About Few-shot Learning
By LI Haoyang 2020.10.13
unfinished
Content
About Few-shot LearningContentDatasetsMiniImageNetCIFAR 100CUBApproachesMatchNet - NIPS 2016ModelTraining strategyN-way K-shot TaskPerformanceInspirationDiversity Transfer Network - AAAI 2020N-way K-shot taskMethodExperiment settingsPerformanceVisualizationAblation study
Datasets
MiniImageNet
Dataset: https://drive.google.com/file/d/1HkgrkAwukzEZA0TpO7010PkAOREb2Nuk/view
CIFAR 100
CUB
Approaches
MatchNet - NIPS 2016
Paper: http://papers.nips.cc/paper/6385-matching-networks-for-one-shot-learning
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, Daan Wierstra. Matching Networks for One Shot Learning. NIPS 2016.
Humans learn new concepts with very little supervision – e.g. a child can generalize the concept of “giraffe” from a single picture in a book – yet our best deep learning systems need hundreds or thousands of examples. This motivates the setting we are interested in: “one-shot” learning, which consists of learning a class from a single labeled example.
In contrast, many non-parametric models allow novel examples to be rapidly assimilated, whilst not suffering from catastrophic forgetting
We aim to incorporate the best characteristics from both parametric and non-parametric models – namely, rapid acquisition of new examples while providing excellent generalization from common examples.
Model
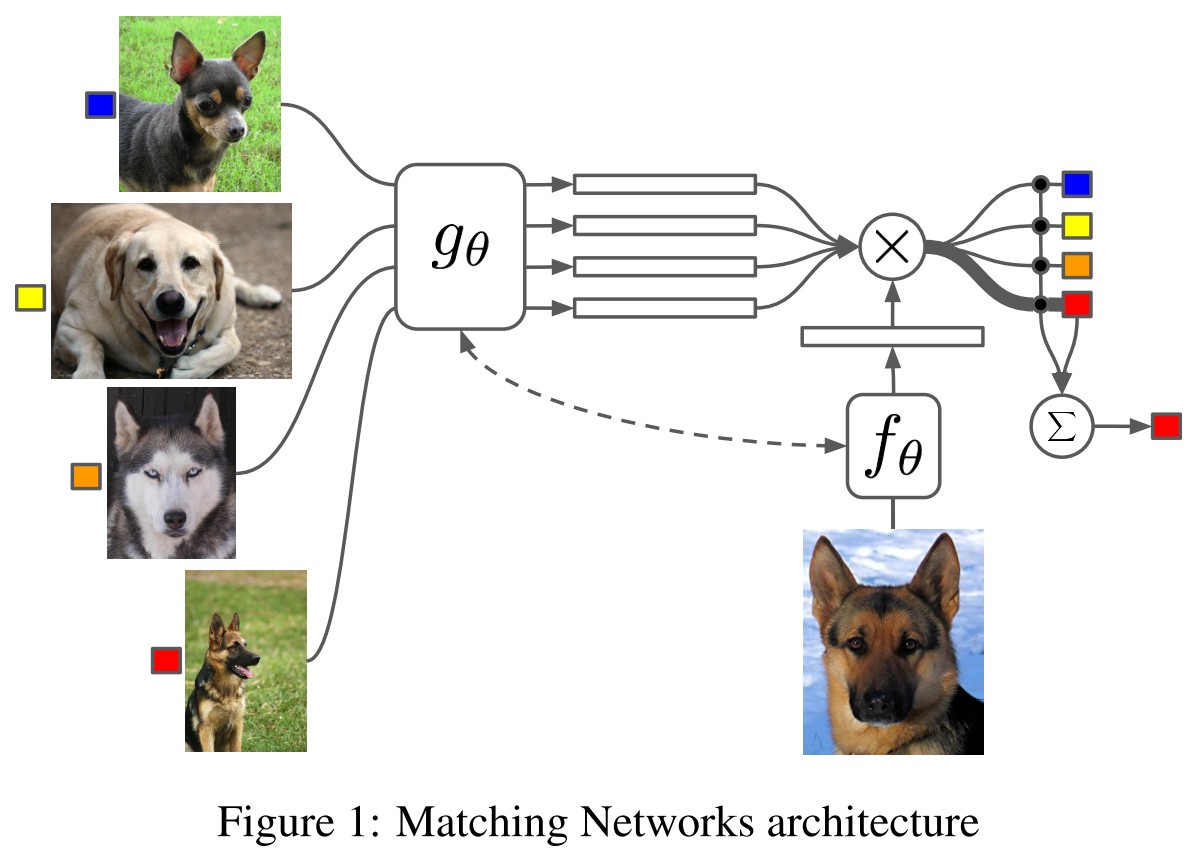
Given a small support set , their model defines a function (or classifier) for each , i.e., a mapping .
They wish to map from a small support set of examples of input-label pairs to a classifier . When a test sample is given to the classifier, it defines a probability distribution over outputs :
When a new support set of examples from which to one-shot learn is given, the parametric neural network defined by can be simply used to make predictions about the appropriate label distribution for each test example :
Perhaps, the here is one-hot coded ?
In which, is an attention mechanism, subsuming both KDE and kNN methods:
- is an kernel kernel density estimator
- is zero for the furthest from 'k-b' nearest neighbor classifier.
In a more casual interpretation, computes the similarity of and .
The simplest form can be a cosine similarity of embedded inputs:
In which, and are embedding functions are neural networks.
In instantiation, they wish the embedding function to learn from the whole support set , the exact instantiation of this model is:
Training strategy
The training process aims to obtain the parameters such that:
In which, a task is defined as a distribution over possible label sets , i.e., a label set is sampled from task ; the batch and support set are sampled from the label set .
The obtained yields a model that works well when sampling from a different distribution of novel labels.
In human words, the inner part aims to obtain a model that performs well in classifying samples from batch based on samples from support set, the outer part aims to make the inner part performs well in various subsets of the entire task set.
N-way K-shot Task
All of our experiments revolve around the same basic task: an N-way k-shot learning task. Each method is providing with a set of k labeled examples from each of N classes that have not previously been trained upon. The task is then to classify a disjoint batch of unlabeled examples into one of these N classes. Thus random performance on this task stands at 1/N.
Performance
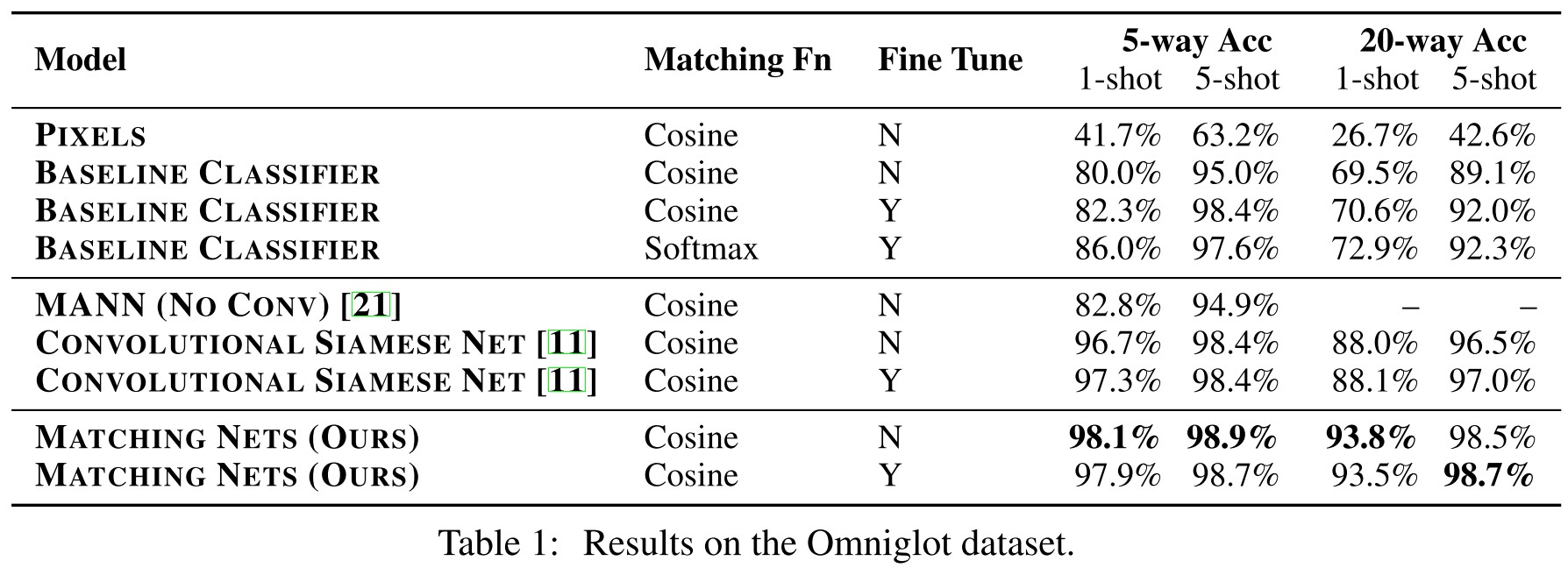
Omniglot [14] consists of 1623 characters from 50 different alphabets. Each of these was hand drawn by 20 different people. The large number of classes (characters) with relatively few data per class (20), makes this an ideal data set for testing small-scale one-shot classification.
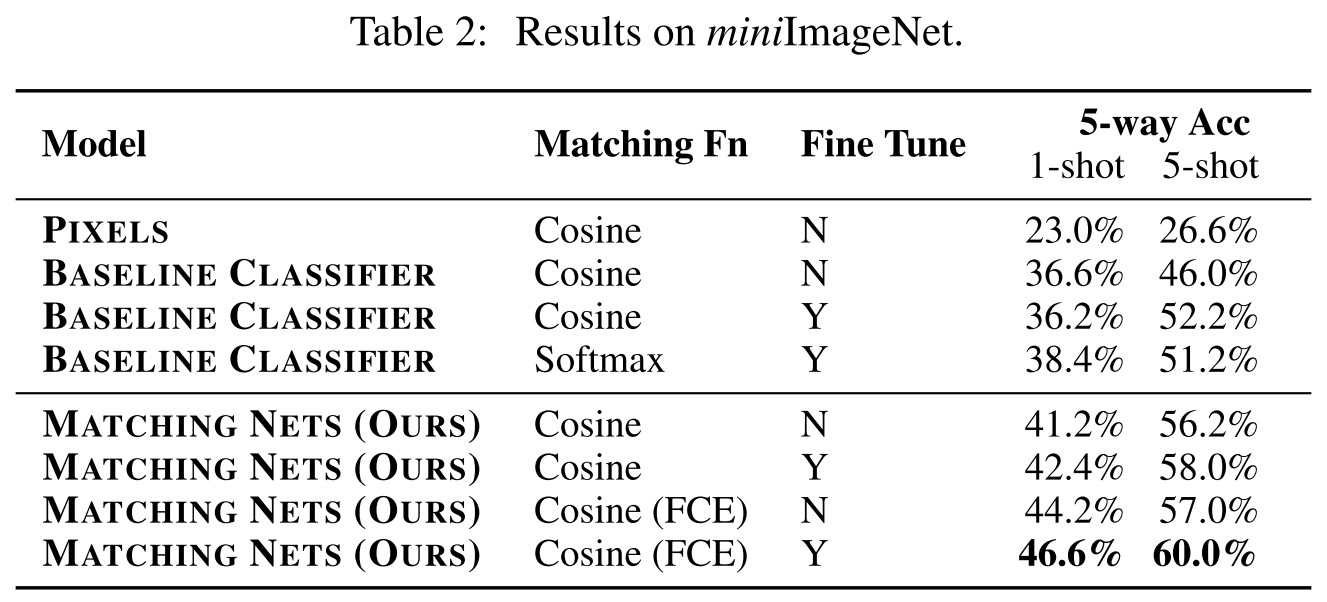
ImageNet is a notoriously large data set which can be quite a feat of engineering and infrastructure to run experiments upon it, requiring many resources. Thus, as well as using the full ImageNet data set, we devised a new data set – miniImageNet – consisting of 60, 000 colour images of size 84 × 84 with 100 classes, each having 600 examples
Inspiration
This paper defines a new challenging and interesting task, i.e. N-way K-shot tasks. They proposed a model to meta-learn the generic metrics between samples and use a kNN-like inference to classify test images.
Diversity Transfer Network - AAAI 2020
Code: https://github.com/Yuxin-CV/DTN
Mengting Chen, Yuxin Fang, Xinggang Wang, Heng Luo, Yifeng Geng, Xinyu Zhang, Chang Huang, Wenyu Liu, Bo Wang. Diversity Transfer Network for Few-Shot Learning. AAAI 2020. arXiv:1912.13182
The idea is to use the diversity of the larger training dataset to augment the few-shot dataset by generating new samples with more diversity.
N-way K-shot task
Given two datasets with disjoint label spaces and , the problem is to take classes, each with images, of samples to form a support set from the training/testing set:
A query sample is then sampled from the rest images of the classes:
The goal is to classify the query into one of the classes correctly based only on the support set and the prior meta-knowledge learned from the training set .
The problem seems to be defined differently from that in MatchNet.
Method
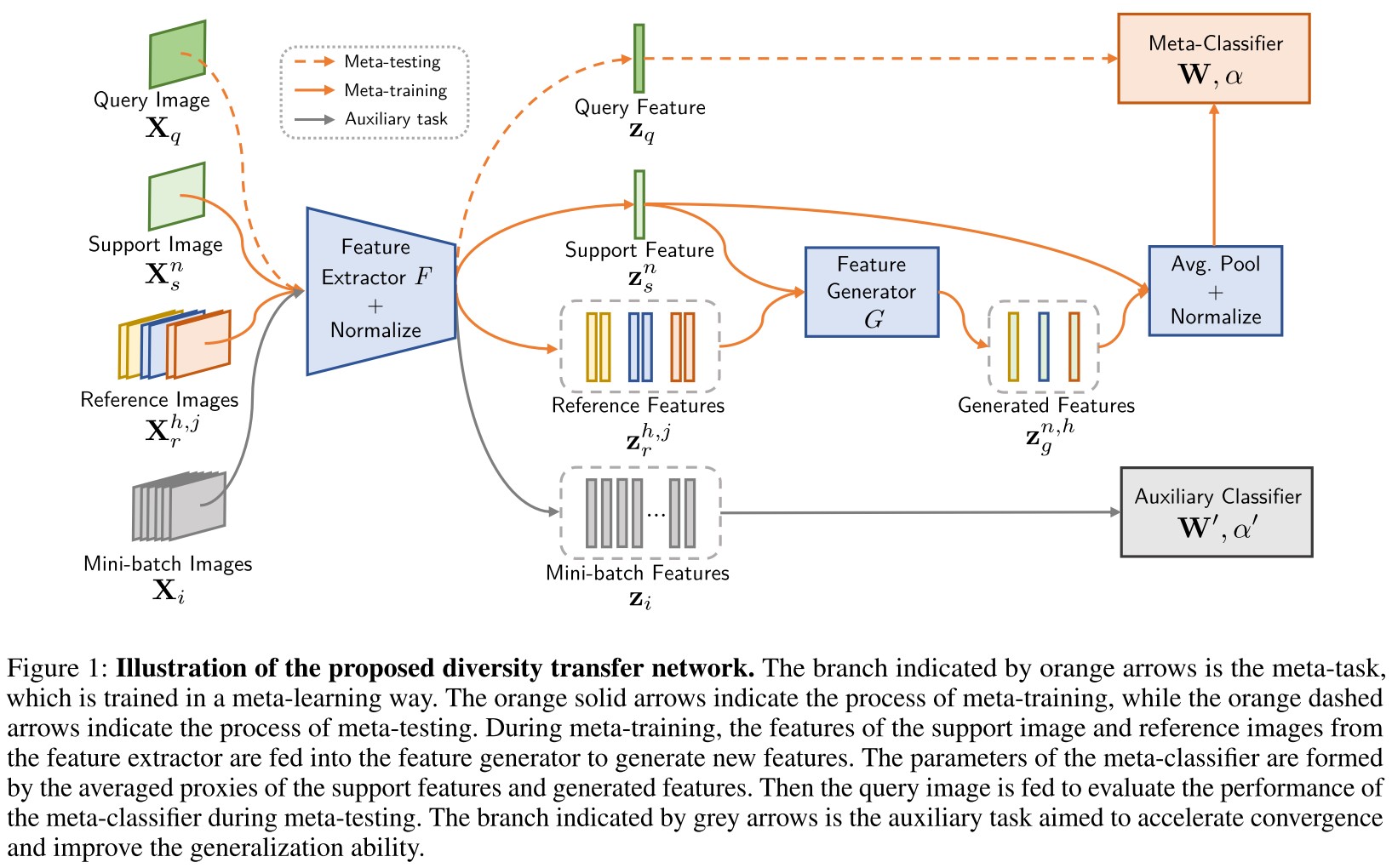
The structure consists of a meta-learning branch and an auxiliary branch.
All of these images are firstly mapped into normalized feature vectors. The diversity between paired reference features , measured by transformed subtraction, are used to augment support features :
For support images, the augmented dataset will have generated samples.
The meta-classifier is an -way classifier, represented by a matrix , in which each row can be viewed as a proxy of the -th category:
It's the normalized center of the cluster of -th category.
The prediction of the fed extracted query feature is:
And during training, the loss of meta-task parameterized with is calculated as:
By minimizing this loss, it increases the cosine similarity between the query feature and corresponding query proxy.
As the proxy is determined by the augmented datasets, does the optimizer solely update in the loss function? It seems to be ditched in inference.
The auxiliary is a meta-classifier trained on mini batches (i.e. ) sampled from , optimized according to the same form of loss function:
In which, and is the -th row of .
The auxiliary branch is designed to accelerate the optimization of feature extractor.
A Organized Auxiliary task co-Training (OAT) strategy is proposed to organize auxiliary branch and meta-learning branch.
They select training epochs to form one training unit , the -th training unit has meta-training epochs () and auxiliary training epochs (). With training units, the whole training sequence is:
In human words, there are steps of training, in each step, there are auxiliary epochs and meta-learning epochs. The whole process is intertwined.
Experiment settings
Three datasets, miniImageNet, CIFAR100 and CUB, are used for evaluation.
The feature extractor for DTN is a CNN with 4 convolutional modules, each of which contains a convolutional layer with 64 channells followed by a batch normalization layer, a ReLU non-linearity layer and a max-pooling layer. The output is a feature vector of 1024 dimensions.
The mapping function is a fully-connected layer with 2048 units followed by a leaky ReLU activation (max(x,0.2x)) layer and a dropout layer with 30% dropout rate.
The mapping function has the same settings with except that the number of units of the FC layer is 1024.
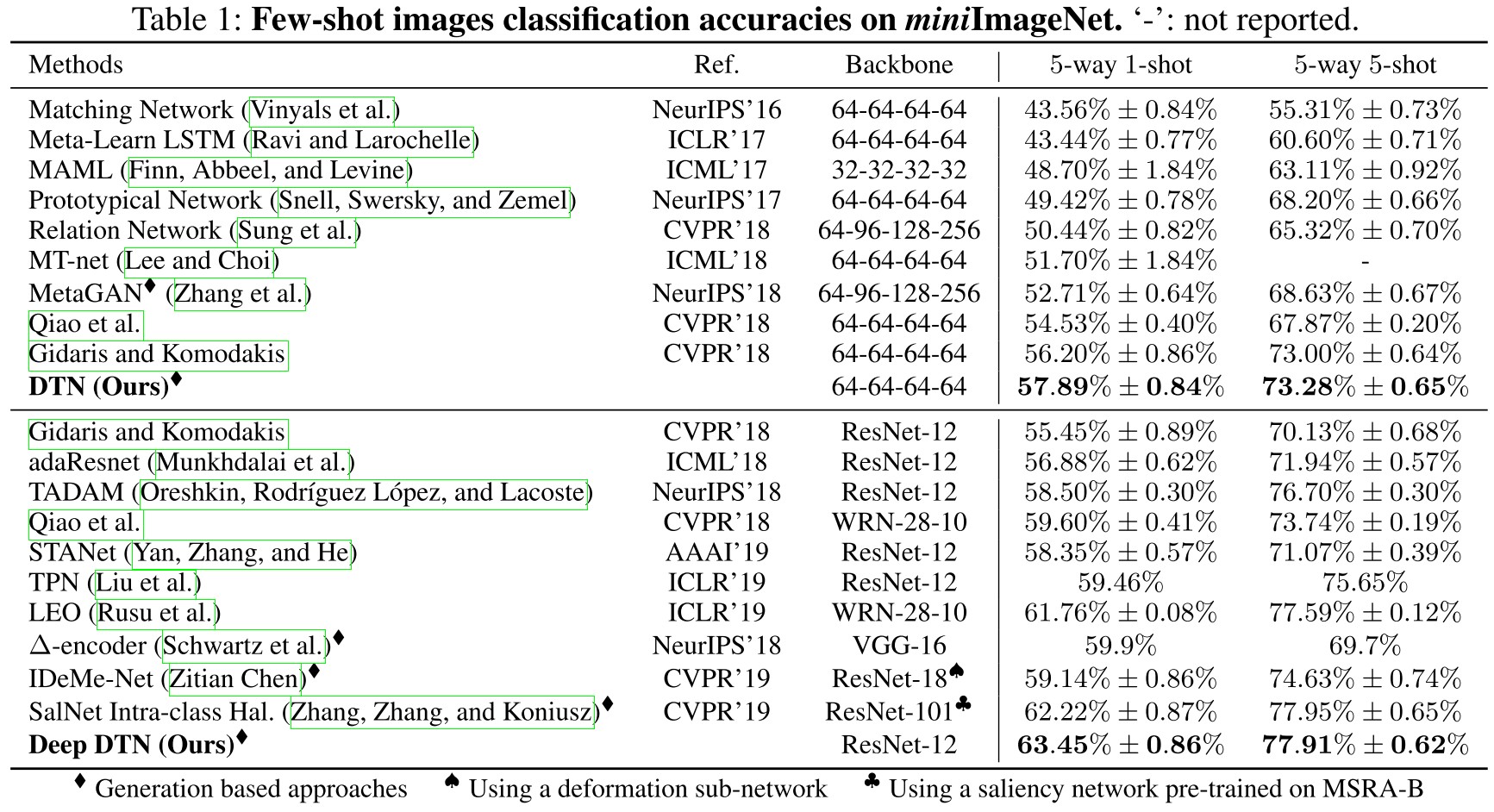
Performance

Visualization
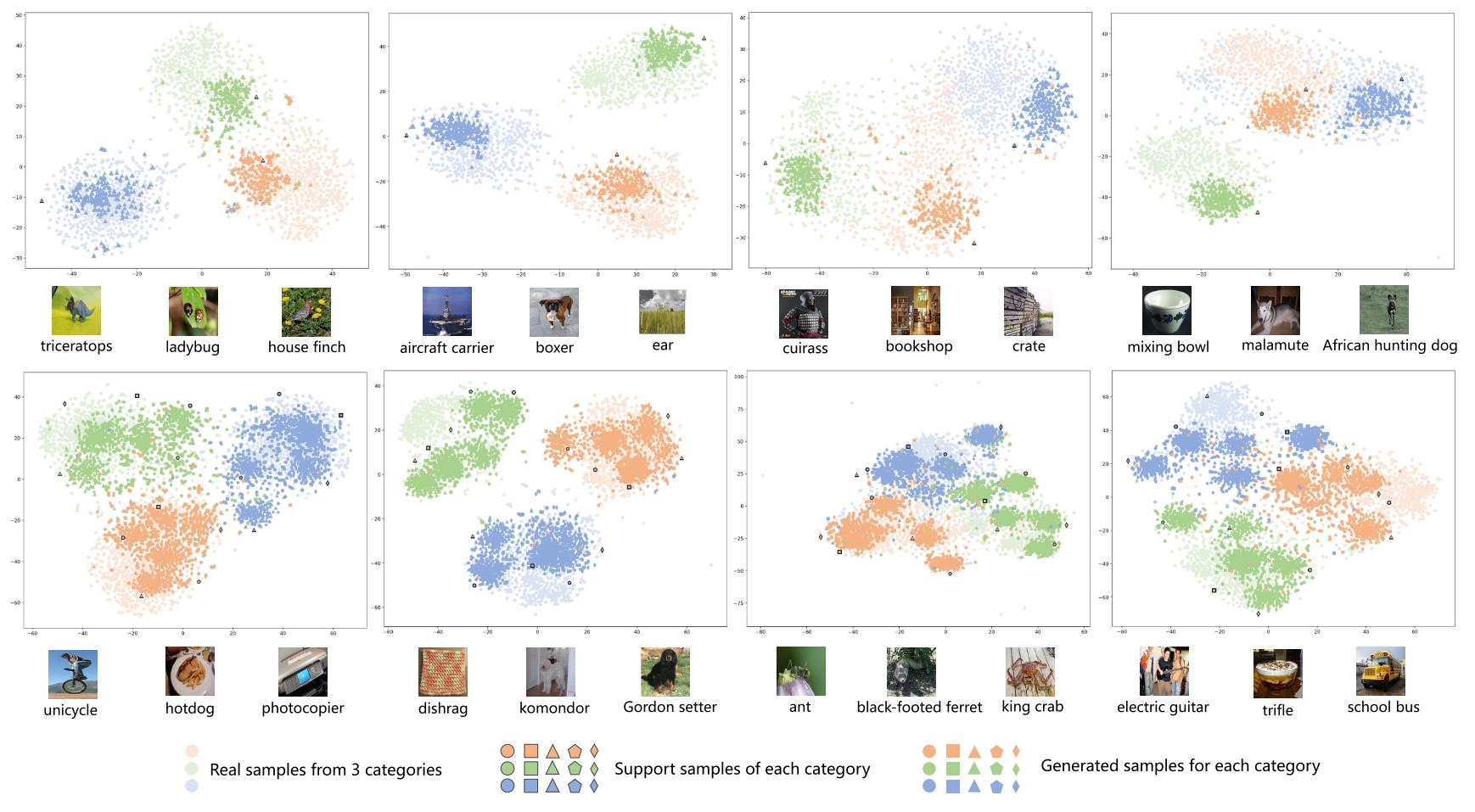
As shown above, the generated samples are roughly clustered in the cloud of real samples of a larger dataset, which indicates the effectiveness of the proposed augmentation.
Ablation study
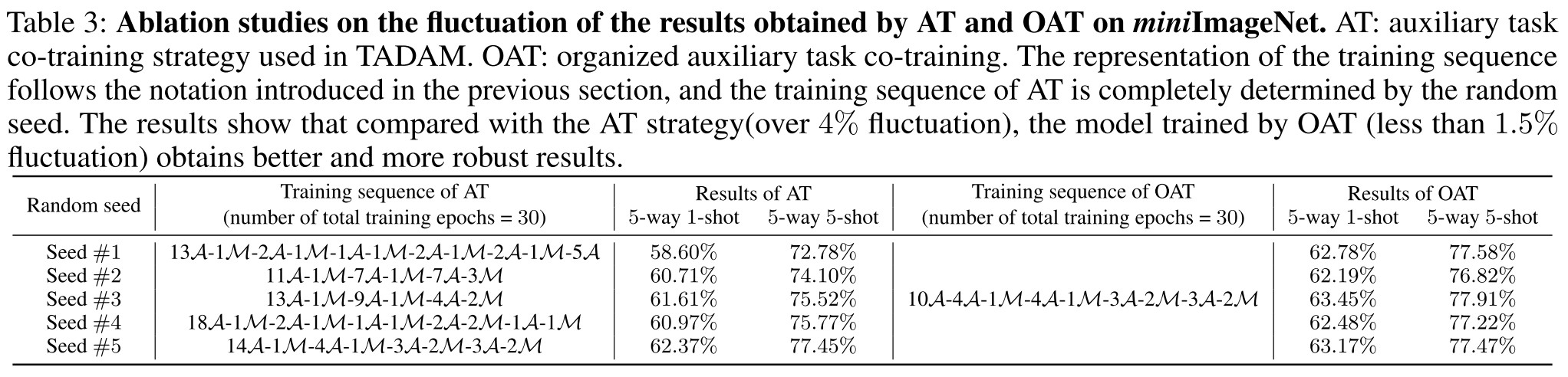
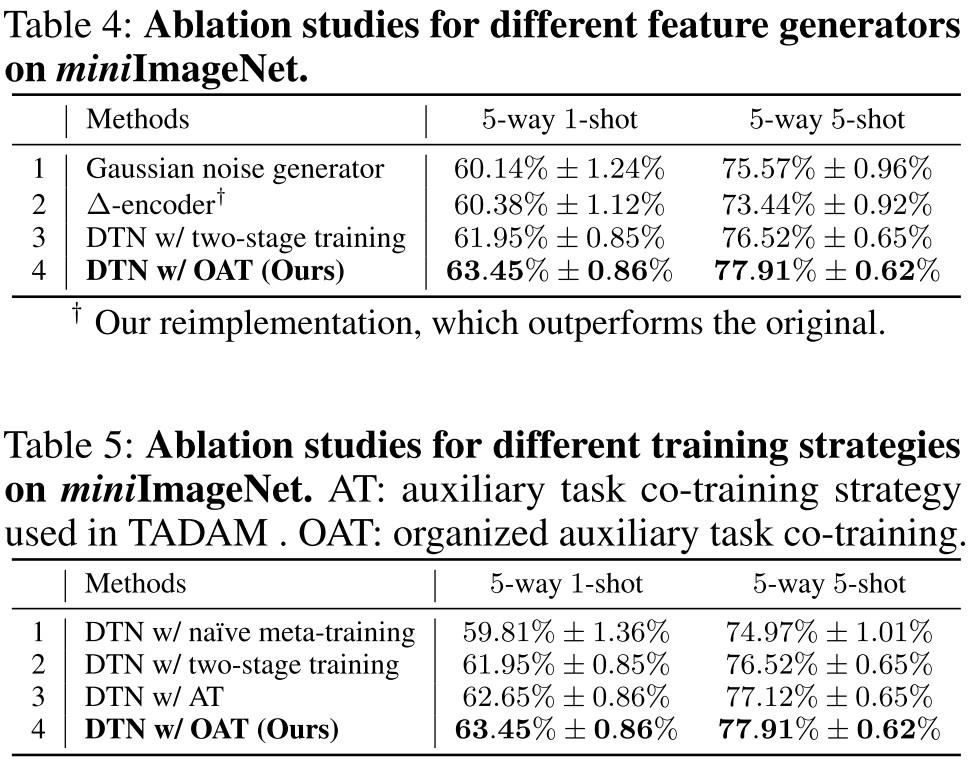
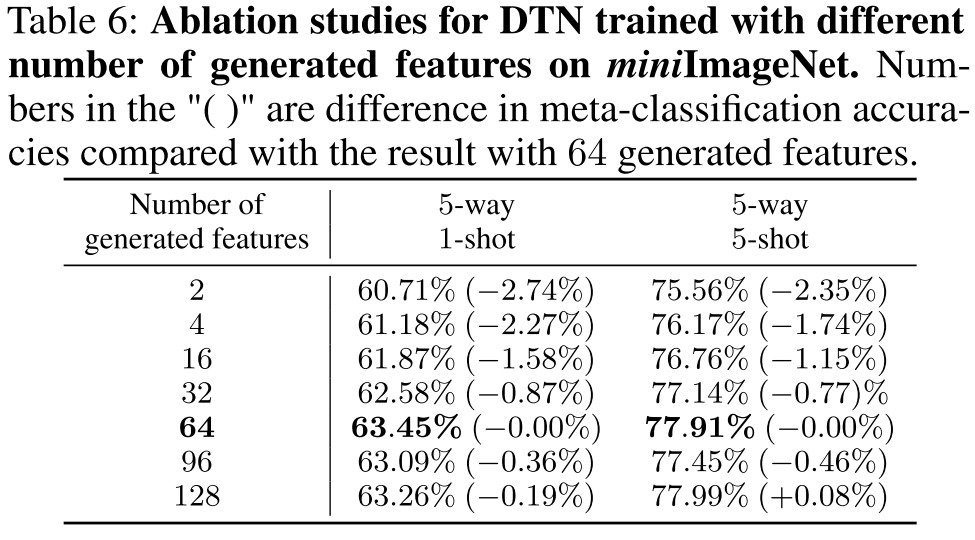
The results gradually become better as the number of generated features increases. No improvement was observed when the number of generated features exceeds 64. We attribute this to the fact that 64 generated features have been well fitted to the real sample distribution.