Adversarial Defense at Inference
By LI Haoyang 2020.11.12
Content
Adversarial Defense at InferenceContentPurificationPixelDefend - ICLR 2018Pixel CNNDistribution of adversarial examplesPurifying images with PixelDefendExperimentsInspirationsMixup InferencePost-averaging - 2019Fourier Analysis of Neural NetworksUnderstanding Adversarial ExamplesPost-averagingSampling MethodsExperimentsInspirationsMixup Inference - ICLR 2020Mixup Inference defenseTheoretical analysisMI with predicted label (MI-PL)MI with other labels (MI-OL)ExperimentsInspirations
Purification
PixelDefend - ICLR 2018
This defense is breached in Obfuscated Gradients Give a False Sense of Security - ICML 2018.
Yang Song, Taesup Kim, Sebastian Nowozin, Stefano Ermon, Nate Kushman. PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples. ICLR 2018. arXiv:1710.10766
In this paper, we show empirically that adversarial examples mainly lie in the low probability regions of the training distribution, regardless of attack types and targeted models.
They argue that adversarial examples lie in the low probability region of the generating distribution of datasets, therefore they fool the classifiers mainly due to covariate shift.
This is analogous to training models on MNIST (LeCun et al., 1998) but testing them on Street View House Numbers (Netzer et al., 2011).
Pixel CNN
The PixelCNN (van den Oord et al., 2016b; Salimans et al., 2017) is a generative model with tractable likelihood especially designed for images.
It defines the joint distribution over all pixels by factorizing it into a product of conditional distributions, i.e.
The pixel dependencies are in raster scan order (i.e. row by row and column by column with each row).
It views an image as a vector of pixels and predicts the next pixel with the previous pixel sequentially.
For an image of resolution and channels, its bits per dimension is defined as
Distribution of adversarial examples
The transferability of adversarial examples indicate that there are some intrinsic properties of adversarial examples which are classfier-agnostic.
One possibility is that, compared to normal training and test images, adversarial examples have much lower probability densities under the image distribution.
As a result, classifiers do not have enough training instances to get familiarized with this part of the input space.
![]()
They train a PixelCNN on CIFAR-10 and use its log-likelihood as an approximation to the true underlying probability density. They also generate a bunch of adversarial examples respect to ResNet.
As shown in Figure 2, the distribution of log-likelihoods show considerable difference between perturbed images and clean images. As for the random noise that also shift the distribution of original data (but not adversarial), they explain that
We believe this is due to an inductive bias that is shared by many neural network models but not inherent to all models, as discussed further in Appendix A
![]()
The -value is a statistical indicator calculated from PixelCNN model, for clean images, it should follow a uniform distribution. As shown in Figure 3, there are clear differences between the uniform distribution and the distributions of adversarial examples.
Purifying images with PixelDefend
![]()
The purification is intended to move the adversarial examples back towards the training distribution.
The problem is to find an image that maximizes the probability that it comes from the training distribution subject to the constraint that is within the -ball of adversarial example , i.e.
The -ball is designed to ensure the process does not change the semantic meaning. In practice, is approximated using the from the trained PixelCNN.
They test L-BFGS-B and a greedy technique (as in Algorithm 1) to solve this problem.
![]()
![]()
![]()
As shown above, PixelDefend can effectively purify the adversarial examples.
As for the effects of PixelDefend on clean images, they adopt an adaptive threshold to deal with this problem.
They argue that the ability to attack end-to-end with PixelDefend is limited (although disputable).
Experiments
![]()
![]()
Inspirations
The idea of purifying adversarial example is very ideal and if it was not breached and classified as gradient masking.
I think this road is still possible, perhaps combining adversarial training with purification of adversarial examples.
Mixup Inference
Post-averaging - 2019
Yuping Lin, Kasra Ahmadi K. A., Hui Jiang. Neural Networks Against Adversarial Attacks. arXiv preprint 2019. arXiv:1905.12797
This paper is likely to have been rejected by NIPS 2019.
We first explicitly compute the Fourier transform of deep ReLU neural networks and show that there exist decaying but nonzero high frequency components in the Fourier spectrum of neural networks.
We demonstrate that the vulnerability of neural networks towards adversarial samples can be attributed to these insignificant but non-zero high frequency components.
We propose to use a simple post-averaging technique to smooth out these high frequency components to improve the robustness of neural networks against adversarial attacks.
Fourier Analysis of Neural Networks
As we know, any fully-connected ReLU neural networks (prior to the softmax layer) essentially form piece-wise linear functions in input space.
Definition 2.1. A piece-wise linear function is a continuous function such that there are some hyperplanes passing through origin and dividing into pairwise disjoint regions , (), on each of which is linear:
Lemma 2.2. Composition of a piece-wise linear function with a ReLU activation function is also a piece-wise linear function.
Theorem 2.3. The output of any hidden unit in an unbiased fully-connected ReLU neural network is a piece-wise linear function.
It states that if we take out the neural networks with ReLU activation cut in the chosen unit, the function it forms is a piece-wise linear function.
For the purpose of mathematical analysis, we need to decompose each region into a union of some well-defined shapes having a uniform form, which is called infinite simplex.
Definition 2.4. Let be a set of linearly independent vectors in . An infinite simplex, , is defined as the region linearly spanned by using only positive weights:
For example, the first quadrant is an infinite simplex spanned by .
can be interpreted as a set of bases.
Theorem 2.5. Each piece-wise linear function can be formulated as a summation of some simpler functions: , each of which is linear and non-zero only in an infinite simplex as follows:
where is a set of linearly independent vectors, and is a weight vector.
In practice, we can assume the input to be bounded, hence possible to normalize into the unit hyper-cube, .
Obviously, this assumption can be easily incorporated into the above analysis by multiplying each by where is the Heaviside step function (阶跃函数).
I think this is a clamp, not a normalization....
Alternatively, we may simplify this term by adding additional hyperplanes to further split the input space to ensure all the elements of do not change signs within each region .
In this case, within each region , the largest absolute value among all elements of is always achieved by a specific element, denoted as .
The dimension achieves the largest absolute value inside .
Why?
The normalized piece-wise linear function may be represented as a summation of some functions: , where each has the following form:
Since is a set of bases can be transformed from standard bases, each function may be represented in terms of standard bases as follows:
where and .
Lemma 2.6. Fourier transform of the following function:
may be represented as:
where is the -th component of frequency vector , and .
Finally we derive the Fourier transform of fully-connected ReLU neural networks as follows.
Theorem 2.7. The Fourier transform of the output of any hidden node in a fully-connected unbiased ReLU neural network may be represented as , where denotes the differential operator.
Obviously, neural networks are the so-called approximated bandlimited models as defined in (Jiang, 2019), which have decaying high frequency components in Fourier spectrum.
Since the determinant of is proportional to the volume of in , when the region of are too small, the matrices have a large determinant and contribute to the high frequency components a lot.
Understanding Adversarial Examples
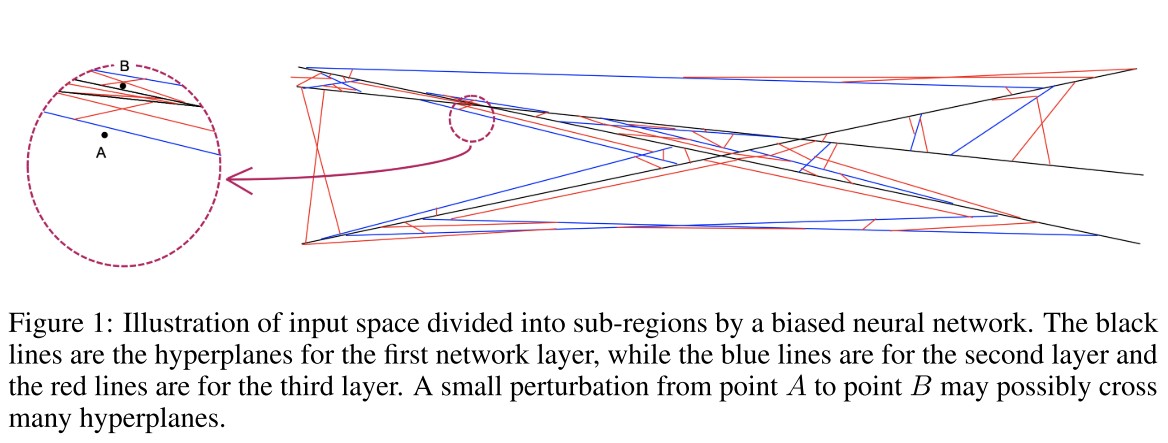
According to Theorem 2.3., a neural network may be viewed as a sequential devision of the input space as shown in Figure 1. Each layer is a further division of the existing regions from the previous layers.
Hence a neural network with multiple layers would result in a tremendous amount of sub-regions in the input space.
When we learn a neural network, we can not expect there is at least one sample inside each region. For those regions that do not have any training sample, the resultant linear functions in them may be arbitrary since they do not contribute to the training objective function at all.
When we measure the expected loss function over the entire space, their contributions are negligible since the chance for a randomly sampled point to fall into these tiny regions is extremely small.
Given that the total number of regions is huge, those tiny regions are almost everywhere in the input space.
They attribute adversarial examples to the existence of these untrained arbitrary small regions almost everywhere.
When a small perturbation is made to any input , the fluctuation in the output of any hidden node can be approximately represented as:
where denotes the total number of hyperplanes to be crossed when moving to .
In other words, for any input in a high-dimensional space, we can always move it to cross a large number of hyperplanes to enter a tiny region.
When is fairly large, the above equation indicates that the output of a neural network can still fluctuate dramatically even after all weight vectors are regularized by L1 or L2 norm.
In principle, neural networks must be strictly bandlimited to filter out those decaying high frequency components in order to completely eliminate all adversarial samples.
Post-averaging
The post-averaging proposed works by averaging the output of a series of data points. It is computed as an integral over a small neighborhood centered at the input:
where is the input and is the output, denotes a small neighborhood centered at the origin and denotes its volume.
It seems that if the error rate of this model in this neighborhood is smaller than 0.5, this will works fine.
When is an -sphere in of radius , the Fourier transform of is:
where is the first kind Bessel function of order .
The Bessel functions, , decay with rate as , therefore, as .
Therefore, if is chosen properly, the post-averaging operation can significantly bandlimit neural networks by smoothing out high frequency components.
Sampling Methods
The integral is intractable in practice. They propose an approximation.
For any input , they select points in the neighborhood centered at , i.e. , the integral is approximated with
For the sampling of neighborhood, they make use of directional vectors. For some directional vectors , the samples are taken by
where and is a selected unit-length directional vector.
They propose two sampling strategies:
random
Fill the directional vectors with random noise.
A post Gaussian noise augmentation.
approx
Approximate the directional vectors with gradient.
A post DeepFool augmentation.
Experiments
The proposed method requires no re-training, so they used a pre-trained VGG16 network. For evaluation, they adopt Foolbox to generate adversarial examples.
The threat model they considered is -norm with .
The results are too good to be true....
Inspirations
Their explanation for adversarial examples are unique and inspiring, the defense is reported to be very effective.
The post-averaging seems to be time-consuming, which hinders its application.
Mixup Inference - ICLR 2020
Code: https://github.com/P2333/Mixup-Inference
Paper: https://openreview.net/forum?id=ByxtC2VtPB
Tianyu Pang, Kun Xu, Jun Zhu. Mixup Inference: Better Exploiting Mixup to Defend Adversarial Attacks. ICLR 2020.
Namely, since the locality of the adversarial perturbations, it would be more efficient to actively break the locality via the globality of the model predictions.
MI mixups the input with other random clean samples, which can shrink and transfer the equivalent perturbation if the input is adversarial.
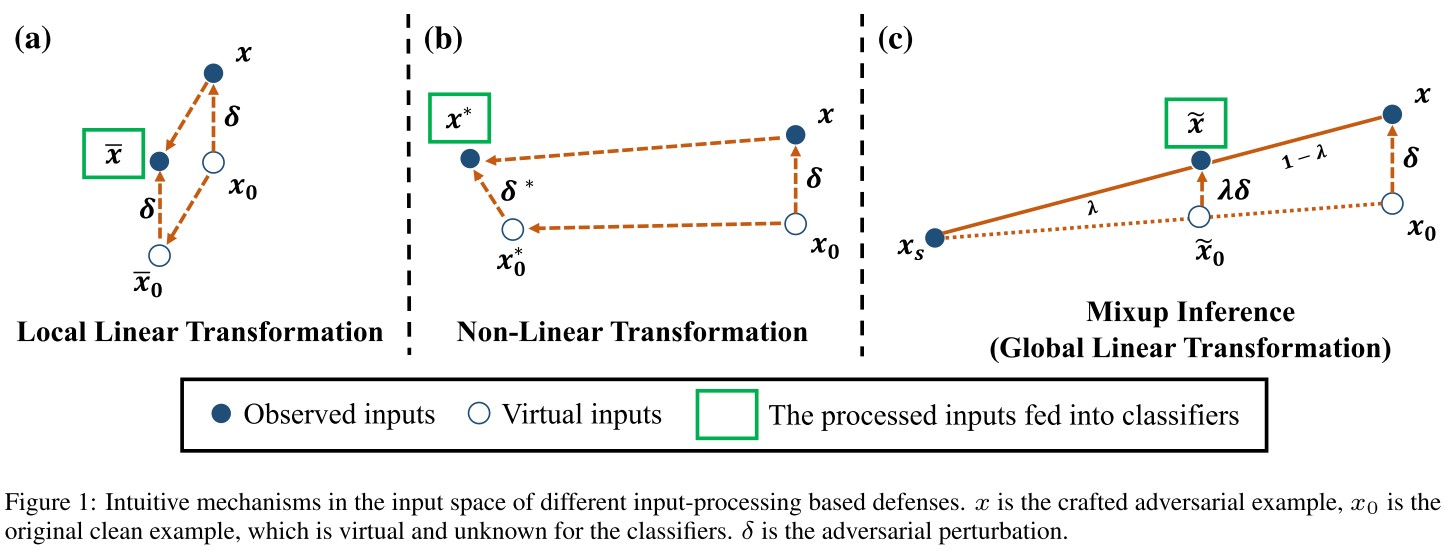
As shown in Figure 1(c), mixup inference introduces pertubation shrinkage and input transfer to the potentially perturbed examples.
The basic idea of mixup inference (MI) is very simple, the final input of the model is a mixup of the provided (potentially adversarial) input and a sampled clean example , i.e. .
Mixup Inference defense

An iteration of MI operations is as follows:
- Sample a label .
- Sample from .
- Mix it up with , i.e. .
- Update .
They actually construct a new statistical model based on the original model.
Theoretical analysis
Given defined as
and a clean example from the data manifold . A general example can be denoted as
Based on the assumption that adversarial examples are off the data manifolds, they assume .
Suppose predict the one-hot vector of label , i.e. .
If the input is adversarial, then there should be an extra non-linear part of , assuming that is off the data manifolds.
Thus for a general input , the prediction vector is
The output of the mixup in MI is then
assuming that is a linear function on the combination of clean images.
The output in Algorithm 1 is a Monte Carlo approximation of , i.e.
To statistically make sure that the clean inputs will be correctly classified after MI-OL, there should be .
The -th components of are
Given , the -th components of are
since .
Consider the following scenarios:
MI with predicted label (MI-PL)
The sampling label is the same as predicted label , i.e. .
MI with other labels (MI-OL)
The sampling label is uniformly sampled from the labels other than , i.e. , a discrete uniform distribution on the set .
The resulting output is shown below.

Consider the difference:
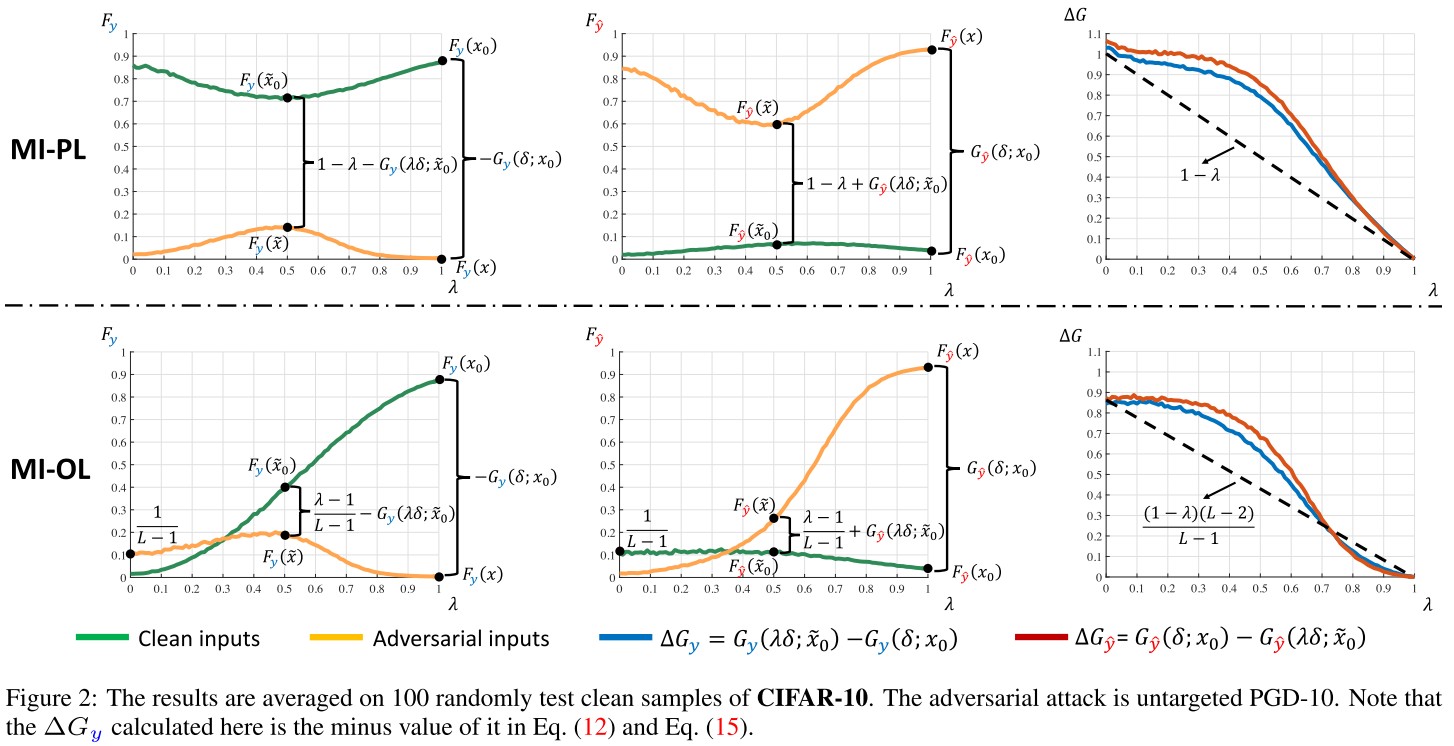
They claim that the MI method improves the robustness if the prediction value on the true label increases while it on the adversarial label decreases after performing MI when the input is adversarial (i.e. ).
Named as robustness improving condition (RIC) and formally denoted as
They also define a detection gap (DG), denoted as
A higher value of DG indicates that is better as a detection metric.
MI with predicted label (MI-PL)
If MI-PL can improve the general-purpose robustness, it should satisfy RIC, according to Table 1, it means that
The upper notion can be decomposed into
Indicating the two mechanisms of MI.
And the detection gap is
MI with other labels (MI-OL)
Since , similarly, there should exist
And the detection gap is
And there exists .
However, in practice we find that MI-PL performs better than MI-OL in detection, since empirically mixup-trained models cannot induce ideal global linearity.
They verified the conditions that should be satisfied as shown in Figure 2.
Experiments
In training, we use ResNet-50 (He et al., 2016) and apply the momentum SGD optimizer (Qian, 1999) on both CIFAR-10 and CIFAR-100
The attack method for AT and interpolated AT is untargeted PGD-10 with and step size 2/255 (Madry et al., 2018), and the ratio of the clean examples and the adversarial ones in each mini-batch is 1 : 1 (Lamb et al., 2019).
Notations:
ERM
Empirical Risk Minimization, the standard training
Mixup (Mixup training)
It minimizes, where , .
Interpolated AT
Interpolated Adversarial Training
As a practical strategy, we also evaluate a variant of MI, called MI-Combined, which applies MI-OL if the input is detected as adversarial by MI-PL with a default detection threshold; otherwise returns the prediction on the original input.
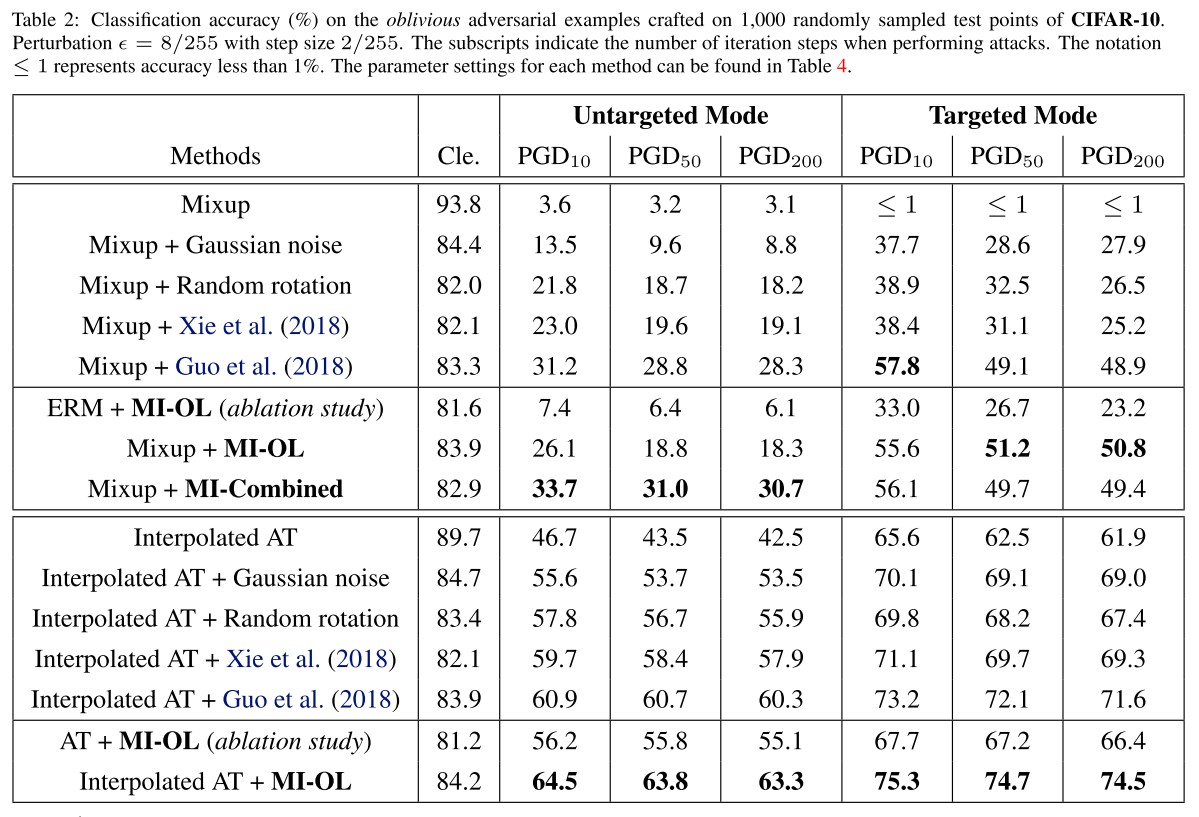
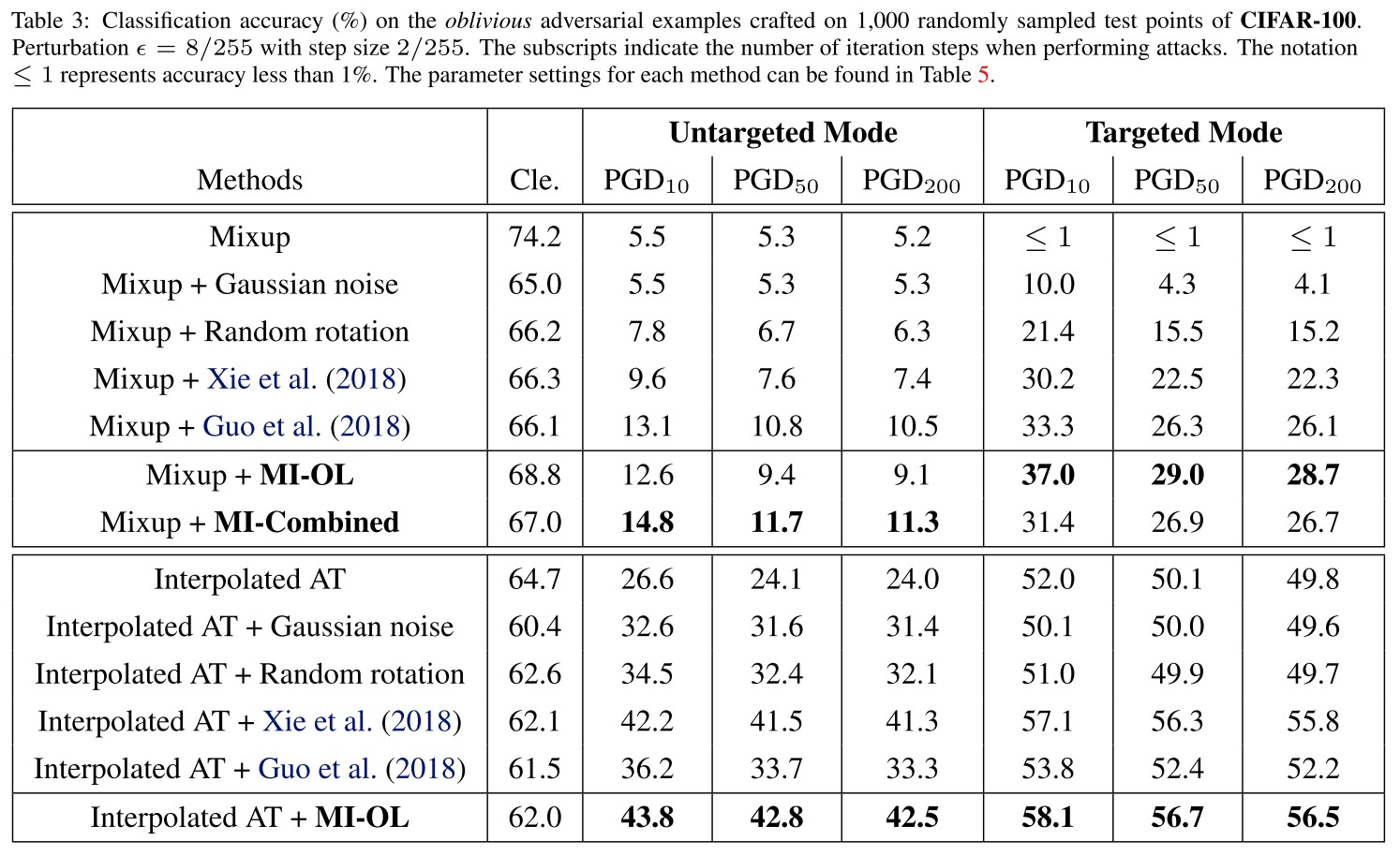
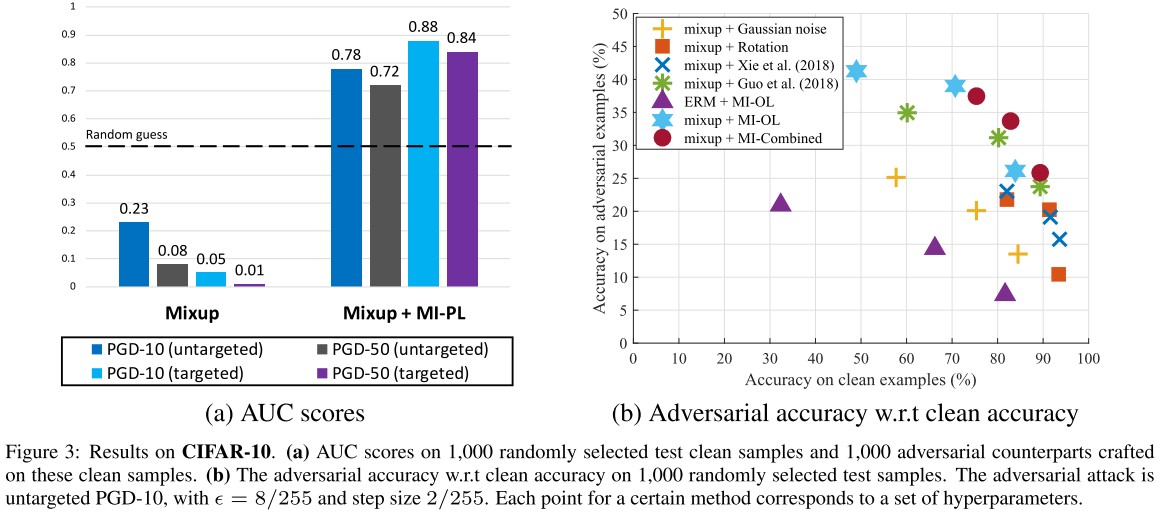
The results show that applying MI-PL in inference can better detect adversarial attacks, while directly detecting by the returned confidence without MI-PL performs even worse than a random guess.
As shown in these results, our MI method can significantly improve the robustness for the trained models with induced global linearity, and is compatible with training-phase defenses like the interpolated AT method.
It cannot work effectively independently.
They also evaluate on a customized adaptive attack.
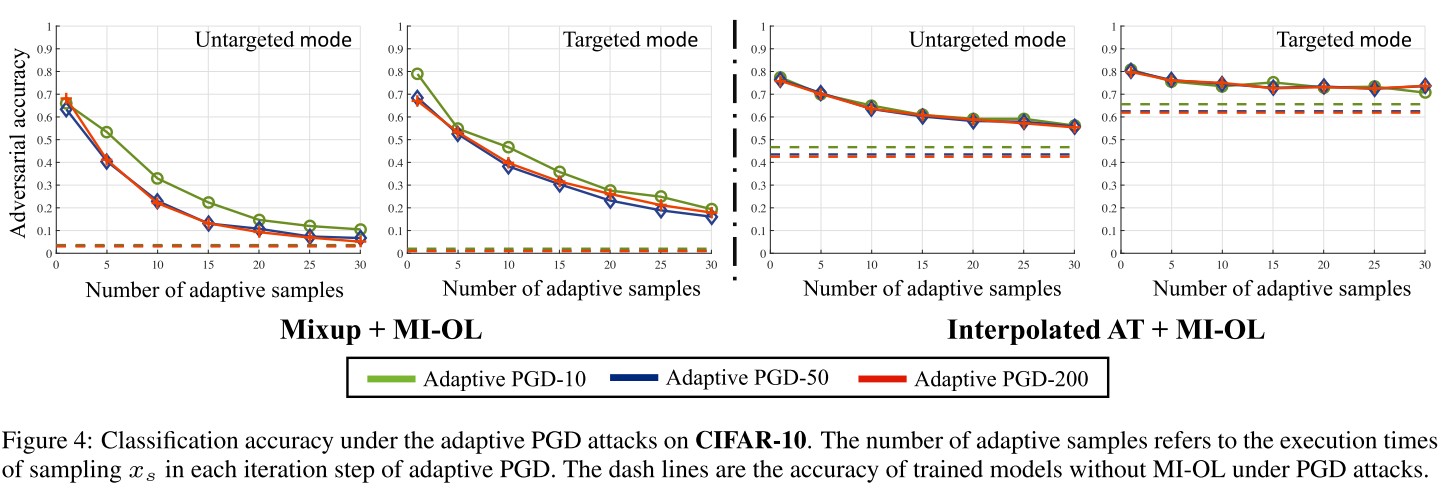
We can see that even under a strong adaptive attack, equipped with MI can still improve the robustness for the classification models.
Inspirations
This paper instantiates one of my ideas, and give a very comprehensive theoretical analysis. If the model follow the assumption that it works linearly on the combination of clean images, MI should work quite well, as demonstrated with Mixup Training and Interpolate AT.
The assumption is too strong, since most of the common classifiers do not function linearly between instances.
But it gives another inspiration, if the is very close to the clean image itself, the perturbation shrinkage will be very large, potentially fix the misclassification.