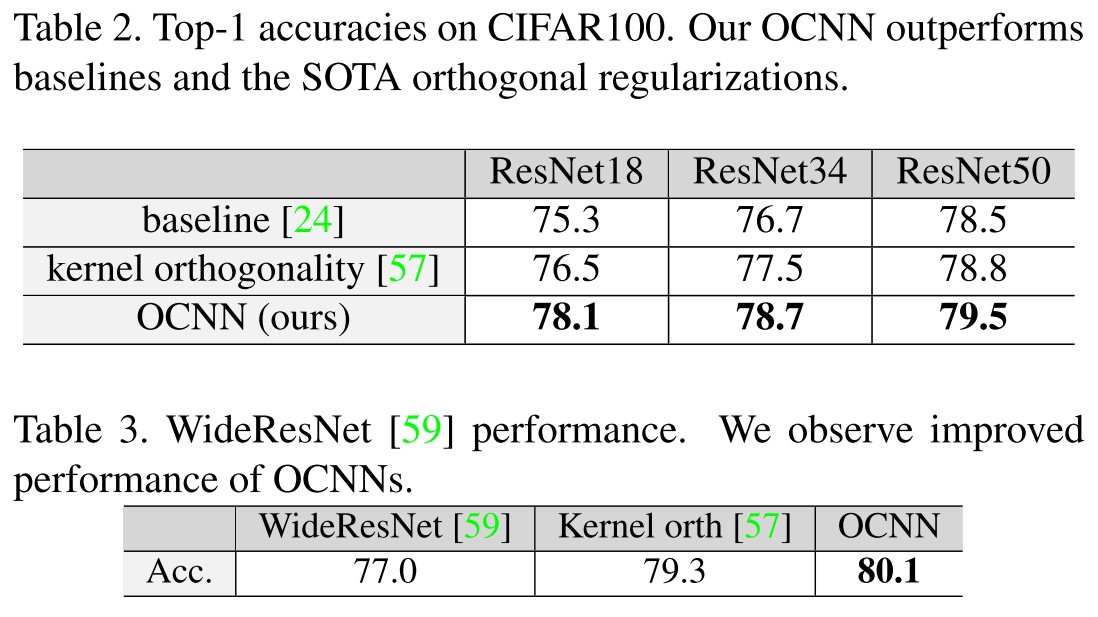
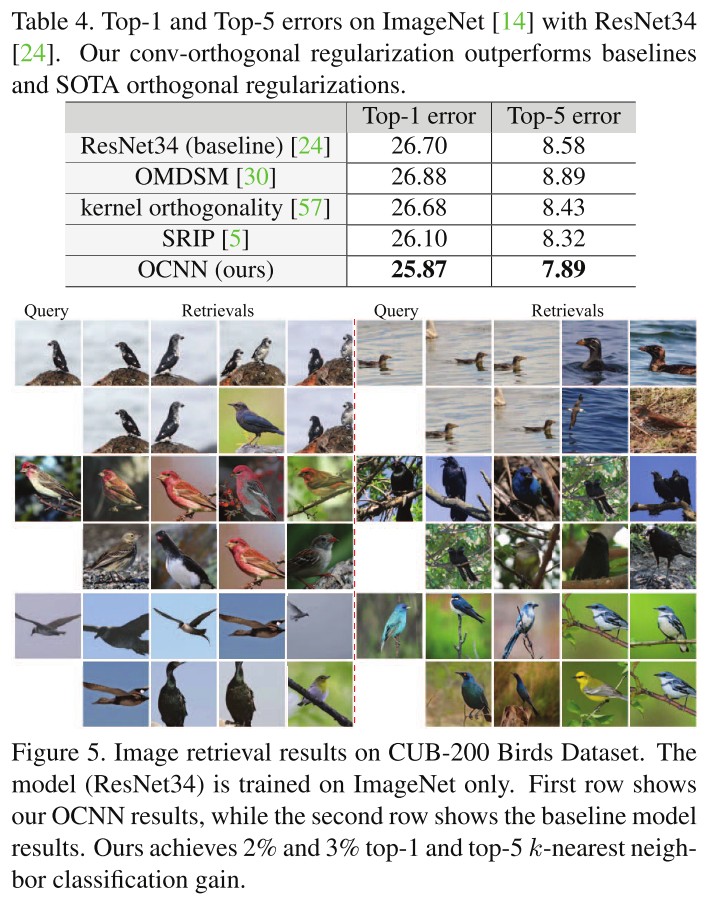
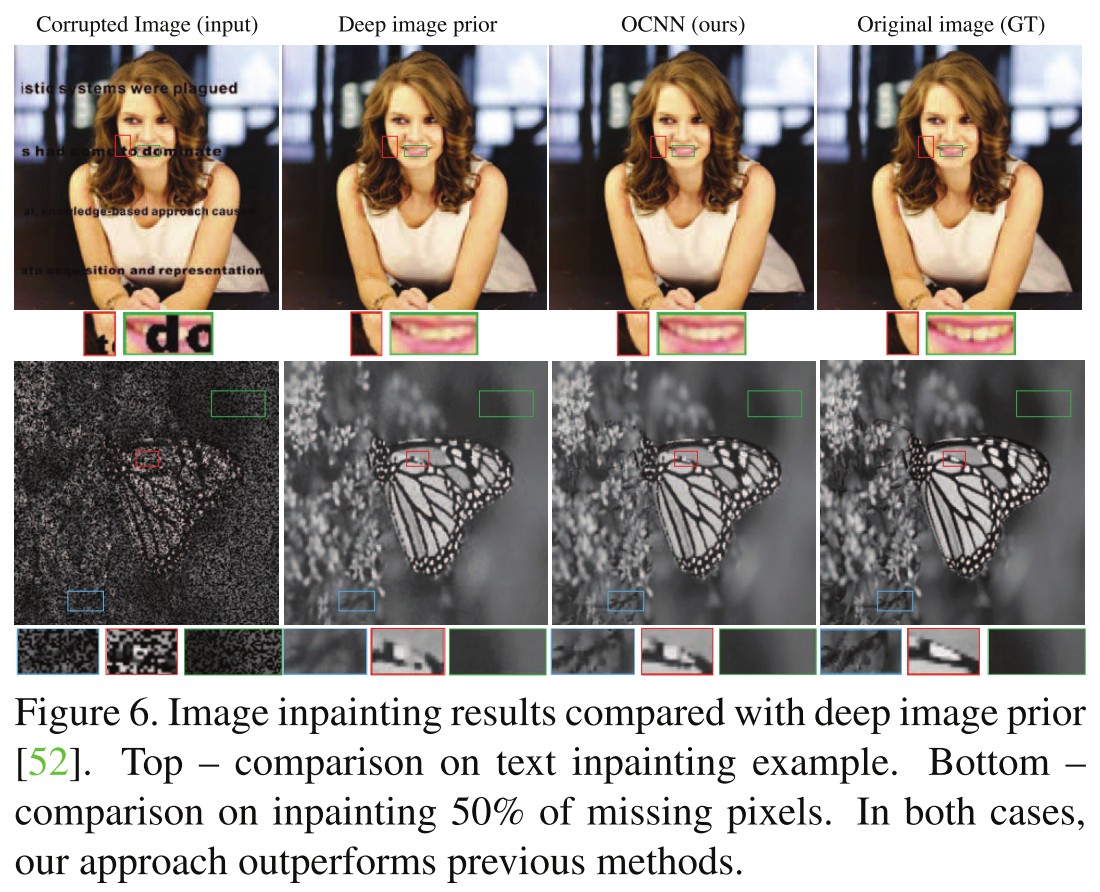
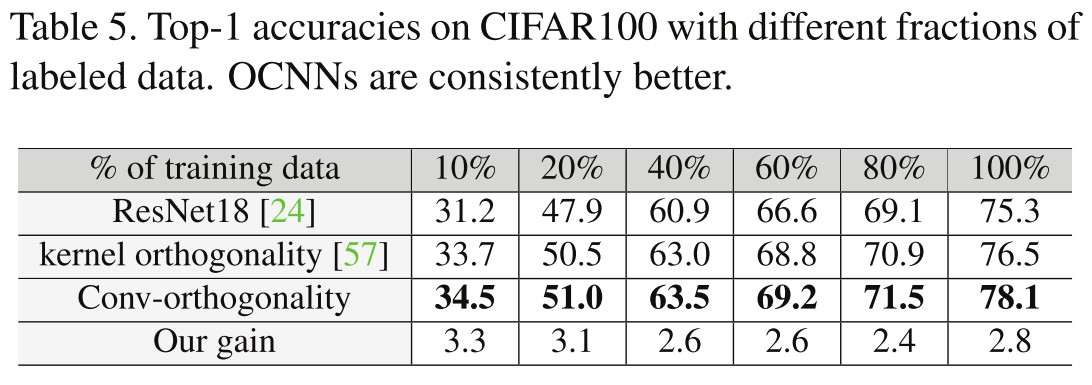
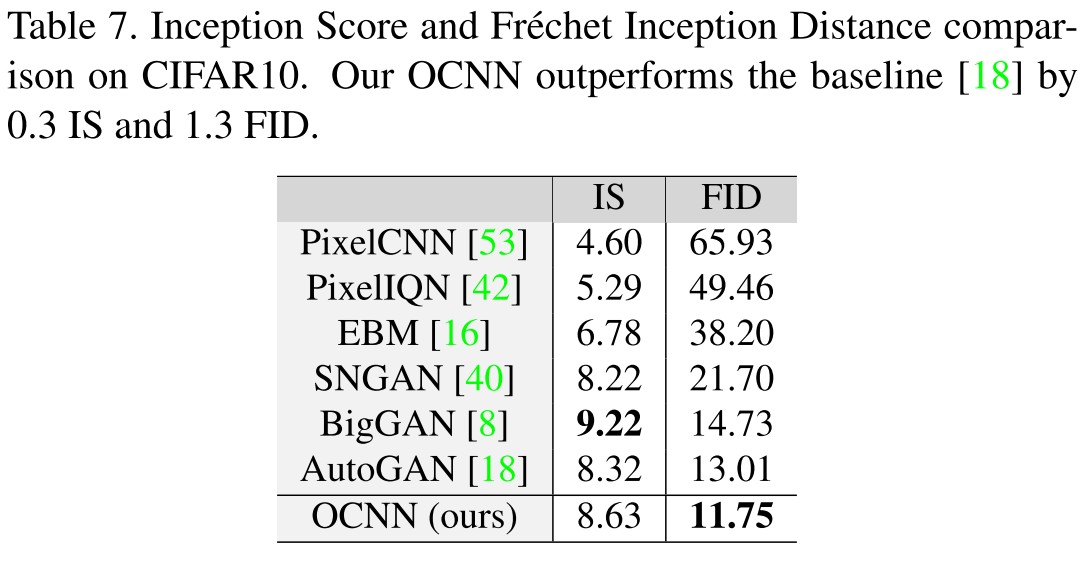
Robustness under Adversarial Attack
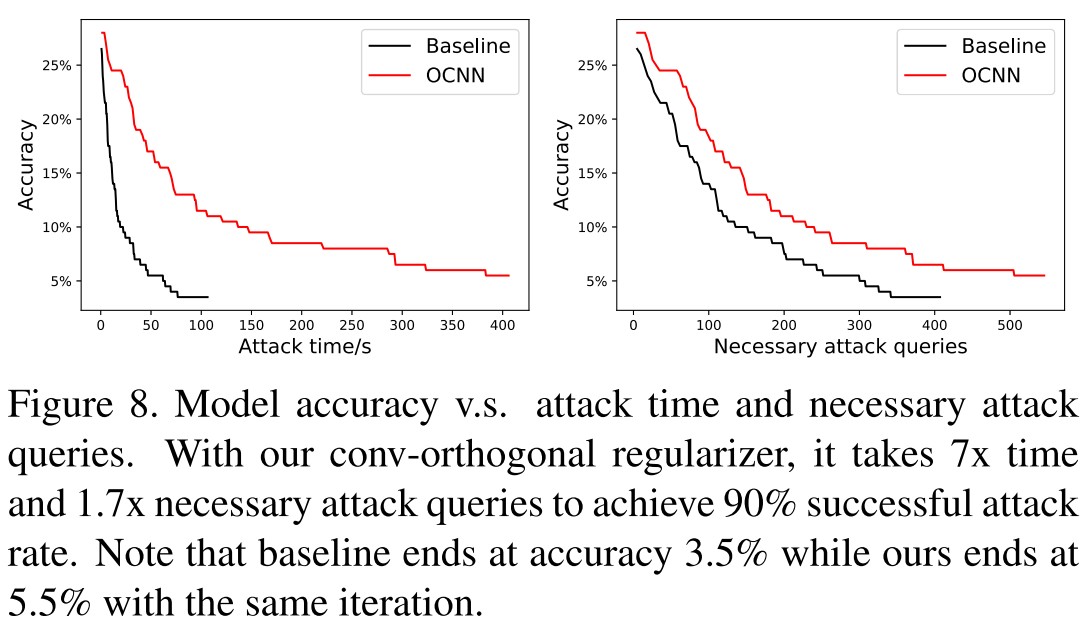

The uniform spectrum of makes each convolution layer approximately an 1-Lipschitz function. Given a small perturbation to input, , the change of output is bounded to be low.
Inspirations
It sounds very natural that a more orthogonal set of kernels captures a more diverse set of features, and a more diverse set of features helps with the performance of models. In another perspective, orthogonal kernels have limited power, i.e. stabler gradients propagated during training, thus a more smooth and stable training is acquired.
However, by restricting strong orthogonality, the transformation done by the linear part of each layer is restricted to rotation in the space, which seems to be a little to restrictive for the model to work at its best.
Since the Lipshitz bound is lowered for each layer, it's rational for it to be more robust to adversarial attacks, but the resistance reported seems not that competitive with adversarial training.