Summarized Survey of Few-shot Learning
By LI Haoyang 2020.10.12 ~ 2020.10.13
This note is summarized from a review, therefore, no quote is specified, most of the following sentences are directly taken from the original article.
Content
Summarized Survey of Few-shot LearningContentFew-shot learning: a surveyProblem definitionRelevant problemsCore issue of FSLTaxonomy of current worksData focused approachesDuplicate training data with transformationsBorrow from other data setsModel focused approachesMultitask learningEmbedding learningLearning with external memoryGenerative modelsAlgorithm focused approachesRefining existing parameters Refining meta-learned Learning search stepsFuture worksInspirations
Few-shot learning: a survey
YAQING WANG, QUANMING YAO. Few-shot Learning: A Survey. 2019. arXiv:1904.05046
Few-short learning aims to improve the model's ability to generalize over training on a small dataset. FSL can learn new task of limited supervised information by incorporating prior knowledge.
Problem definition
Start from the definition of machine learning, which is:
A computer program is said to learn from experience with respect to some classes of task and performance measure if its performance can improve with on measured by . (Machine learning by Mitchell)
FSL is a special case of machine learning, which exactly targets at getting good learning performance with limited supervised information:
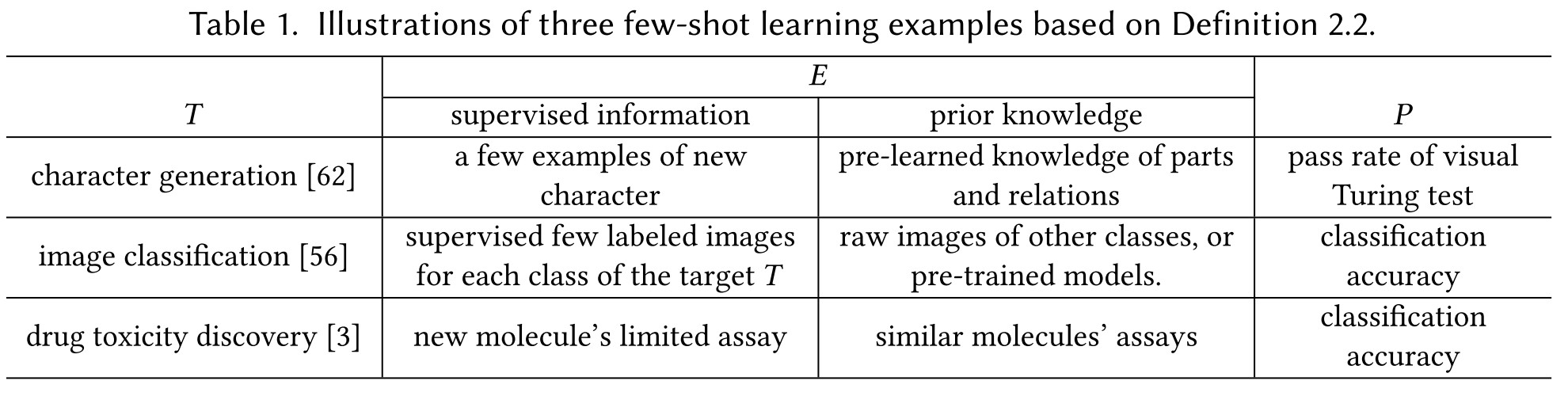
Few-Shot Learning (FSL) is a type of machine learning problems (specified by , and ) where contains little supervised information for the target .
The scenarios of FSL can be summarized as:
- Test bed for human-like learning.
- Few-shot to reduce data gathering effort and computation cost.
- Few-shot due to rare cases. (some tasks are naturally few-shot)
Therefore, FSL methods combine prior knowledge with available supervised information in E to make the learning of the target T feasible
Relevant problems
Semi-supervised learning
It learns the optimal hypothesis from input to output by experience consisting of both labeled and unlabeled examples.
- Positive-unlabeled learning - only positive and unlabeled samples are given
- Active learning - select informative unlabeled data to query an oracle for output
Imbalanced learning
It learns from experience with severely skewed distribution for output .
Transfer learning
It transfers knowledge learned from source domain and source task where sufficient training data is available, to target domain and target task where training data is limited.
- Domain adaptation - where the tasks are the same but the domain is different.
- Zero-shot learning - recognize new class with no supervised training examples by linking them to existing classes that one has already learned. (Cluster?)
Meta-learning
It improves performance on task by data set of the task and the meta knowledge extracted across tasks by a meta-learner.
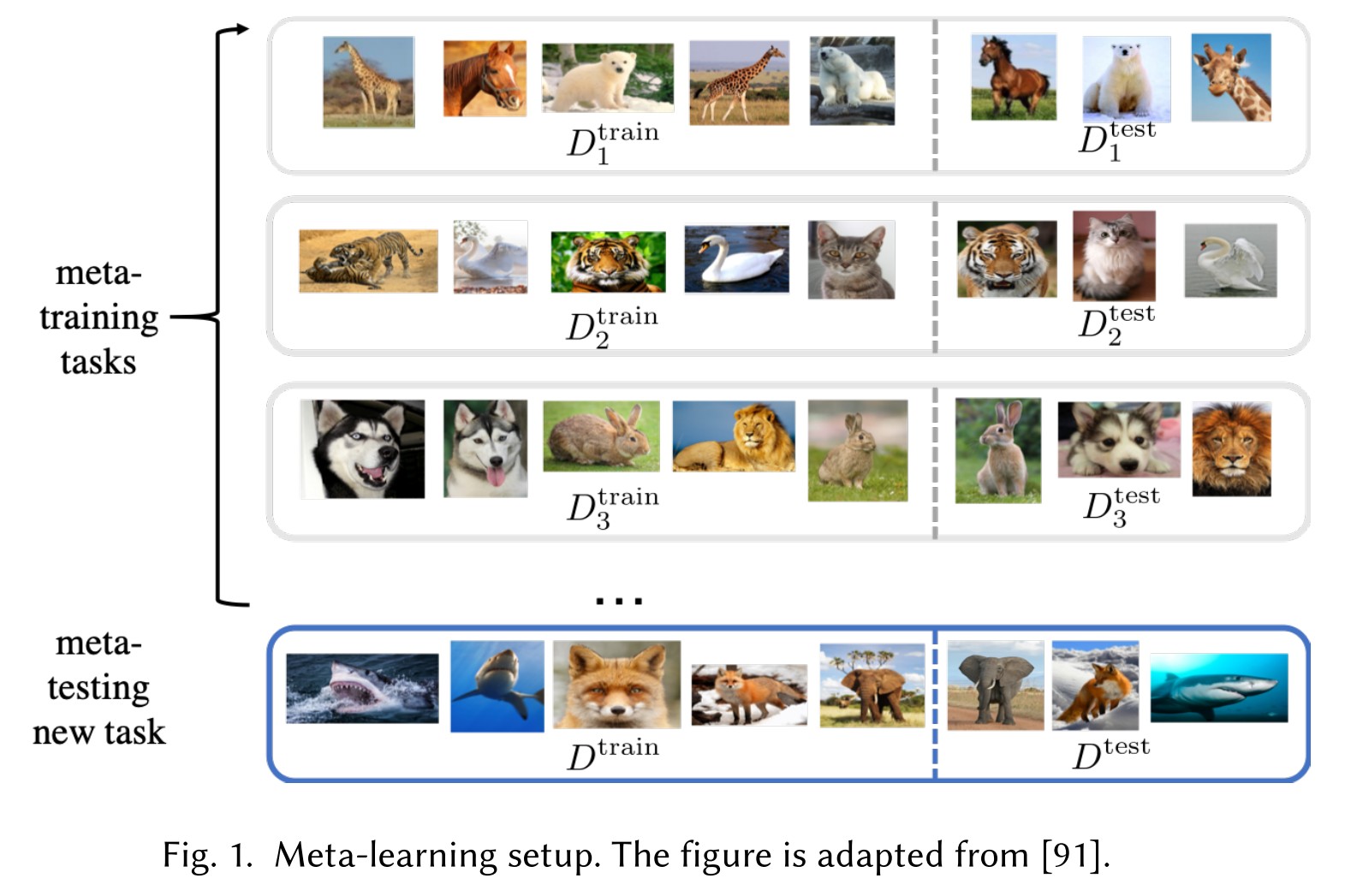
Let be the distribution of task . In meta-learning, it learns from as set of tasks . Each task operates on data set of classes where with and . Each learner learns from and measures test error on . The parameter of meta-learner learns to minimize the error across all learners by:
In meta-testing, another disjoint set of tasks is used to test the generalization ability of meta-learner. Each works on data set of classes where with and . Finally the learner learns from and tests on to obtain the meta-learning testing error.
It appears to me that meta-learning is an ensemble of classifiers trained on partial dataset.
Core issue of FSL
Start from machine learning problem, improving with on measured by , formulated as:
In this form, learning is about algorithm searching in for the which parameterizes the hypothesis chosen by model that best fit data .
Decomposition of error
Let be the prediction of some function for . To solve the problem defined above, the essence is to minimize the expected risk (i.e. losses measured with respect to ), formulated as:
Since is unknown in practice, the empirical risk is used to estimate the expected risk , defined as the average of the sample loss over the training data set:
The learning is done by empirical risk minimization.
In short, empirical risk minimization assumes that every sample in the training set is of the same probability.
Let:
- , the real but unreachable solution
- , the unreachable best solution in
- , the reachable best solution in
The total error of learning taken with respect to the random choice of training set can be decomposed into:
- Approximation error measures how closely functions in can approximate the optimal solution .
- Estimation error/Generalization error measures the effect of minimizing the empirical risk rather than the expected risk .
Given the analysis above, learning to reduce the total error can be attempted from the perspective of data which offers , model which offers and algorithm which searches through for the parameter of the best .
Sample complexity
For , sample complexity is an integer such that for , we have:
In short, sample complexity is the number of samples we need for the estimation error to be small enough.
For infinite space , its complexity can be measured in terms of VapnikâĂŞChervonenkis(VC) dimension, defined as the size of the largest set of inputs that can be shattered (split in all possible ways) by . The sample complexity is tightly bounded as:
The sample complexity increases with more complicated , higher probability that the learned is approximately correct and higher demand of optimization accuracy of algorithm.
Unreliable empirical risk minimizer
For estimation error, we have:
which means more examples can help reduce estimation error. Besides, there is (why?):
Thus in common setting of supervised learning task, empirical risk minimizer can provide a good and stable approximation to the best possible for in .

However, in the setting of few-shot learning where the number of available examples is smaller than the required sample complexity . The empirical minimizer is no longer reliable, which is the core issue in FSL.
Taxonomy of current works
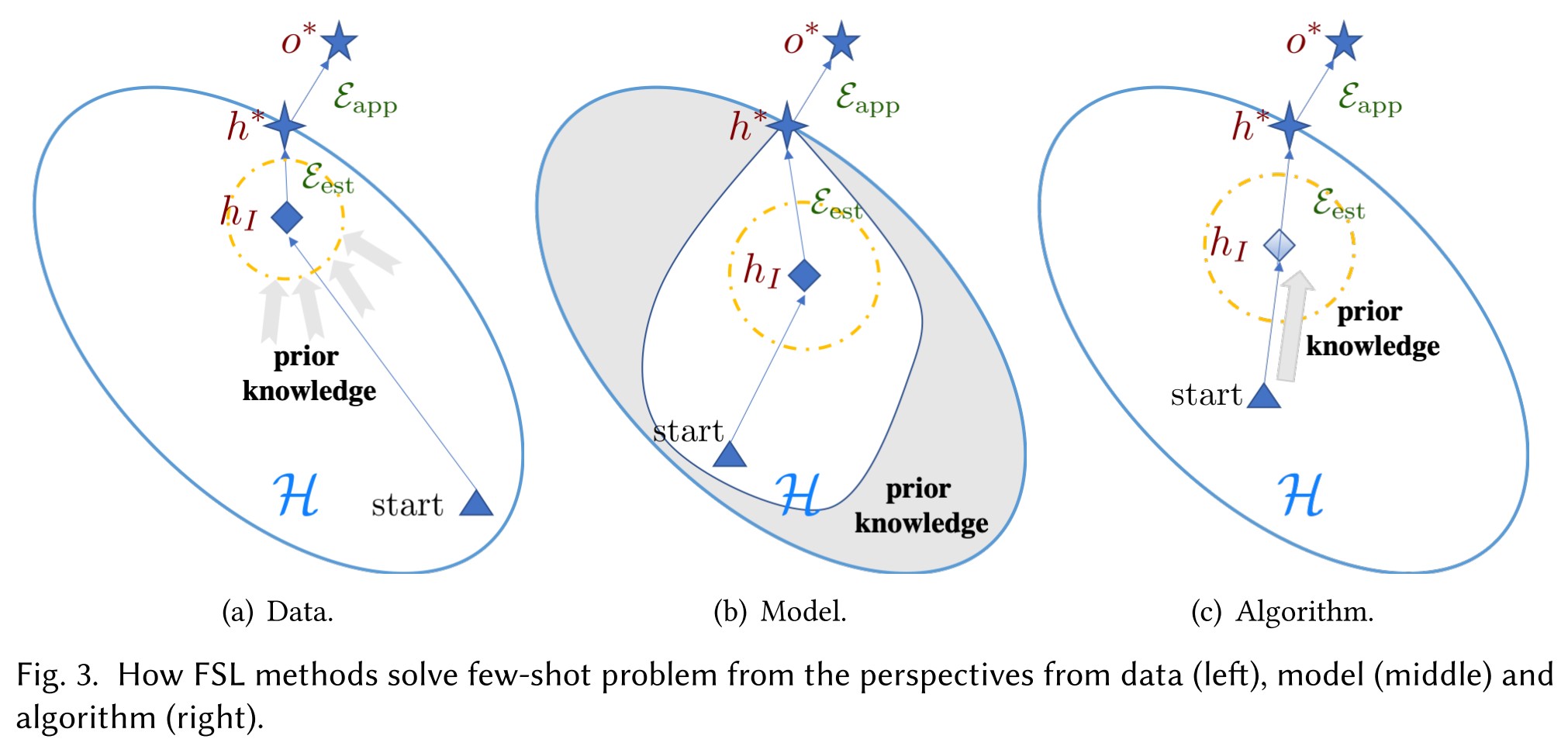
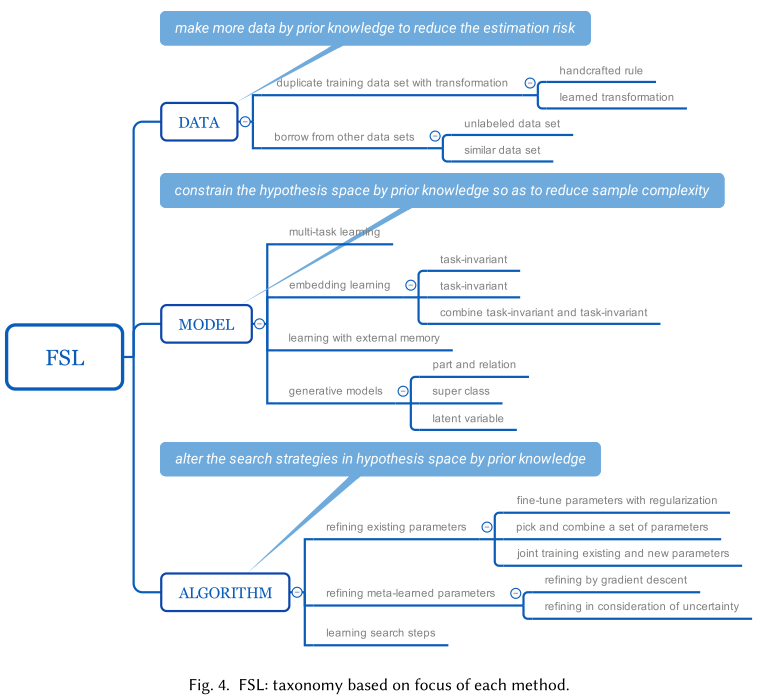
The existing works deal with the problem of unreliable empirical risk minimizer via the following perspectives:
Data
Use prior knowledge to augment .
Model
Design based on prior knowledge in experience to constrain the complexity of and reduce its sample complexity .
Algorithm
Use prior knowledge for better initial point or better search steps. (Meta-learning etc.)
Data focused approaches
Since few-shot suffers from the limited amount of data, the intuitive way to handle it is to augment training set with more data.
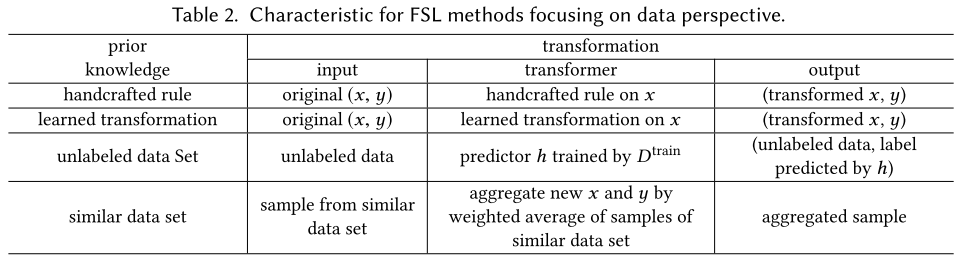
Duplicate training data with transformations
This stratgey augments by duplicating each into several samples with some transformation to bring in variation. These transformations are as follows:
Handcrafted Rule
Translating, flipping, shearing, scaling, reflecting, cropping and rotating,etc.
Learned Transformation
This strategy uses the prior learned transformation to augment .
Direct use of handcrafted rule in FSL without considering the task or desired data property available in can make the estimation of distribution easily go stray. Hence it can only mediate rather than solve FSL problem and is only used as a pre-processing step for image data.
Using learned transformations can augment more suitable samples as it is data-driven and exploit prior knowledge akin to or task . However, this prior knowledge needed to be extracted from similar tasks, which may not always be available and can be costly to collect.
Borrow from other data sets
This strategy borrows samples from other data sets and adapts them to be like sample of the target output, so as to be augmented to the supervised information .
Unlabeled Data Set
This strategy uses a large set of unlabeled samples as prior knowledge, which possibly contains samples of the same label as .
The crux is to find the samples with the same label and add them to augment .
Similar Data Set
This strategy augments by aggregating samples pairs from other similar (in classes) data sets with many-shot.
The underlying assumption is that the underlying hypothesis applies to all classes, and the similarity between of classes can be transferred to of classes. Therefore, new samples can be generated as a weighted average of sample pairs of classes of the similar data set, where the weight is usually some similarity measure.
The use of is cheap but of lower quality.
Similar data set is more informative, but the collecting of it may be laborious and determining the key property of similarity can be objective.
Due to the imprecise prior knowledge guiding the augmentation (lack of ), the generation of new samples is not precise. The gap between the estimated one and the ground truth largely interferes the data quality, even leading to concept drift.
Model focused approaches
Another approach is to constrain the hypothesis space determined by the model as a parameterized hypothesis .
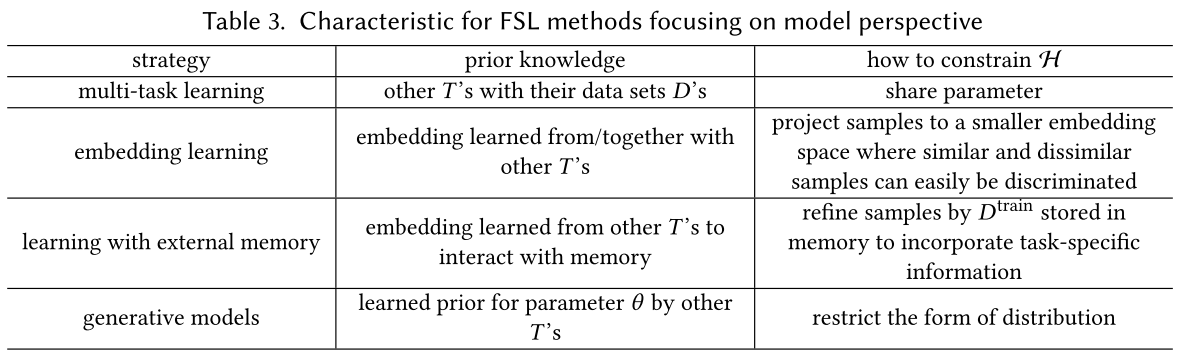
Multitask learning
This strategy learns multiple learning tasks spontaneously, exploit the generic information shared across tasks and specific information of each task. These tasks are usually related.
When the tasks are from different domains, it's also called domain adaptation.
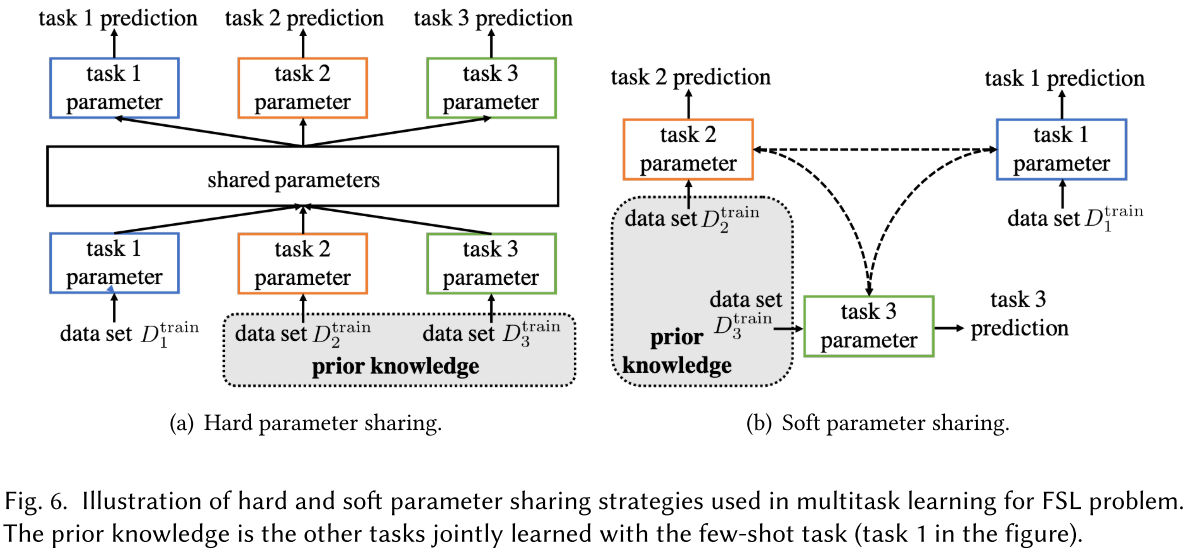
As these tasks are related, they are assumed to ve similar or overlapping hypothesis space , this is done explicitly by sharing parameters among these tasks, which can be viewed as a way to constrain each by other jointly learned tasks.
Hard Parameter Sharing
It explicitly shares parameter among tasks to promote overlapping and additionally learns a task-specific parameter for each task.
It's actually the prevailing methodology in object detection, where the regression head shares the same parameters in deep layers with the classification head.
Soft Parameter Sharing
It only encourages parameters of different tasks to be similar, resulting similar , while each of them still has its own hypothesis space and parameter . This can be done by regularizing .
If the relation between are given, this regularizer can become a graph Laplacian regularizer on the similarity graphs of , then this relations can guide information flow between .
Embedding learning
I think it's also named as metric learning.
This strategy learns a hypothesis space which embeds to a smaller embedding space , where the similar and dissimilar pairs can be easily identified.
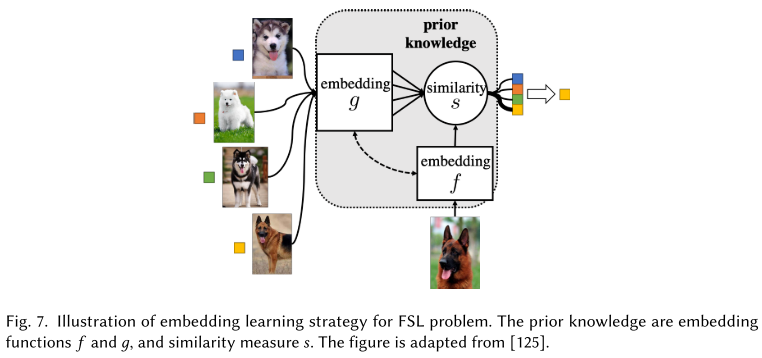
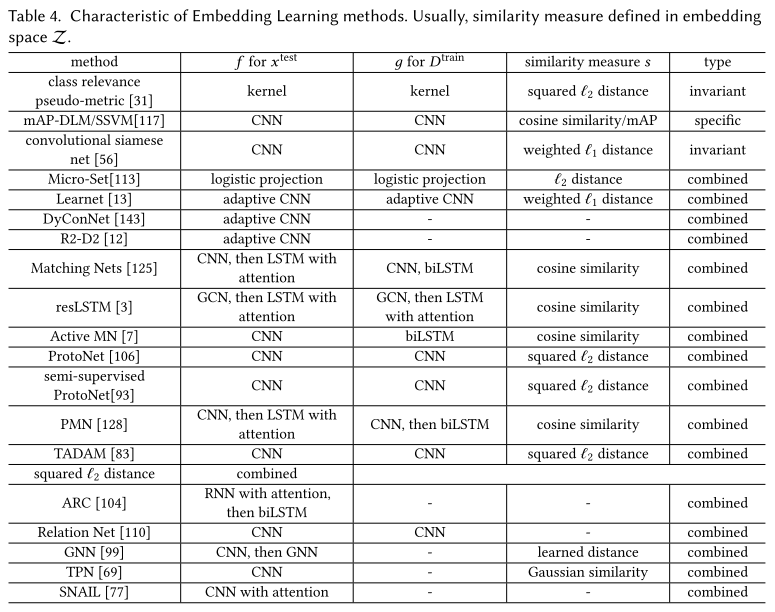
The embedding function is mainly learned by prior knowledge and can additionally uses to bring in task-specific information. The training sample and the testing sample are embedded differently by and . The prediction is then done by assigning to the class of the most similar .
Task-specific
It learns an embedding function tailored to data distribution . Given the few-shot in , the sample complexity is largely reduced by enumerating all pairwise comparison between examples as input pairs. Then a model is learned to verify whether the input pairs have the same or different .
Task-invariant
It learns embedding function from a large set of data sets .The assumption is that if many data sets are well-separated on embedded by , it can be general enough to work well for without retraining.
Combine Task-invariant and Task-specific
It learns to adapt the generic task-invariant embedding space learned from prior knowledge by task-specific information contained in .
This is also the prevailing use of pretrained CNN as feature extractor in literature.
Learning with external memory
This strategy memorizes the needed knowledge in an external memory to be retrieved or updated, hence relieves the burden of learning and allows fast generalization.
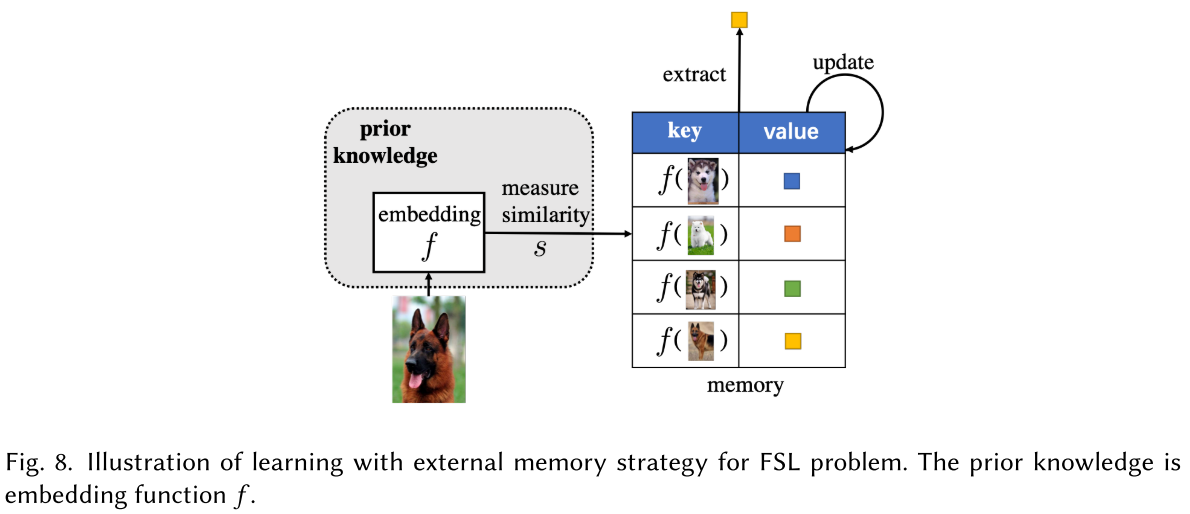

Denote memory as , which has memory slots . Given a sample , it first embedded by as query , then it attends to each through some similarity measure , e.g. cosine similarity, based on which the prediction is then given.
When a new sample comes, relevant contents are extracted from the memory and combined into the local approximation for this sample. The prediction is then made based on the updated approximation.
- Update the least recently used memory slot (e.g. MANN)
- Update by location-based addressing of neural Turing machine (e.g. neural Turing machine)
- Update according to age of memory slots (e.g. Life-long memory)
- Only update the memory when the loss is high
- Use the memory as storage only and wipe it out across tasks (e.g. MetaNet)
- Aggregate the new information into the most similar one (e.g. Memory Matching Networks)
It relies on human knowledge to design a desired rule. The existing works do not have a clear winner. How to design or choose update rules according to different setting automatically are important issues.
It sounds rather traditional to use memory solving the FSL problem.
Generative models
Here, the generative modeling methods refer to methods involve learning . It uses both prior knowledge and to obtain the estimated distribution.
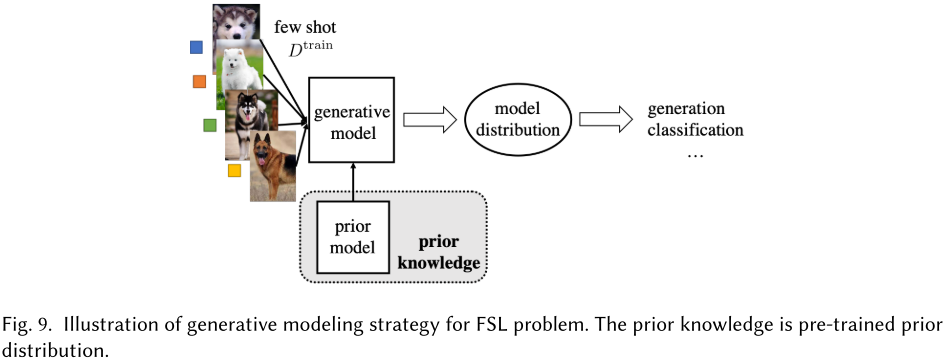
Prior probability distributions of each are learned from a set of data sets , which is usually large and disjoint with , it then updates the probability distribution over for prediction.
By Bayes' rule, we have:
In which, is the parameter of . If is large enough, we can use it to learn a well-peaked , and obtain using:
- Maximum Likelihood Estimation (MLE)
- Maximum a posterior (MAP)
For FSL, generative models assume is transferable across different (e.g. classes). Hence can be instead learned from a large set of data sets .
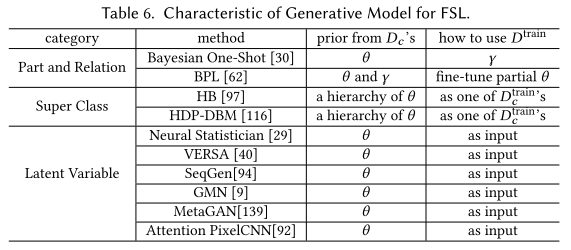
Part and Relation (e.g. Bayesian One-Shot, BPL)
This strategy learns part and relation (a.k.a. ) from a large set of as prior knowledge.
For , the model needs to infer the correct combination of related parts and relations, then decides which target class this combination belongs to.
Super Class (e.g. HB, HDP-DBM)
This strategy clusters similar classes by unsupervised learning, it finds the best which parameterize for these super classes as prior knowledge.
A new class is first assigned to super class, then finds the best through adapting the super class's .
Latent Variable
This strategy models latent variables with no implicit meaning shared across classes.
All methods approaching from model design based on prior knowledge in experience to constrain the complexity of and reduce its sample complexity .
- Multitask learning constrains learned by regularized by a set of tasks jointly learned. When these tasks are highly related, they can guide each other in complement and prevent overfitting problem.
- Embedding learning methods learns to embed samples from to a smaller embedding space, where the similar and dissimilar pairs can be easily identified.
- Learning with external memory refines and re-interprets each sample by stored in memory consequently reshaping .
- Generative model for FSL learns prior probability from prior knowledge, hence shaping the form of . It has good interpretability, causality and compositionality.
Algorithm focused approaches
The so-called algorithm here denotes the strategy to search for the parameter of the best in hypothesis space . The prevailing algorithms for this search root from the gradient descent method:
In which, , measuring the loss incurred by in -th iteration.

The unreliable empirical risk minimizer makes this approach unreliable. The algorithm-centered methods aim to improve the search process for the best by taking advantage of prior knowledge.
Refining existing parameters
This strategy takes from a pre-trained model as a good illustration, and adapts it to by .
It assumes that since captures general structures by learning from large-scale data, it can be adapted using a few iterations to work well on .
Fine-tune with regularization
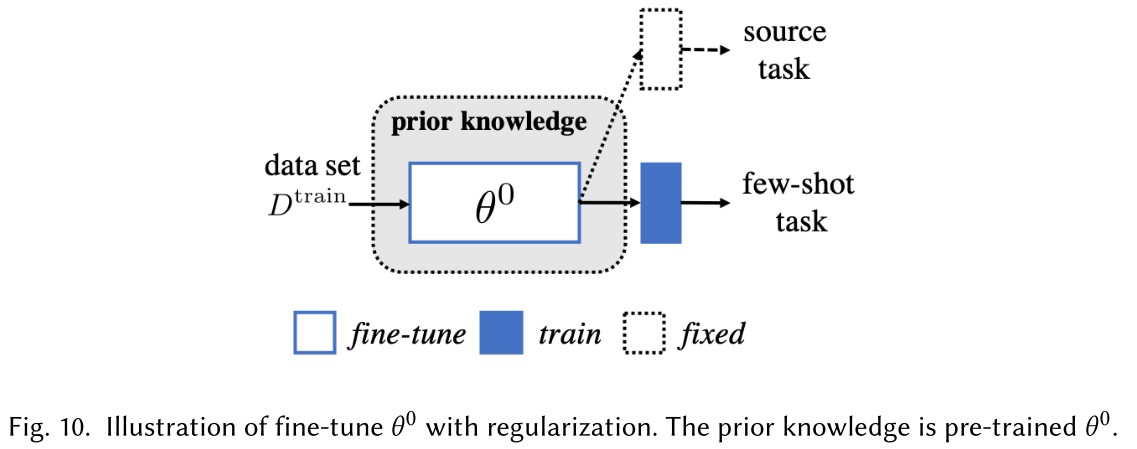
It fine-tunes the pre-trained model to with regularization to prevent overfitting.
Pick and combine a set of
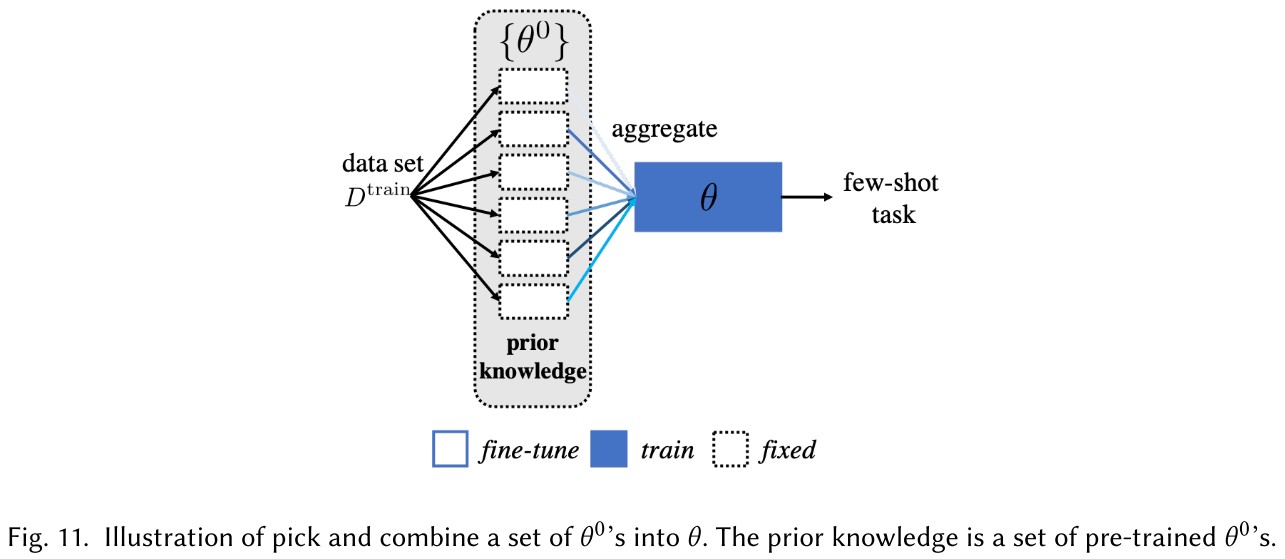
It pick from a set of from models trained for relevant tasks and combine them into the suitable initialization to by adapted by .
Fine-tune with new parameters
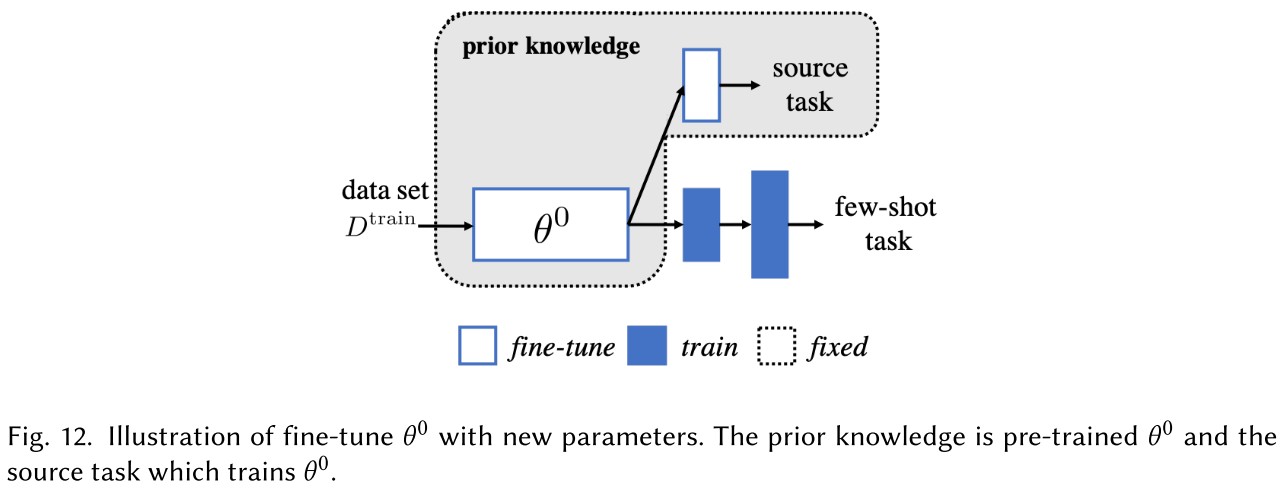
It fine-tunes from the pre-trained model to with extra parameters attached.
Most of these designs are still heuristic, lack of certain interpretability.
Refining meta-learned
This strategy directly targets at .
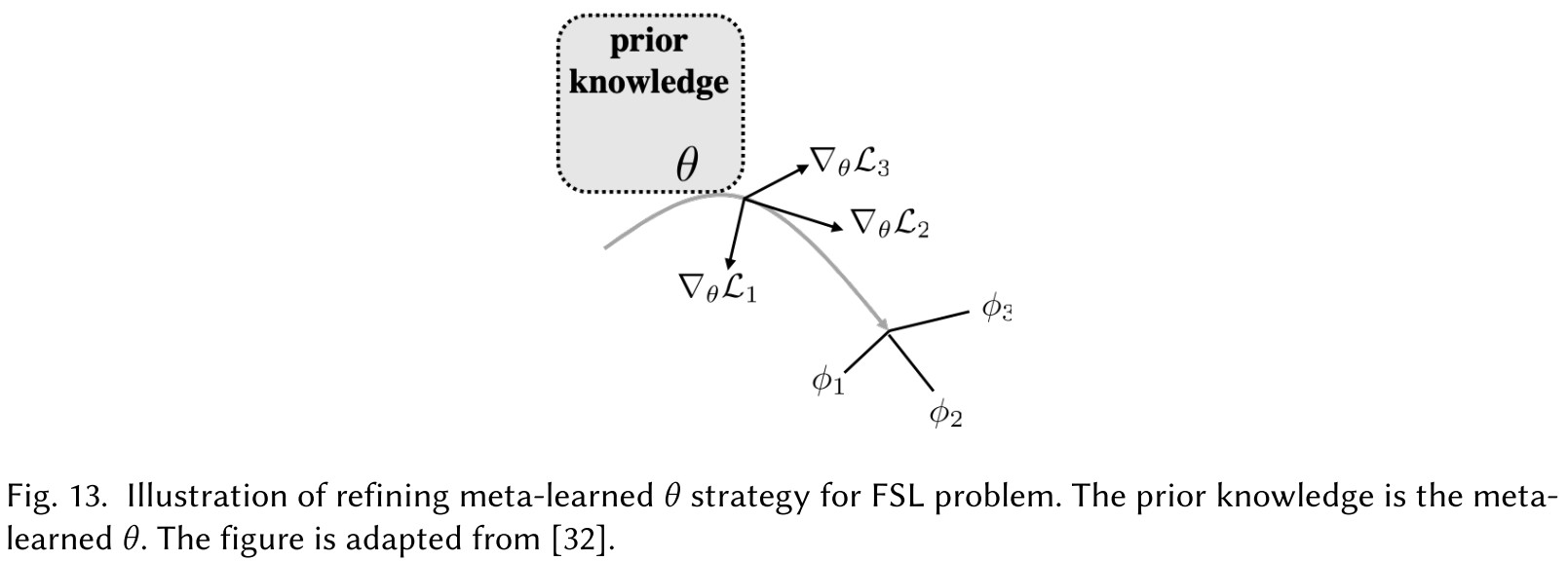
Iteratively, the meta-learner parameterized by provides information about parameter updates to parameter of task 's learner and the learner returns error signals to meta-learner to improve it.
Refining by gradient descent (e.g. MAML)
It simply refines the meta-learned by gradient descent.
Refining in consideration of uncertainty
Basically, it models the distribution of and tries to pick a task-specific based on .
For this approach to work, the tasks over which the meta-learner learns should be related intuitively.
Learning search steps
Its idea is to automatically produce the proper gradient update steps, a good step size, or even a good initialization to start with.
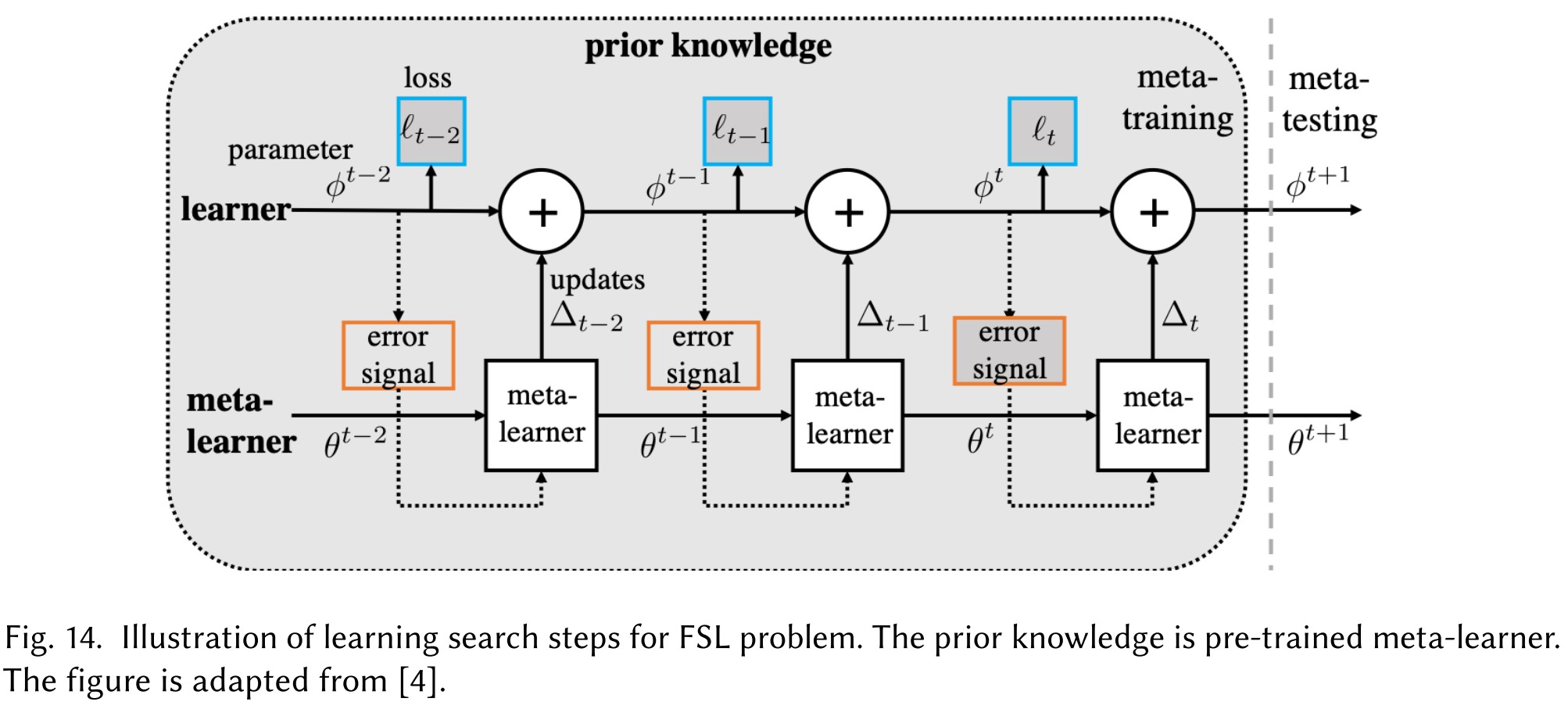
It appears to me as a cooperated training of a meta-learner and a target learner.
All methods focused on algorithm take advantage of prior knowledge to search for the which parameterizes the best .
The former two both aim at a better initialization, the first tries to combine the pre-trained parameters with customized parts and the second utilizes the meta-learner for initialization. The latter one tries to alter the search steps directly based on prior knowledge.
Future works
FSL learning methods attempts to obtain a reliable empirical risk minimizer, from the perspectives of data (Section 3), model (Section 4), and algorithm (Section 5). Each component of these methods can be replaced by more recent and advanced ones.
Inspirations
The key problem of few-shot learning is how to either reduce or reach the required sample complexity due to estimation error introduced by empirical risk minimization under a limited number of samples.
From the perspective of reaching the sample complexity, the direct thought is to augment the training data, so the few-shot then becomes many-shots somehow. These augmentation either constructs new samples from original ones or borrows samples from larger datasets.
From the perspective of reducing the sample complexity, the approach is to constrain parts of the model with pre-trained parameters for a smaller hypothesis space.
From the perspective of avoiding empirical risk minimization, the approach is to adapt a better initialization or alter the search process.
To solve the FSL problem purely based on few-shot datasets is impossible, all of the methods utilize prior knowledge explicitly or implicitly somehow.