Adversarial and Generative
By LI Haoyang 2020.12.7
Content
Adversarial and Generative ContentAdversarial Example for Generative PurposeImage Synthesis with a Single (Robust) Classifier - 2019ApproachRealistic Image GenerationImage InpaintingImage-to-Image TranslationSuper-ResolutionInteractive Image ManipulationSketch-to-imageFeature PaintingInspirationsAdversarial Robustness as a Prior for Learned Representations - 2019Limitations of Standard RepresentationsProperties and Applications of Robust RepresentationsRobust representations are (approximately) invertible out of the boxRepresentation proximity seems to entail semantic similarityInversion of out-of-distribution inputsInterpolation between arbitrary inputsDirect feature visualizationInspirationGenerative Approach for Adversarial RobustnessAnalysis by Synthesis (a Bayesian Classifier for MNIST) - 2018Analysis by SynthesisTight estimate of the lower bound for adversarial examplesExperimentsInspirations
Adversarial Example for Generative Purpose
Image Synthesis with a Single (Robust) Classifier - 2019
Code: https://git.io/robust-apps
Shibani Santurkar, Dimitris Tsipras, Brandon Tran, Andrew Ilyas, Logan Engstrom, Aleksander Madry. Image Synthesis with a Single (Robust) Classifier. arXiv preprint 2019 arXiv:1906.09453
This paper demonstrates the possibility of using a adversarially trained classifier to turn adversarial examples into semantically meaningful synthesis of images.
In contrast to other state-of-the-art approaches, the toolkit we develop is rather minimal: it uses a single, off-the-shelf classifier for all these tasks. The crux of our approach is that we train this classifier to be adversarially robust.
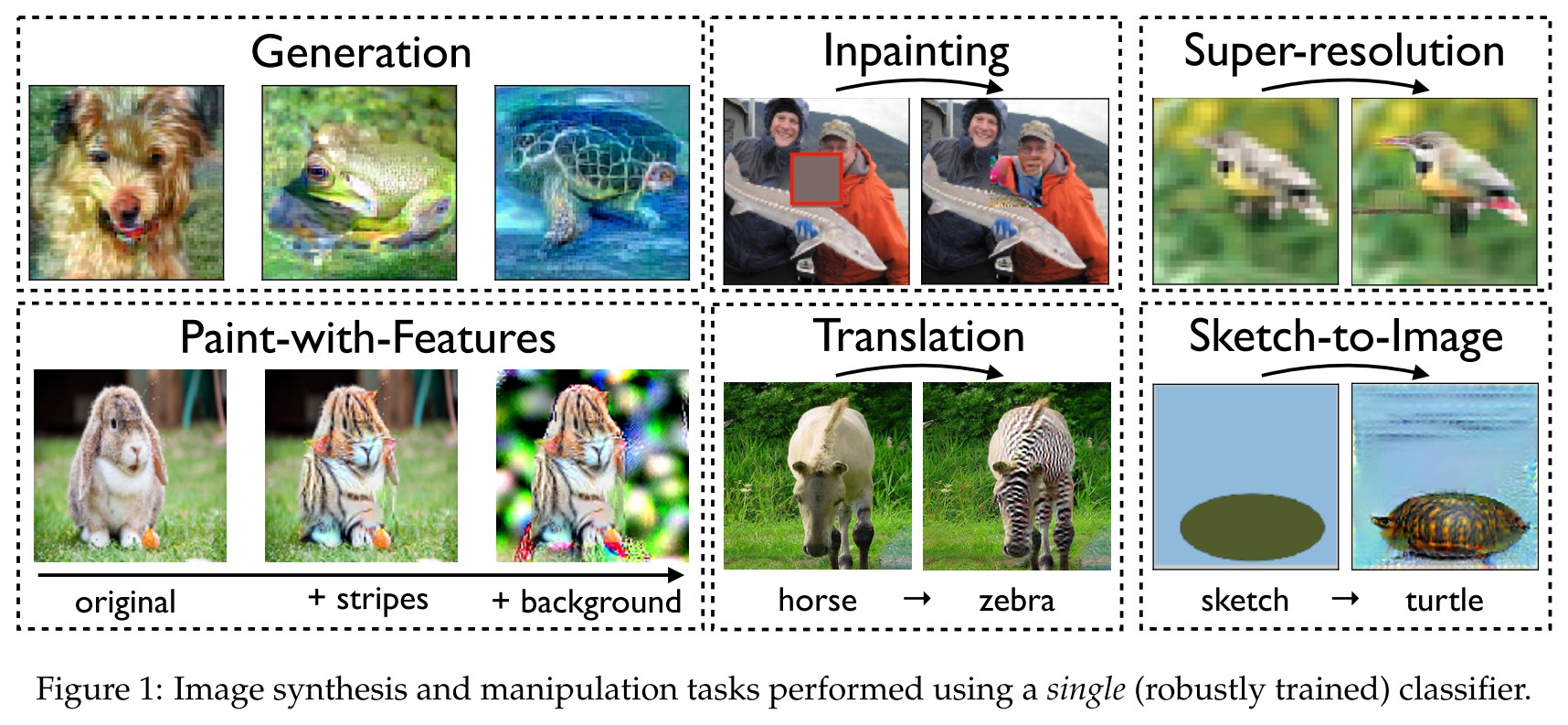
In this work, we demonstrate that basic classification tools alone suffice to tackle various image synthesis tasks. These tasks include (cf. Figure 1):
- generation (Section 3.1)
- inpainting (Section 3.2)
- image-to-image translation (Section 3.3)
- super-resolution (Section 3.4)
- interactive image manipulation (Section 3.5).
It's surprising but expected, since the gradient captures semantic information, the classifier should be able to tackle semantic manipulating tasks.
Approach

Our approach is remarkably simple: all the applications are performed using gradient ascent on class scores derived from the same robustly trained classifier.
Basically, they conduct an adversarial attack on an adversarially trained classifier, i.e. classifier trained using the robust optimization objective:
where the captures imperceptible changes.
This process can be viewed as encoding priors into the model, preventing it from relying on imperceptible features of the input.
Indeed, the findings of Tsipras et al. [Tsi+19] are aligned with this viewpoint—by encouraging the model to be invariant to small perturbations, robust training ensures that changes in the model’s predictions correspond to salient input changes.
it turns out that this phenomenon also emerges when we maximize the probability of a specific class (targeted attacks) for a robust model.
Realistic Image Generation

The purpose of realistic image generation is:
Given a set of example inputs, we would like to learn a model that can produce novel perceptually-plausible inputs.
Many of these methods, however, can be tricky to train and properly tune. They are also fairly computationally intensive, and often require fine-grained performance optimizations.
In contrast, we demonstrate that robust classifiers, without any special training or auxiliary networks, can be a powerful tool for synthesizing realistic natural images.
To generate a sample of class , they sample a seed and minimize the loss of label , i.e.
where is some class-conditional seed distribution.
Here they use a simple choice of this seed distribution, a multivariate normal distribution, i.e.
where is the distribution of natural inputs conditioned on the label .
Image Inpainting


Image inpainting is the task of recovering images with large corrupted regions.
Given an image , corrupted in a region corresponding to a binary mask , the goal of inpainting is to recover the missing pixels in a manner that is perceptually plausible with respect to the rest of the image.
For this purpose, they optimize the image to maximize the score of the underlying true class, while also forcing it to be consistent with the original in the uncorrupted region, i.e.
where is the cross-entropy loss, denotes the element-wise multiplication and is an appropriately chosen constant.
Interestingly, even when this approach fails (reconstructions differ from the original), the resulting images do tend to be perceptually plausible to a human, as shown in Appendix Figure 12.
Image-to-Image Translation

The goal of image-to-image translation is to translate an image from a source to a target domain in a semantic manner.
The key is to (robustly) train a classifier to distinguish between the source and target domain. Conceptually, such a classifier will extract salient characteristics of each domain in order to make accurate predictions. We can then translate an input from the source domain by directly maximizing the predicted score of the target domain.
For overly simple tasks, models might extract little salient information (e.g., by relying on backgrounds instead of objects4) in which case our approach would not lead to meaningful translations.
In contrast, our method operates in the unpaired setting, where samples from the source and target domain are provided without an explicit pairing.
A robust discriminator can replace the generator, aha!
Super-Resolution

Super-resolution refers to the task of recovering high-resolution images given their low resolution version. While this goal is underspecified, our aim is to produce a high-resolution image that is consistent with the input and plausible to a human.
They cast super-resolution as the task of accentuating the salient features of low-resolution images, achieved by maximizing the score predicted by a robust classifier trained on the original high-resolution dataset for the underlying classes.
To ensure the structure and high-level content is preserved, they also penalize large deviations from the original low-resolution image. The problem solved here is formulated as
where denotes the up-sampling operation based on nearest neighbors.
In general, our approach produces highresolution samples that are substantially sharper, particularly in regions of the image that contain salient class information.
Interactive Image Manipulation
Sketch-to-image

Recent work has explored building deep learning–based interactive tools for image synthesis and manipulation. For example, GANs have been used to transform simple sketches [CH18; Par+19] into realistic images.
By performing PGD to maximize the probability of a chosen target class, we can use robust models to convert hand-drawn sketches to natural images.
Feature Painting

Generative model–based paint applications often allow the user to control more fine-grained features, as opposed to just the overall class. We now show that we can perform similar feature manipulation through a minor modification to our basic primitive of class score maximization.
Given an image , to add a single feature corresponding to component of the representation vector in the region corresponding to a binary mask , they simply apply PGD to solve
Change the designated region to maximize the designated feature while keep the rest of the image untouched.
Inspirations
More broadly, our findings suggest that adversarial robustness might be a property that is desirable beyond security and reliability contexts. Robustness may, in fact, offer a path towards building a more human-aligned machine learning toolkit.
They demonstrate the possibility of using discriminative models to do generative tasks. It will be a promising future, if the computational expense of getting a robust classifier is reduced.
Adversarial Robustness as a Prior for Learned Representations - 2019
Code: https://git.io/robust-reps
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Brandon Tran, Aleksander Madry. Adversarial Robustness as a Prior for Learned Representations. arXiv preprint 2019. arXiv:1906.00945
In particular, these representations are approximately invertible, while allowing for direct visualization and manipulation of salient input features.
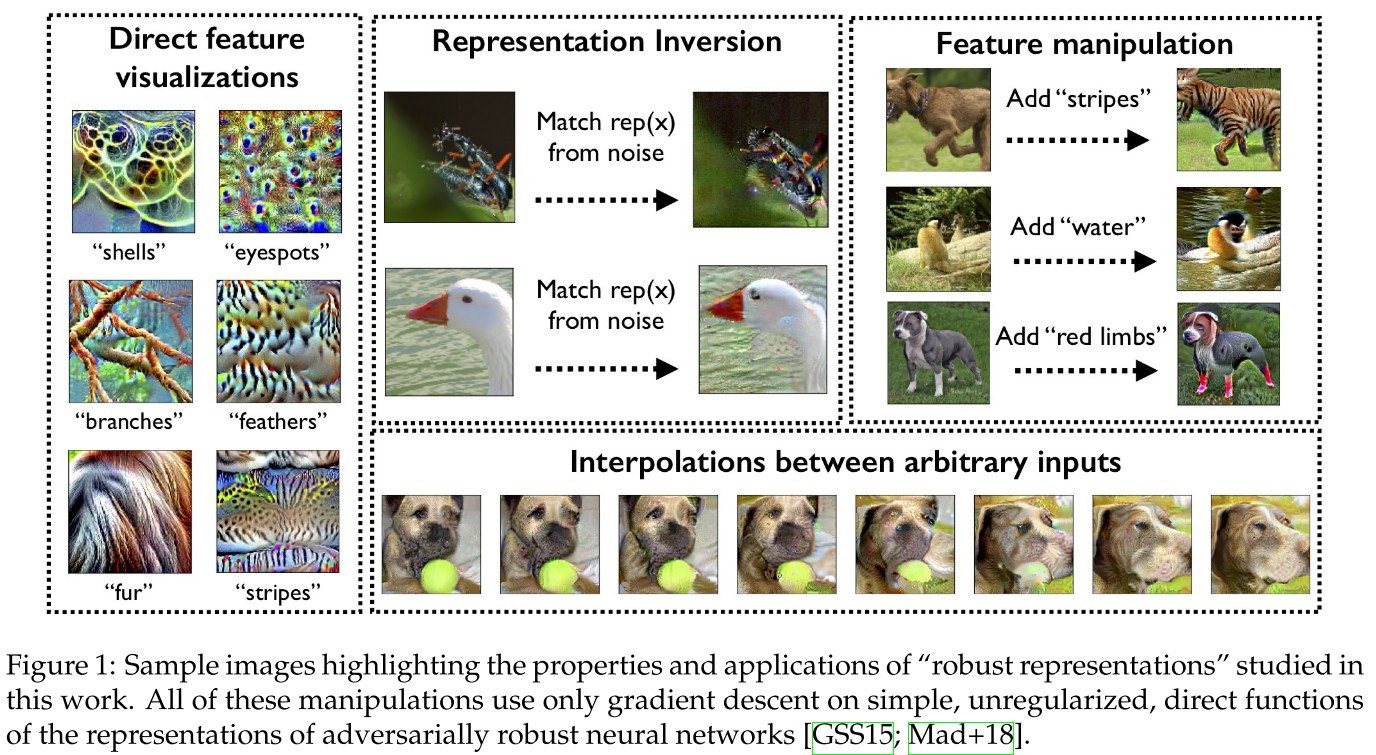
They propose to use the robust optimization framework as a tool to enforce (user-specified) priors on features that models should learn.
They demonstrate that the resulting learned "robust representations" address many of the shortcomings affecting standard learned representations.
Their findings include:
- Representation inversion : Robust representations are approximately invertible. This property also naturally enables feature interpolation between arbitrary inputs.
- Simple feature visualization: Direct maximization of the coordinates of robust representations suffices to visualize easily recognizable features of the model.
- Feature manipulation: Through the aforementioned direct feature visualization property, robust representations enable the addition of specific features to images through direct first-order optimization.
Limitations of Standard Representations
The representation of a given input is defined as the activations of the penultimate layer of the network (where usually ).
The prediction of the network can be viewed as the output of a linear classifier on the representation .
They refer the distance in representation space between two inputs as the distance between their representations , i.e. .
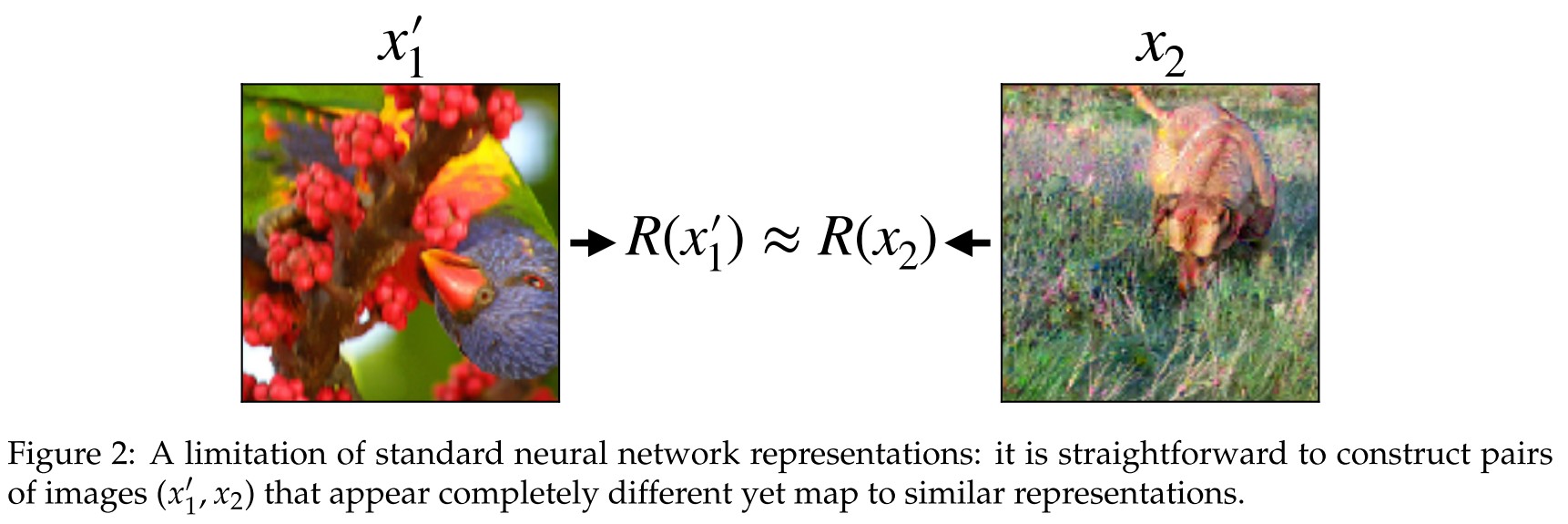
They find that it's straightforward to construct pairs of images with nearly identical representations yet drastically different content as shown in Figure 2.
These two images are first sampled from distribution, i.e. and then optimize one of them to minimize distance in representation space to the other, i.e. solving the following problem:
Note that if representations truly provided an encoding of any image into high-level features, finding images with similar representations should necessitate finding images with similar high-level features.
This indicates that although the features learned are linearly separable but they are acquired with an injective feature extractor.
It was also pointed by another work saying that excessive invariance brings adversarial vulnerability. Since the phenomenon demonstrated here is actually because the network is too invariant to semantically meaningful information.
Specifically, models trained with objective (3) must be invariant to a set of perturbations . Thus, selecting to be a set of perturbations that humans are robust to (e.g., small -norm perturbations) results in models that share more invariances with (and thus are encouraged to use similar features to) human perception.
Properties and Applications of Robust Representations
Robust representations are (approximately) invertible out of the box

Use the same optimization:
which can be viewed as recovering an image that maps to the desired target representation, commonly referred to as representation inversion.
On robust classifier, the recovered images share similar semantic information as shown in Figure 3.
Representation proximity seems to entail semantic similarity
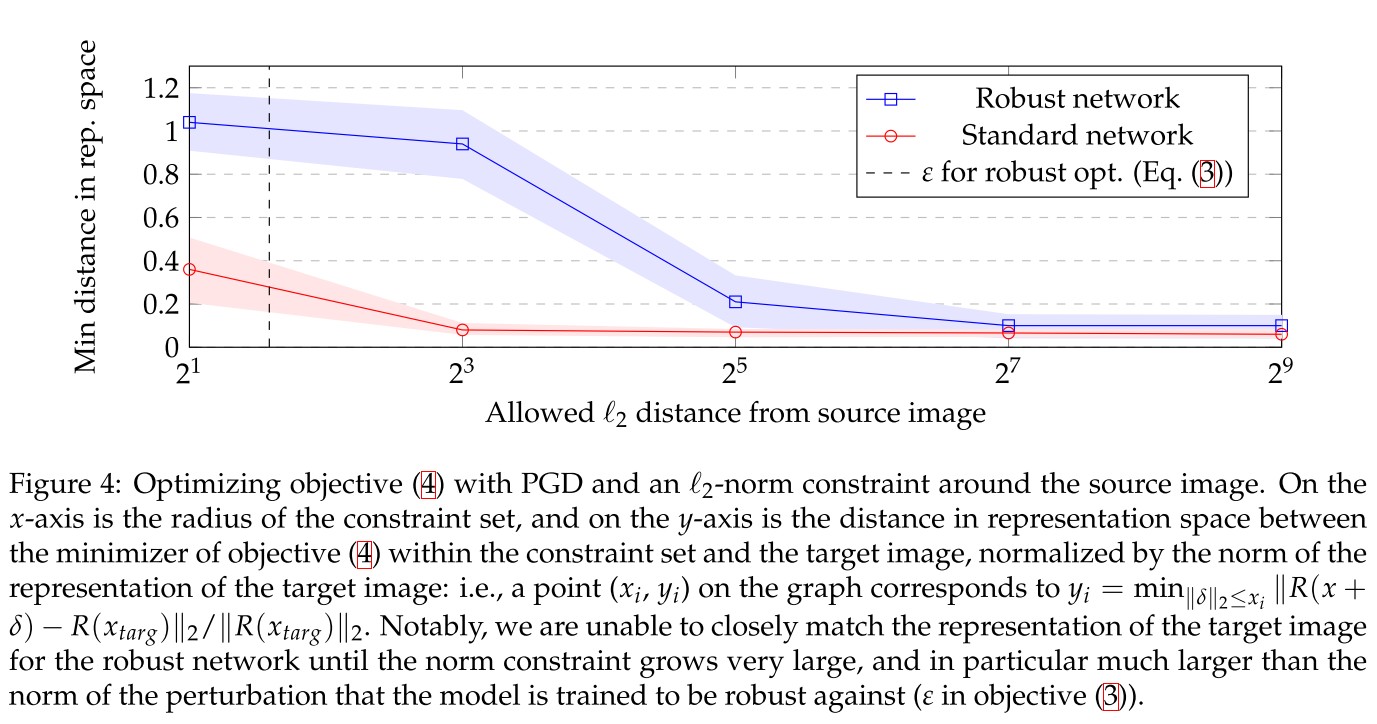

On the other hand, for robust models, we cannot get close to the target representation while staying close to the source image—this is illustrated quantitatively in Figure 4.
We also find that even when δ is highly constrained (i.e. when we are forced to stay very close to the source image and thus cannot match the representation of the target well), the solution to the inversion problem still displays some salient features of the target image (c.f. Figure 5)
It indicates that robust representation is highly representative.
Inversion of out-of-distribution inputs

We find that the inversion properties uncovered above hold even for out-of-distribution inputs, demonstrating that robust representations capture general features as opposed to features only relevant for the specific classification task.
It indicates that robust representations are universally invertible.....
Does it mean that adversarially trained model loses some domain knowledge?
Interpolation between arbitrary inputs

Note that this ability to consistently invert representations into corresponding inputs also translates into the ability to semantically interpolate between any two inputs.
This is expected but still very surprising.
Direct feature visualization


Optimization-based feature visualization is a common technique for visualizing and understanding the representation function of a given network. It maximizes a specific feature in the representation with respect to the input to obtain insight into the role of the feature in classification.
Given some denoting a component of the representation vector, one can use gradient descent to find an input that maximally activates it, i.e.
where refers to various starting points.
For standard networks, optimizing the objective (5) often yields unsatisfying results
For robust representations, however, we find that easily recognizable high-level features emerge from optimizing objective (5) directly, without any regularization or post-processing.

As a natural consequence, it's possible to use the same optimization to manipulate the feature as shown in Figure 11.
Inspiration
This paper shows some surprising but expected properties of robust classifier, the potential to use a classifier to generate images is very promising, and soon there will be people trying to improve the quality of these generated images.
But I think the essence is the bijective property of the feature extraction function, maybe it's possible to enforce bijective to gain robustness.
Generative Approach for Adversarial Robustness
Analysis by Synthesis (a Bayesian Classifier for MNIST) - 2018
Lukas Schott, Jonas Rauber, Matthias Bethge, Wieland Brendel. Towards the first adversarially robust neural network model on MNIST. arXiv preprint 2018. arXiv:1805.09190
We present a novel robust classification model that performs analysis by synthesis using learned class-conditional data distributions.
The results suggest that our approach yields state-of-the-art robustness on MNIST against , and perturbations and we demonstrate that most adversarial examples are strongly perturbed towards the perceptual boundary between the original and the adversarial class.
They trained 10 generative models for each class of MNIST and then use Bayesian equation for classification. It's semantically adversarially robust.
Analysis by Synthesis
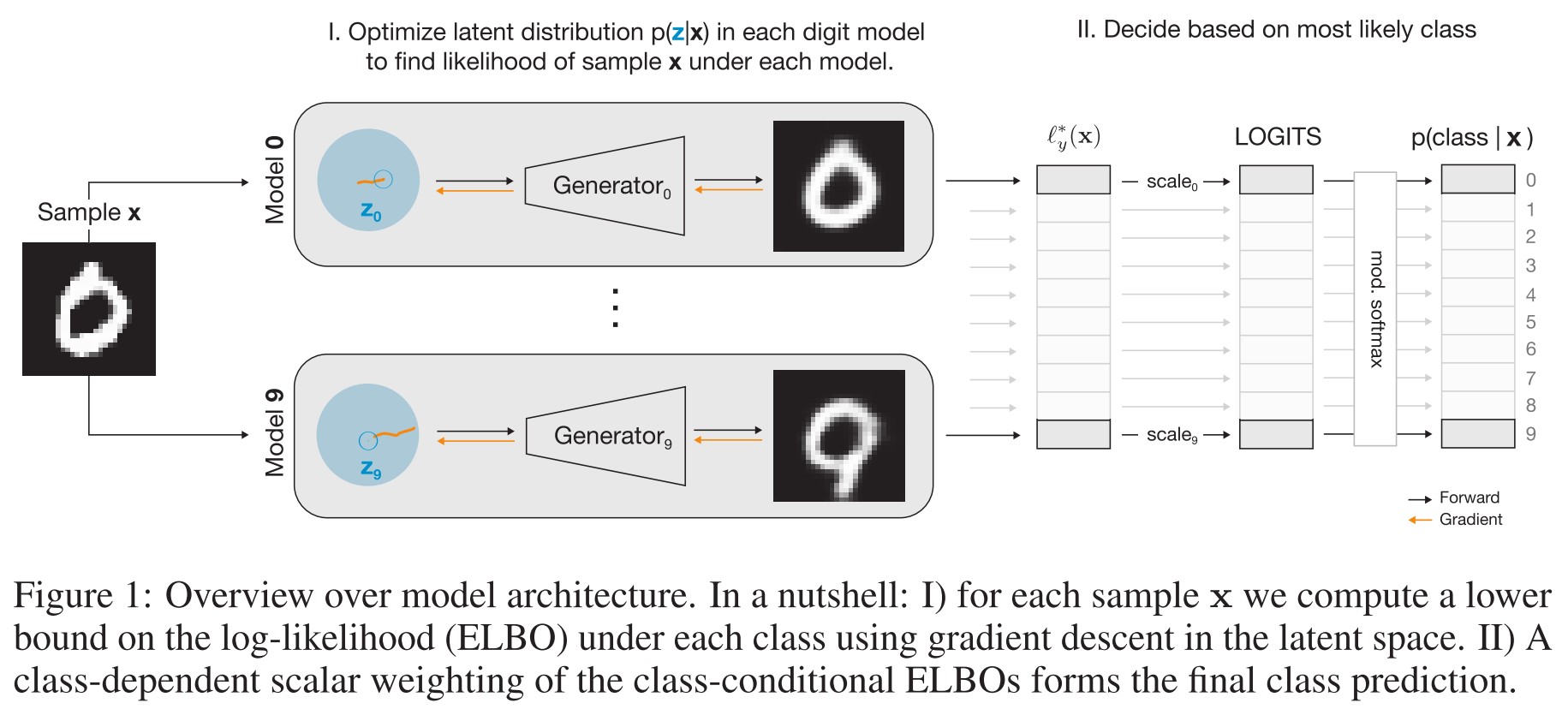
As shown in Figure 1, they train ten class-conditional generative models based on variational auto-encoder, and use them to classify the input robustly.
The Bayesian classifier is formulated as follows:
Let with be an input-label datum. Instead of directly learning a posterior from inputs to labels, the Bayesian classifiers learn generative distributions and classify new inputs using Bayes formula, i.e.
The label distribution can be estimated from the training data. And they use variational autoencoders (VAEs) to learn the class-conditional sample distributions .
VAEs estimate the log-likelihood by learning a probabilistic generative model with latent variables and parameters :
where is a simple normal prior and is the variational posterior with parameters .
The first term is a reconstruction error and the second term is the mismatch between the variational and the true posterior. This term is the so-called evidence lower bound (ELBO) on the log-likelihood.
The structure of the propose analysis by synthesis (ABS) model is as shown in Figure 1.
Class-conditional distributions
For each class they train a variational autoencoder on the samples of class to learn the class-conditional distribution .
Optimization-based inference
The variational inference itself is a neural network susceptible to adversarial perturbations, so they use an optimization-based inference by
To avoid local minima we evaluate 8000 random points in the latent space of each VAE, from which we pick the best as a starting point for a gradient descent with 50 iterations using the Adam optimizer.
The inference is too slow for this classifier to be practically useful.
Classification and confidence
To perform the actual classification, they scale all with a factor , add an offset and divide it by the total evidence, i.e.
A variant of softmax.
To model this behavior we set : in this case the posterior converges to a uniform distribution whenever the maximum gets small relative to .
Binarization (Binary ABS only)
For Binary ABS, they project the intensity of each pixel to if or if during testing.
Discriminative finetuning (Binary ABS only)
For Binary ABS, they multiply with an additional class-dependent scalar , which are learned discriminatively and reach values in the range for all classes .
Tight estimate of the lower bound for adversarial examples
The optimization-based inference can be written as
where the normalization constants of are absorbed into and is the mean of .
Let be the ground-truth class and let be the optimal latent for the clean sample for class .
The lower bound on for a perturbation with size can be estimated by
Likewise, the upper bound for all other classes is
for .
By equating the two bounds, the perturbation becomes
Experiments
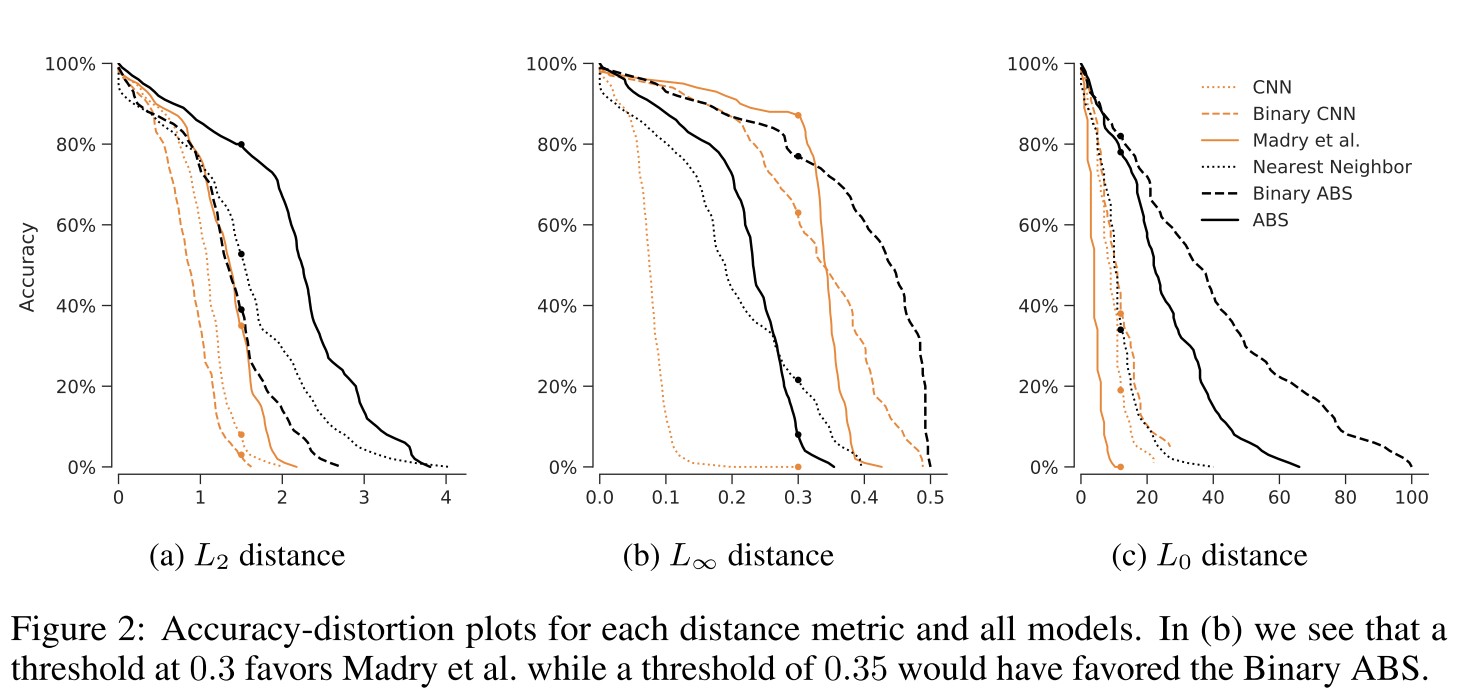
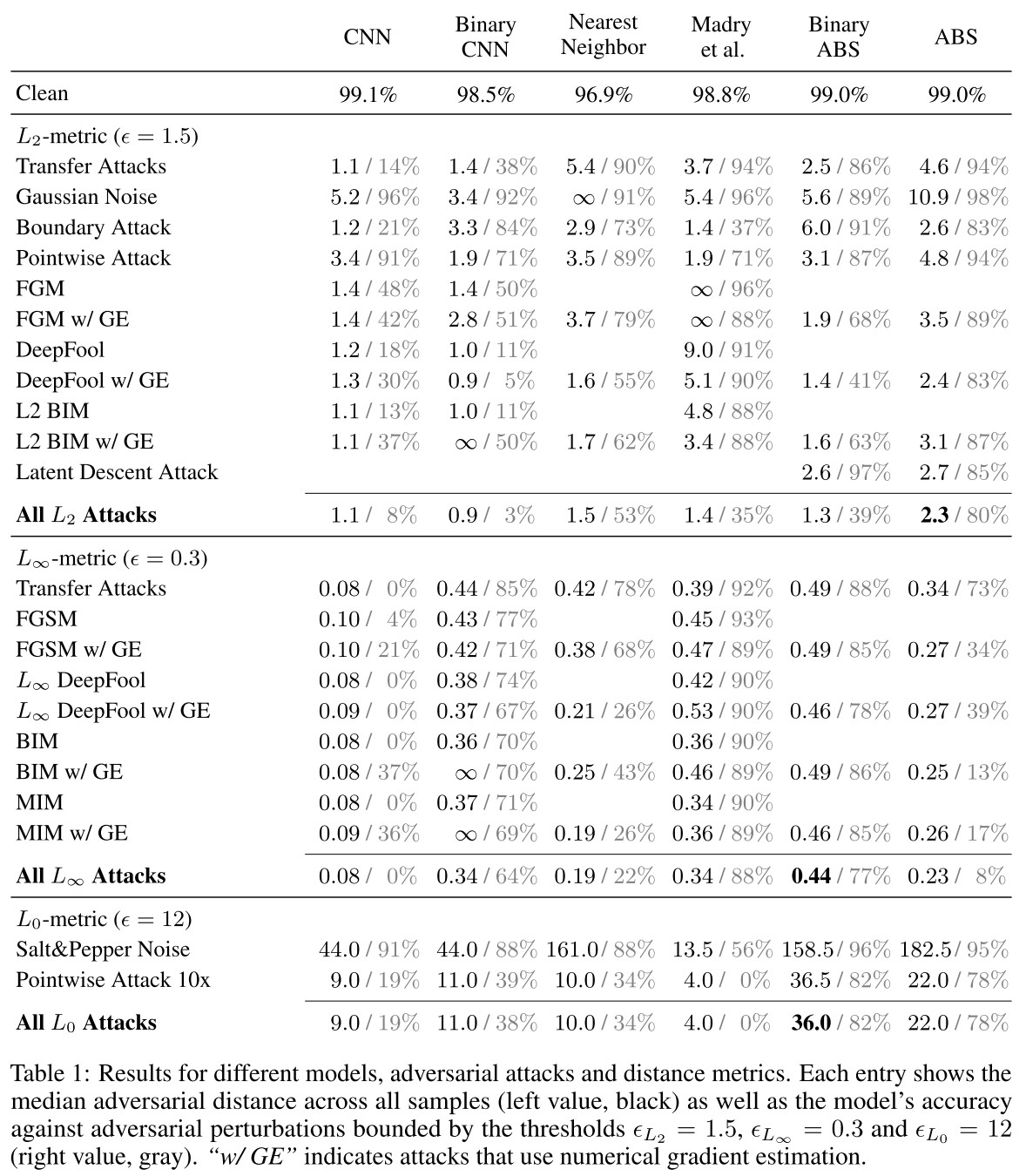

As shown by experiments, ABS is quite robust. And the generated adversarial examples show semantic tamper, which violates the imperceptibility requirement, so it's still rational to say that it's robust.
Although the inference cost is impractical.
Inspirations
Bayesian classifiers suffer from inference cost, so it's not practically useful, however, I think it can be modified to be useful.
This paper didn't get any attention even after two years, I don't know why. Perhaps because variational inference is not a hot topic and the title of this paper restricts the dataset to be MNIST, which is likely to be ingeneralizable.