Adversarial Defense with Ensemble
By LI Haoyang 2020.11.12 (branched)
Content
Adversarial Defense with EnsembleContentEnsemble + Adversarial TrainingEnsemble Adversarial Training - ICLR 2018Adversarial TrainingEnsemble Adversarial TrainingR+FSGMExperimentsInspirationsDVERGE - NIPS 2020MethodAlgorithmPerformanceInspirations
Ensemble + Adversarial Training
Ensemble Adversarial Training - ICLR 2018
Paper: https://openreview.net/forum?id=rkZvSe-RZ
Florian Tramèr, Alexey Kurakin, Nicolas Papernot, Ian Goodfellow, Dan Boneh, Patrick McDaniel. Ensemble Adversarial Training: Attacks and Defenses. ICLR 2018. arXiv:1705.07204
We show that this form of adversarial training converges to a degenerate global minimum, wherein small curvature artifacts near the data points obfuscate a linear approximation of the loss.
We further introduce Ensemble Adversarial Training, a technique that augments training data with perturbations transferred from other models.
In particular, our most robust model won the first round of the NIPS 2017 competition on Defenses against Adversarial Attacks (Kurakin et al., 2017c).
Adversarial Training
The basic adversarial training is a variant of standard Empirical Risk Minimization (ERM), i.e.
Adversarial training has a natural interpretation in this context, where a given attack (see below) is used to approximate solutions to the inner maximization problem, and the outer minimization problem corresponds to training over these examples.
For the inner maximization problem, i.e. generating an adversarial examples, they consider following methods:
Fast Gradient Sign Method (FSGM)
This method linearizes the inner problem:
Single-Step Least-Likely Class Method (Step-LL)
This method targets the least-likely class :
Kurakin et al. (2017b) find it to be the most effective for adversarial training on ImageNet.
Iterative Attack (I-FGSM or Iter-LL)
This method iteratively applies the FGSM or Step-LL times with step-size and projects each step onto the ball of norm around .
Using the single-step attack to approximate the inner problem, the problem further becomes
This alternative optimization problem admits at least two substantially different global minima :
For an input from , there is no close to in norm that induces a high loss, i.e.
This is then robust to all perturbations.
The approximation method underlying the attack poorly fits the model's loss function, i.e.
Thus, adversarial training does not simply learn to resist the particular attack used during training, but actually to make that attack perform worse overall.
This phenomenon relates to the notion of Reward Hacking (Amodei et al., 2016) wherein an agent maximizes its formal objective function via unintended behavior that fails to captures the designer’s true intent.
Ensemble Adversarial Training
Our method, which we call Ensemble Adversarial Training, augments a model’s training data with adversarial examples crafted on other static pre-trained models.
In Domain Adaptation, a model trained on data sampled from one or more source distributions is evaluated on samples from a different target distribution .
Let be an adversarial distribution, i.e. .
In Ensemble Adversarial Training, the source distributions are and . The target distribution takes the form of an unseen black-box adversary .
Standard generalization bounds for Domain Adaptation (Mansour et al., 2009; Zhang et al., 2012) yield the following result.
Theorem 1 (informal) Let be a model learned with Ensemble Adversarial Training and static black-box adversaries . Then, if is robust against the black-box adversaries used at training time, then has bounded error on attacks from a future black-box adversary , if is not "much stronger", on average, than the static adversaries .
An ensemble adversarial training on adversaries can improve robustness on weaker or equal unseen attacks.
Assume the model is trained on data points , where data points are sampled from each distribution , for .
Denote . At test time, the model is evaluated on adversarial examples from .
For a model , they define the empirical risk as
and the risk over the target distribution (i.e. future adversary) as
The average discrepancy distance between distributions and with respect to a hypothesis space is defined as
The discrepancy distance between two hypotheses are the difference between their expected prediction difference between two distributions. The average discrepancy distance are averaged over distributions and the upper bound of the difference in a hypothesis space.
This quantity characterizes how “different” the future adversary is from the train-time adversaries.
Let be the average Rademacher complexity of the distributions . The following theorem is a corollary of Zhang et al. (2012, Theorem 5.2):
Theorem 5 Assume that is a function class consisting of bounded functions. Then, with probability at least ,
In our context, this means that the model learned by Ensemble Adversarial Training has guaranteed generalization bounds with respect to future adversaries that are not “too different” from the ones used during training.
R+FSGM
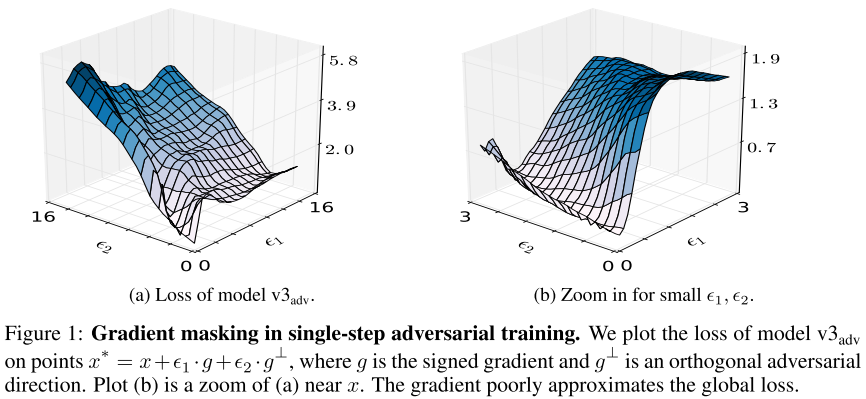
The v3adv is short for adversarially trained Inception V3 on a Step-LL attack with . (Kurakin et al. 2017).
They visualize the "gradient masking" effect by plotting the loss of v3adv on examples , where is the signed gradient of model v3adv and is a signed vector orthogonal to .
Figure 1 shows that the loss is highly curved in the vicinity of the data point x, and that the gradient poorly reflects the global loss landscape.
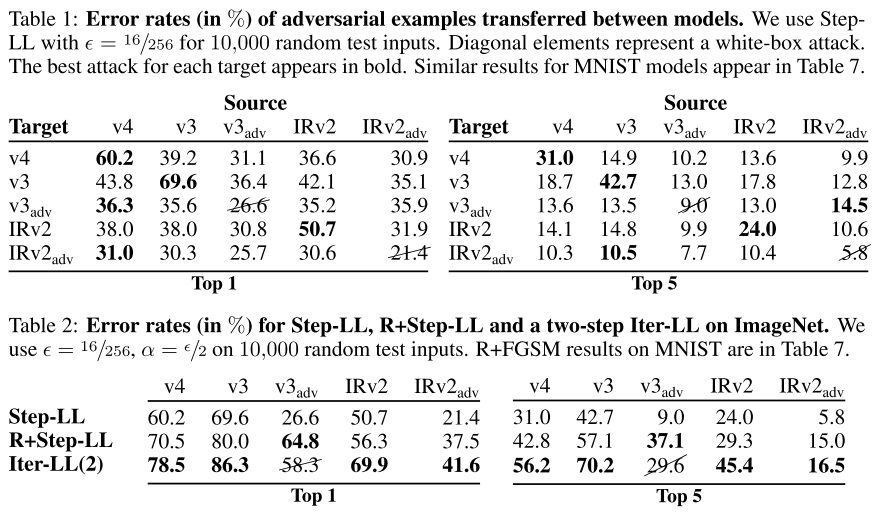
Table 1 shows error rates for single-step attacks transferred between models. We compute perturbations on one model (the source) and transfer them to all others (the targets). When the source and target are the same, the attack is white-box.
Adversarial training greatly increases robustness to white-box single-step attacks, but incurs a higher error rate in a black-box setting. Thus, the robustness gain observed when evaluating defended models in isolation is misleading
They suggest to prepend signle-step attacks by a small random step to "escape" the non-smooth vicinity of the data point before linearizing the model's loss, named as R+FGSM (resp. R+Step-LL), i.e.
This method is re-proposed as FGSM with random start point.....
As shown in Table 2,
The extra random step yields a stronger attack for all models, even those without adversarial training.
Surprisingly, we find that for the adversarially trained Inception v3 model, the R+Step-LL attack is stronger than the two-step Iter-LL attack.
Experiments

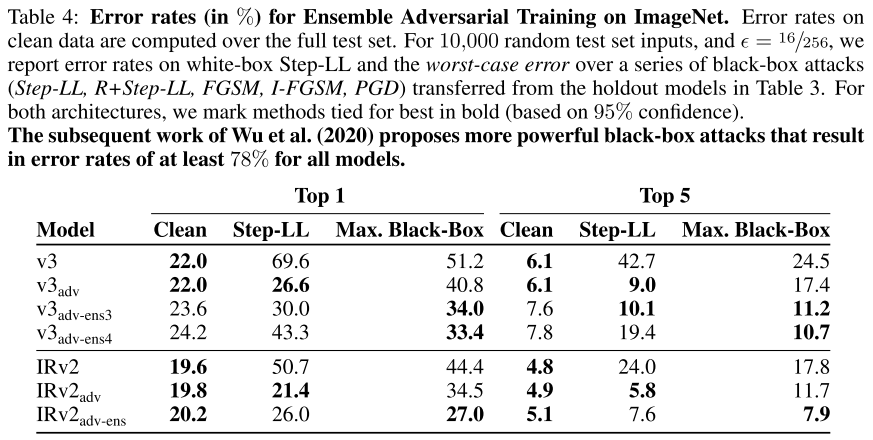
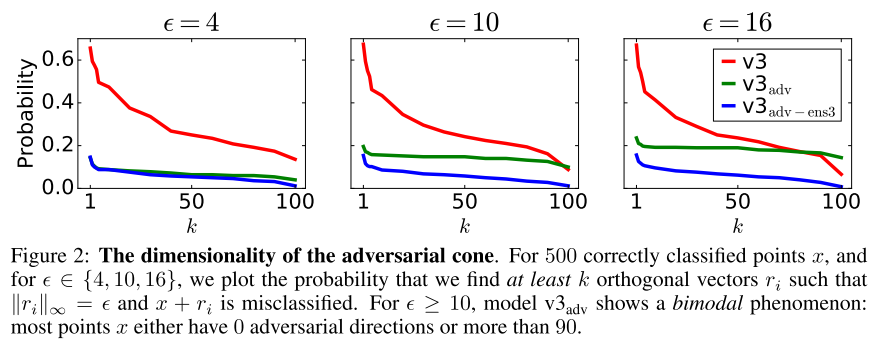
We use the Step-LL, R+Step-LL, FGSM, I-FGSM and the PGD attack from Madry et al. (2017) using the hinge-loss function from Carlini & Wagner (2017a).
Convergence of Ensemble Adversarial Training is slower than for standard adversarial training, a result of training on “hard” adversarial examples and lowering the batch size.
For both architectures, the models trained with Ensemble Adversarial Training are slightly less accurate on clean data, compared to standard adversarial training.
Ensemble Adversarial Training is not robust to white-box Iter-LL and R+Step-LL samples: the error rates are similar to those for the v3adv model, and omitted for brevity (see Kurakin et al. (2017b) for Iter-LL attacks and Table 2 for R+Step-LL attacks).
Ensemble Adversarial Training significantly boosts robustness to the attacks we transfer from the holdout models.
Inspirations
This paper is out of date, hence providing not much inspirations now.
DVERGE - NIPS 2020
Huanrui Yang, Jingyang Zhang, Hongliang Dong, Nathan Inkawhich, Andrew Gardner, Andrew Touchet, Wesley Wilkes, Heath Berry, Hai Li. DVERGE: Diversifying Vulnerabilities for Enhanced Robust Generation of Ensembles. NIPS 2020. arXiv:2009.14720
It's an ensemble defense based on adversarial training.
We propose DVERGE, which isolates the adversarial vulnerability in each sub-model by distilling non-robust features, and diversifies the adversarial vulnerability to induce diverse outputs against a transfer attack.
DVERGE is short for Diversifying Vulnerabilities for Enhanced Robust Generation of Ensembles.

The ensembled decison region appears to be more robust.
Method
They start by isolating the vulnerability of CNN models based on the distilled non-robust features, defined (by Madry.et.al) as:
In which, is a targeted input pair, is another randomly chosen source pair and denotes the output before the activation of the -th layer. This distilled feature is designed to be visually similar to while classified as (shares the similar feature with ), which is expected to reflect the adversarial vulnerability of when classifying .
Then they define a vulnerability diversity between two models and as:
In which, denotes the cross-entropy loss of model for an input pair . The expectation is taken over the independent uniformly random choices of , and layer of models and .
In short, is misfeatured as (while similar to visually) by layer in model , by feeding it to model and calculating the loss of output respect to , the transferability of it can be evaluated and vice versa.
For each sub-model ,the diversity objective is added in training process:
For better convergence, the equation above is re-formulated as:
The additional objective is now directly encouraging the model to correctly classify the example misfeatured by other models. It also facilitates the correct classification of .
And since the literature discovers that it's not necessary to include the clean data, the problem is further simlified as:
It becomes training the sub-model with adversarial examples generated from other sub-models.
It can be combined with adversarial training:
Algorithm

The strategy is self-explainatory. After the formulation above, the final process is basically using adversarial examples targeted to randomly chosen layer of other sub-models to train the current sub-models in a rotational way.
They average the output probabilities after the soft-max layer of each sub-model to yield the final predictions of ensembles.
Performance
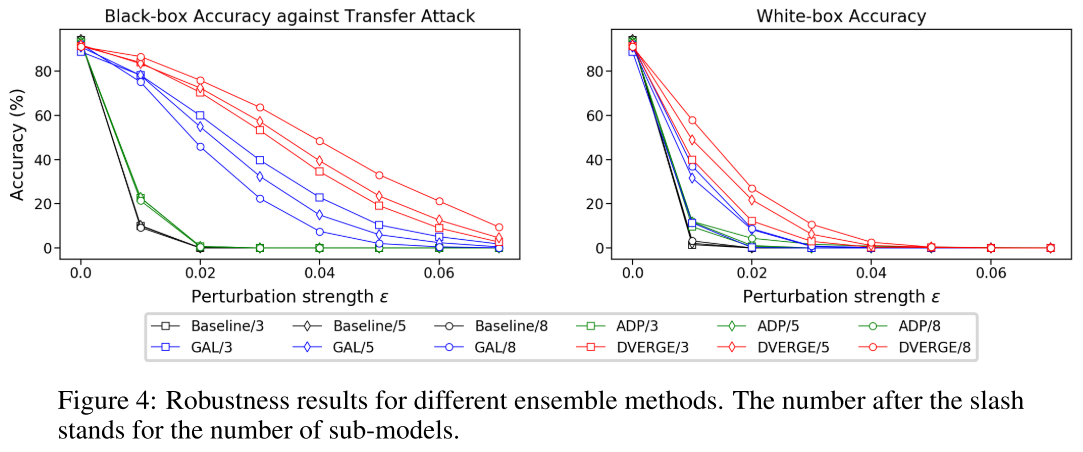
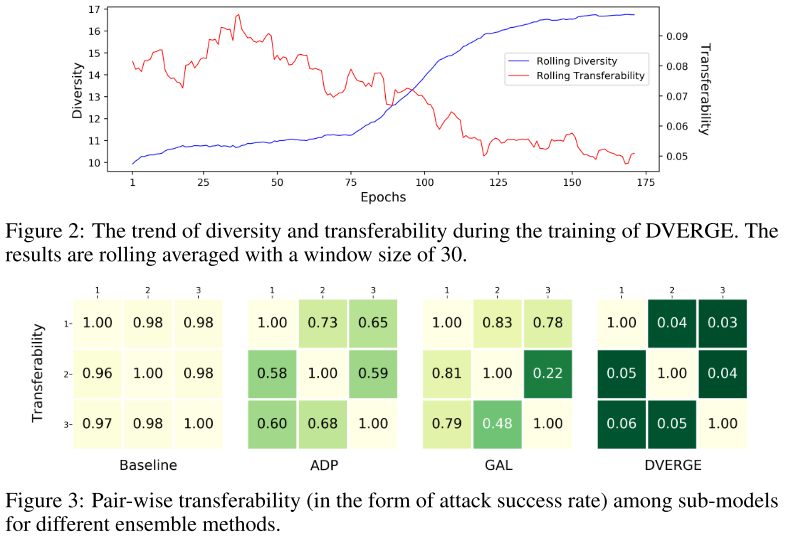
They use ResNet-20 for architecture and CIFAR-10 as dataset for evaluation. As expected, DVERGE reduces the transferability of adversarial exampls among the sub-models.
Although DVERGE achieves the highest robustness among ensemble methods, its robustness against white-box attacks and transfer attacks with a large perturbation strength is still quite low. This result is expected because the objective of DVERGE is to diversify the adversarial vulnerability rather than completely eliminate it.
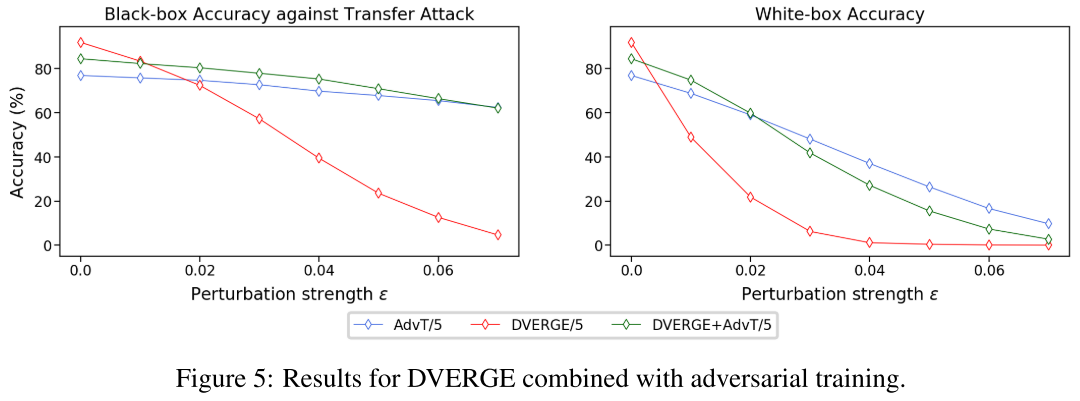
By combining DVERGE and adversarial training, the robustness is further increased.
Inspirations
It's amazing how such a simple training routine (using other sub-models' adversarial examples) is induced from the initiative to magnify the diversity between sub-models.
However, as the Figure 5 shows, DVERGE alone seems to be not that helpful in overall robustness compared to adversarial training.