Adversarial Benchmark
By LI Haoyang 2020.11.10
Content
Adversarial BenchmarkContentBenchmark datasetsImageNet-C&ImageNet-P - ICLR 2019Corruptions and PerturbationsCommon CorruptionsImageNet-CMetricsImageNet-PMetricsExperimentsInspirationsRobustBench - ICLR 2020Threat modelRobustBenchFeaturesRestrictionsInitial setupAdding new defensesAnalysisInspirationsImageNet-A&ImageNet-O - 2020ImageNet-AImageNet-OIllustrative Classifier Failure ModesExperimentsMetricsData AugmentationArchitectural Changes Can HelpInspirationsBenchmark attacksAutoAttack- ICML 2020Adversarial exampleAuto-PGDAlternative loss functionAutoAttackInspirations
Benchmark datasets
ImageNet-C&ImageNet-P - ICLR 2019
Code: https://github.com/hendrycks/robustness
Dan Hendrycks, Thomas G. Dietterich. Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations. ICLR 2019. arXiv:1807.01697
Our first benchmark, IMAGENET-C, standardizes and expands the corruption robustness topic, while showing which classifiers are preferable in safety-critical applications.
Then we propose a new dataset called IMAGENET-P which enables researchers to benchmark a classifier’s robustness to common perturbations
Corruptions and Perturbations
Consider the following objects:
- A classifier
- Data distribution
- A set of corruption functions
- A set of perturbation functions
- Real-world frequency of corruptions and perturbations ,
Most classifiers are judged by their accuracy on test queries drawn from , i.e.
The corruption robustness of the classifier is
The adversarial robustness is a worst-case evaluation
The perturbation robustness is defined as
which is an average evaluation.
They collect a series of frequently encountered corruptions and perturbations to approximate the set and .
Common Corruptions
The corruptions they use include:
Gaussian noise
This corruption can appear in low-lighting conditions.
Shot noise (Poisson noise)
It is electronic noise caused by the discrete nature of light itself.
Impulse noise
It is a color analogue of salt-and-pepper noise and can be caused by bit errors.
Defocus blur
It occurs when an image is out of focus.
Frosted Glass Blur
It appears with “frosted glass” windows or panels.
Motion blur
It appears when a camera is moving quickly.
Zoom blur
It occurs when a camera moves toward an object rapidly.
Snow
It is a visually obstructive form of precipitation.
Frost
It forms when lenses or windows are coated with ice crystals.
Fog
It shrouds objects and is rendered with the diamond-square algorithm.
Brightness
It varies with daylight intensity.
Contrast
It can be high or low depending on lighting conditions and the photographed object’s color.
Elastic
This transformations stretch or contract small image regions.
Pixelation
It occurs when upsampling a lowresolution image.
JPEG
It is a lossy image compression format which introduces compression artifacts.
So many noises.
ImageNet-C

The IMAGENET-C benchmark consists of 15 diverse corruption types applied to validation images of ImageNet.
The corruptions are drawn from four main categories— noise, blur, weather, and digital—as shown in Figure 1.
Each corruption type has five levels of severity since corruptions can manifest themselves at varying intensities.

Our benchmark tests networks with IMAGENET-C images, but networks should not be trained on these images.
Metrics
For each corruption, first compute the Corruption Error over 5 severities standardized by that of AlexNet, i.e.
And the mCE is then computed as the average of the 15 Corruptions Error values corresponding to 15 types of corruptions.
The Relative mCE is the average of the following over 15 corruptions:
This measures the relative robustness or the performance degradation when encountering corruptions.
ImageNet-P

IMAGENET-P departs from IMAGENET-C by having perturbation sequences generated from each ImageNet validation image.
Each sequence contains more than 30 frames, so we counteract an increase in dataset size and evaluation time by using only 10 common perturbations.
However the remaining perturbation sequences have temporality, so that each frame of the sequence is a perturbation of the previous frame.
The perturbation sequences with temporality are created with motion blur, zoom blur, snow, brightness, translate, rotate, tilt (viewpoint variation through minor 3D rotations), and scale perturbations.
Metrics
For perturbation sequences,i.e.
Each element is a sequence of examples with different severities of the th perturbation.
The Flip Probability of network on perturbation sequences for a certain type of perturbation is
Since is clean, the FP formula for noise sequences is
This metric calculates how many perturbed examples are classified correctly.
The Flip Rate is than defined as the standardized FP, i.e.
The mFR is then acquired by averaging the FR across all perturbations.
Denote the ranked predictions of network on be the permutation .
They define
in which . If the top-5 predictions represented within and are identical.
The unstandardized Top-5 Distance is the sum of top-5 distances across the entire perturbation sequences, i.e.
Similarly, for noise perturbation sequences,
and the standardized Top-5 Distance:
The mT5D is then acquired by averaging the Top-5 Distance.
Experiments
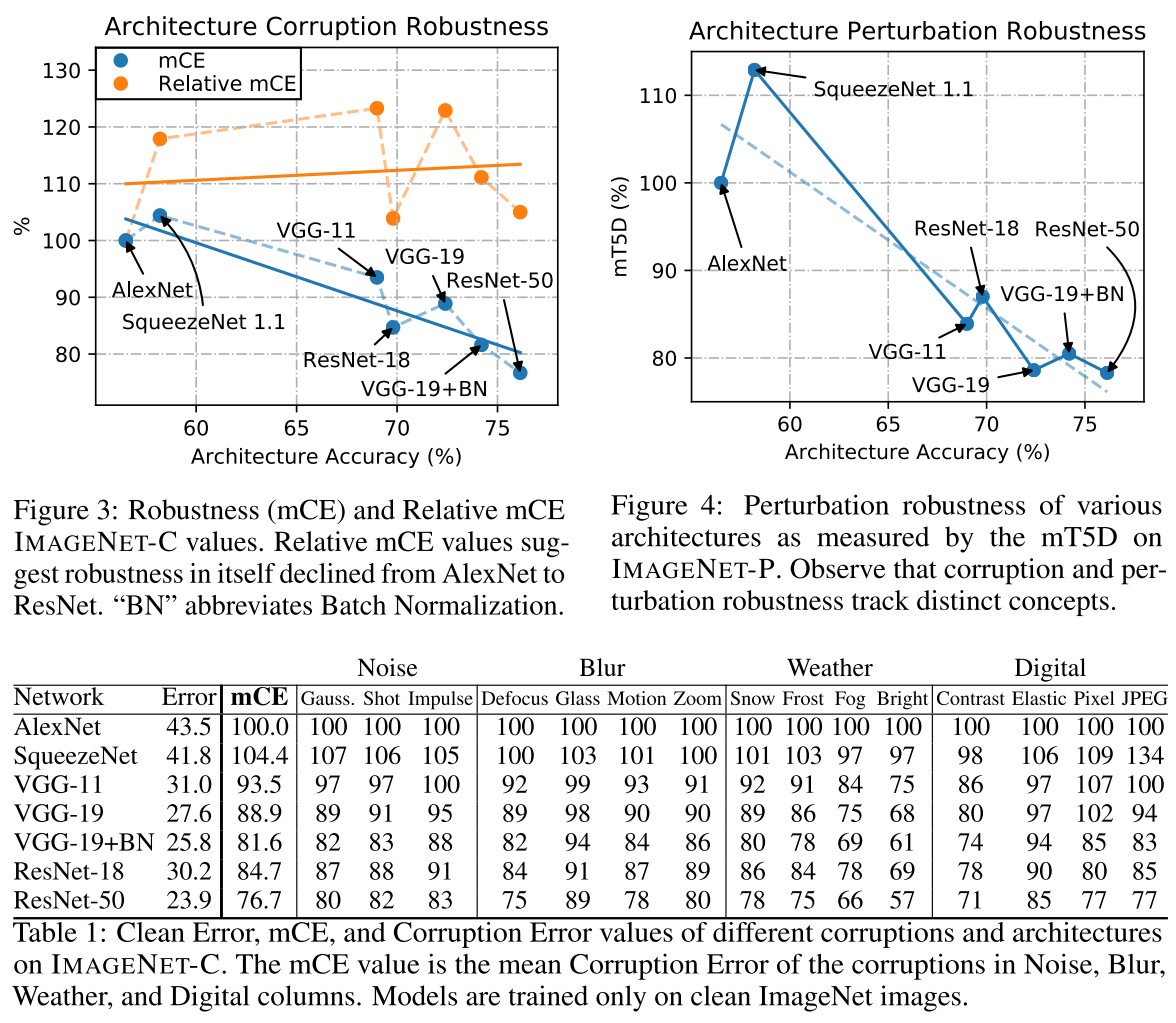
They test the robustness of different architectures, and discover that the recent architectures have better robustness, although it can be explained by the improvement of accuracy.
On perturbed inputs, current classifiers are unexpectedly bad. For example, a ResNet-18 on Scale perturbation sequences have a 15.6% probability of flipping its top-1 prediction between adjacent frames (i.e., ); the is 3.6.
Clearly perturbations need not be adversarial to fool current classifiers.
They also study some robustness enhancement methods.
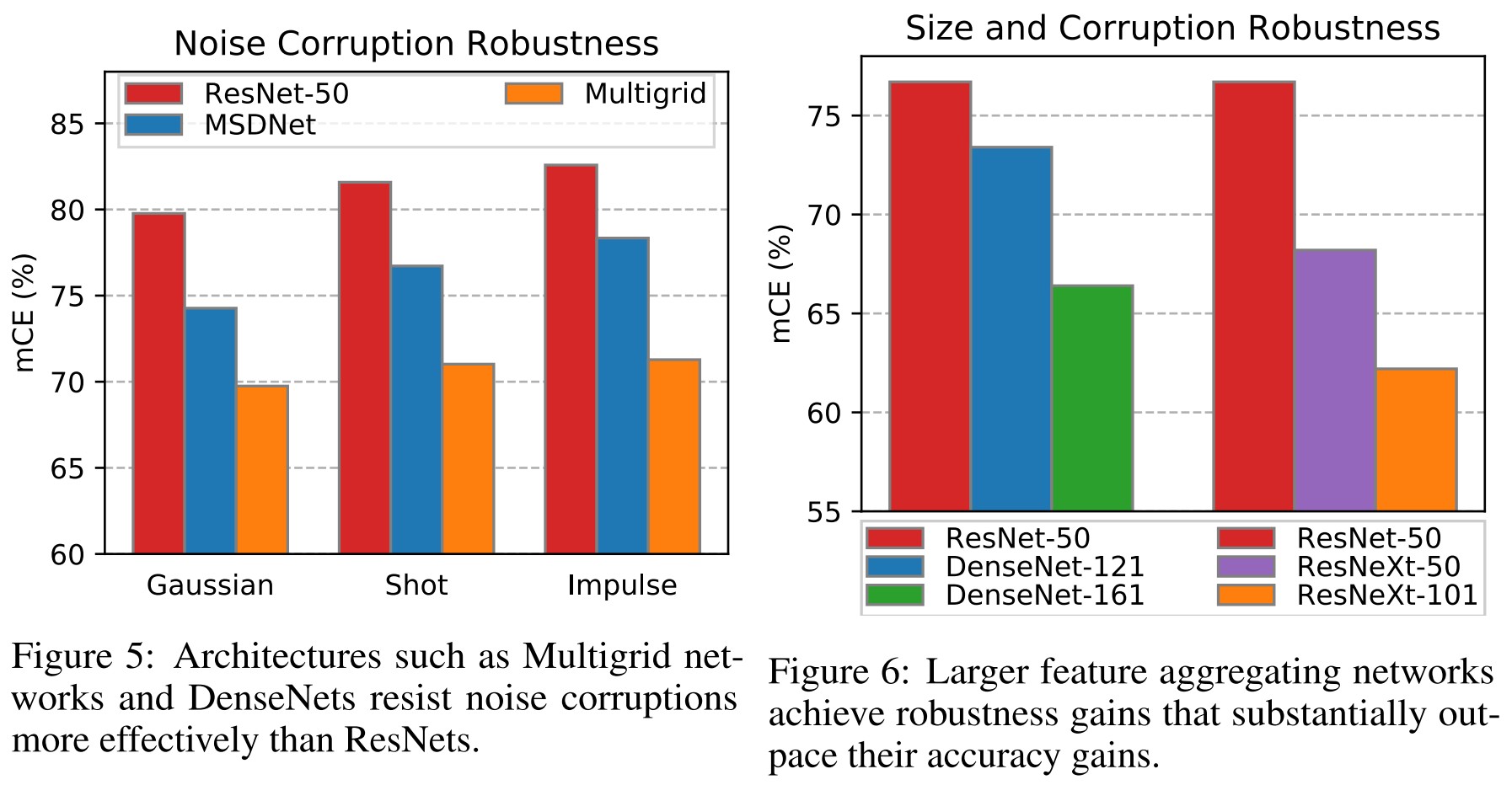
They discover that multiscale network, feature aggregation and larger network enhances the robustness.
Apparently more representations, more redundancy, and more capacity allow these massive models to operate more stably on corrupted inputs.
Training on Stylized ImageNet also helps.
When a ResNet-50 is trained on typical ImageNet images and stylized ImageNet images, the resulting model has an mCE of 69.3%, down from 76.7%.
And Adversarial Logit Pairing helps a lot.
ALP provides significant perturbation robustness even though it does not provide much adversarial perturbation robustness against all adversaries.
In point of fact, a publicly available Tiny ImageNet ResNet-50 model fine-tuned with ALP has a 41% and 40% relative decrease in the mFP and mT5D on TINY IMAGENET-P, respectively.
Inspirations
This is an ineteresting benchmark although the metrics are designed too complicated.
RobustBench - ICLR 2020
Leaderboard: https://robustbench.github.io/
Code: http://github.com/RobustBench/robustbench
Francesco Croce, Maksym Andriushchenko, Vikash Sehwag, Nicolas Flammarion, Mung Chiang, Prateek Mittal, Matthias Hein. RobustBench: a standardized adversarial robustness benchmark. ICLR 2020. arXiv:2010.09670
Our goal is to establish a standardized benchmark of adversarial robustness, which as accurately as possible reflects the robustness of the considered models within a reasonable computational budget.
They adopt the AutoAttack to benchmark SOTA classifiers, while ruling out the following methods:
- Classifiers which have zero gradients with respect to the input (likely gradient masking)
- Randomized classifiers (likely gradient masking)
- Classifiers that contain an optimization loop in their predictions
Threat model
They adopt a fully white-box setting, i.e. the model is assumed to be fully known to the attacker.
The allowed perturbations they adopt is the widely used -perturbations, i.e.
and particularly for .
The definition of successful adversarial perturbation they use is:
Let be an input point and be its correct label. For a classifier , a successful adversarial perturbation with respect to the perturbation set is defined as a vector such that
The perturbation set is typically chosen such that all points in have as their true label.
The robust accuracy is the fraction of data points on which the classifier predicts the correct class for all possible perturbations from the set .
RobustBench
Features
- A baseline worst-case evaluation with an ensemble of strong, standardized attacks which includes both white- and black-box attacks that can be optionally extended by adaptive evaluations
- Clearly defined threat models that correspond to the ones used during training for submitted defenses
- Evaluation of not only standard defenses, but also of more recent improvements.
- The Model Zoo that provides convenient access to the most robust models from the literature which can be used for downstream tasks and facilitate the development of new standardized attacks
Restrictions
Only the classifier satisfying the following requirements are considered:
- have in general non-zero gradients with respect to the inputs
- have a fully deterministic forward pass
- do not have an optimization loop in the forward pass
Initial setup
Adding new defenses
We require new entries to
- satisfy the three restrictions formulated at the beginning of this section
- to be accompanied by a publicly available paper (e.g., an arXiv preprint) describing the technique used to achieve the reported results
- make checkpoints of the models available
The detailed instructions for adding new models can be found in our repository https://github.com/RobustBench/robustbench.
Analysis
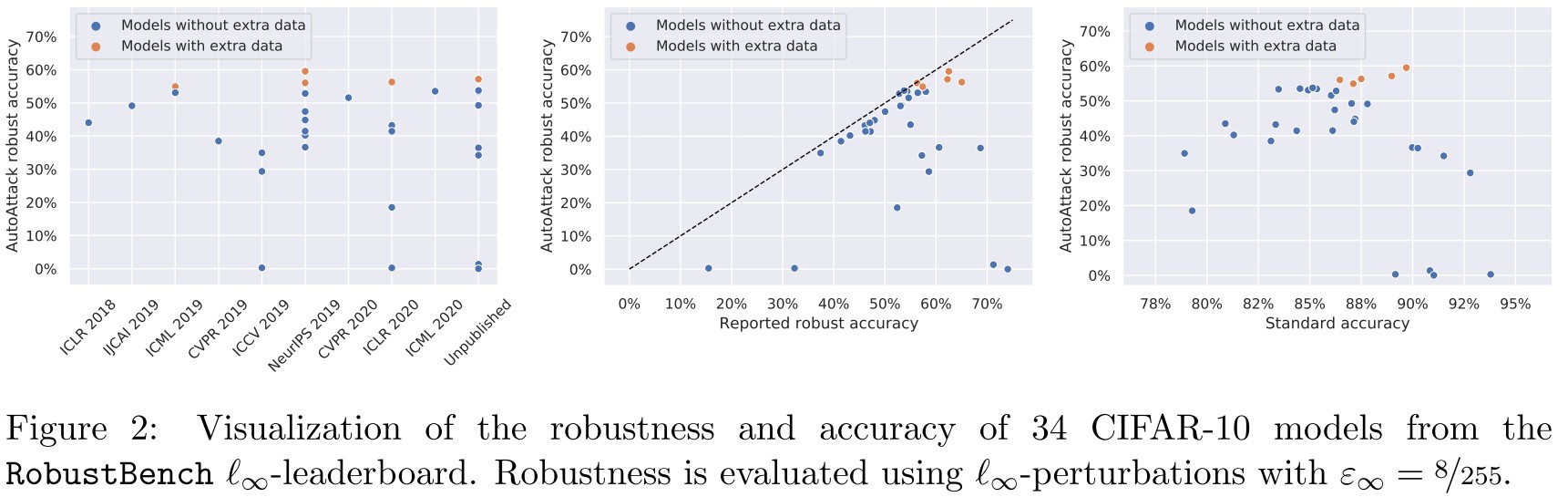
As shown in Figure 2
- We observe that for multiple published defenses, the reported robust accuracy is highly overestimated
- We also find that the use of extra data is able to alleviate the robustness-accuracy trade-off as suggested in previous work
- Finally, it is interesting to note that the best entry of the -leaderboard (Carmon et al., 2019) is PGD adversarial training (Madry et al., 2018) enhanced only by using extra data (obtained via self-training with a standard classifier)
They test the performance of models across various distributional shift.
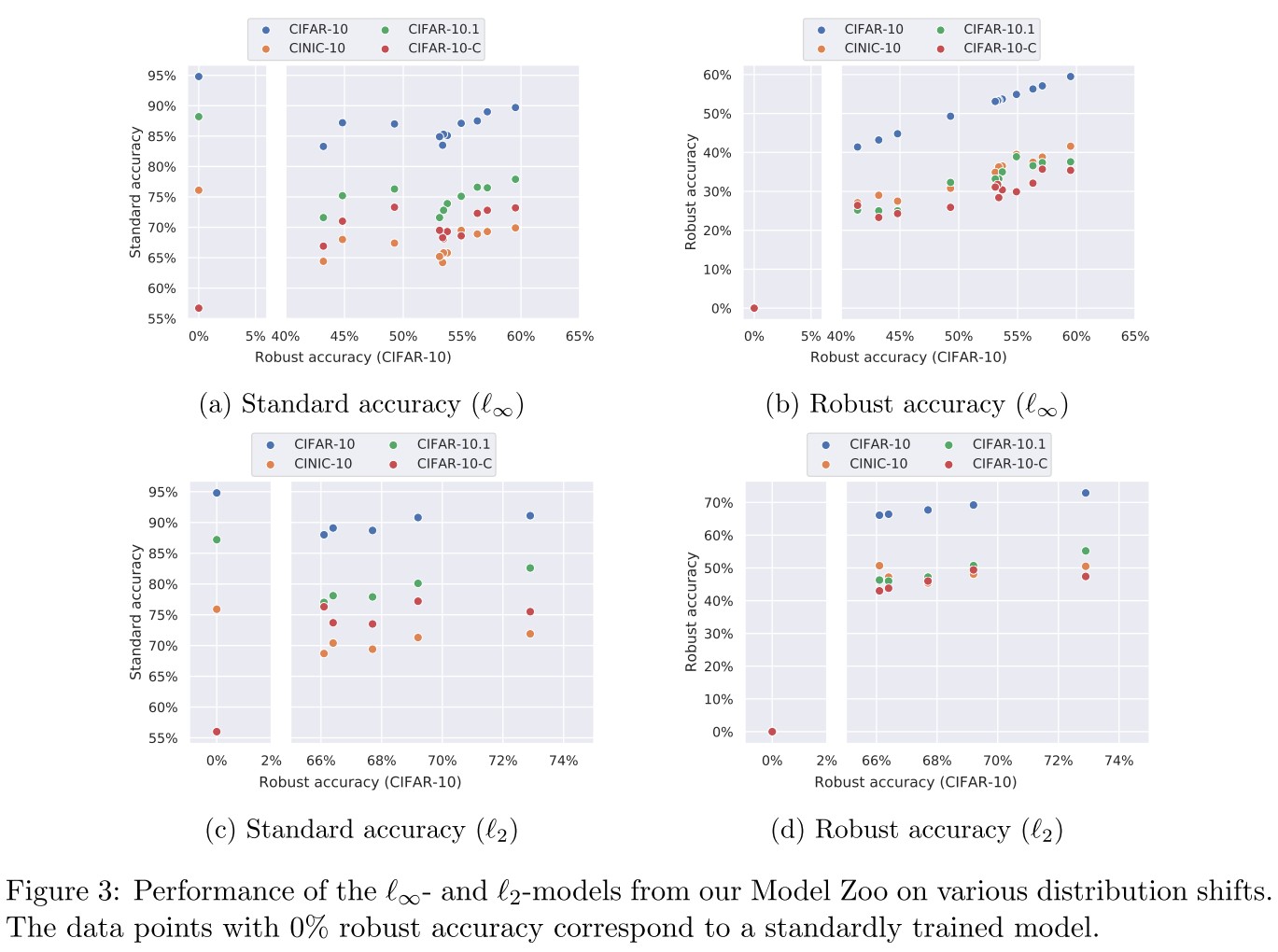
As shown in Figure 3
- Robust networks have a similar trend in terms of the performance on these datasets as a standardly trained model
- On CIFAR-10-C, robust models (particularly with respect to the -norm) tend to give a significant improvement which agrees with the findings from the previous literature
And they also test the performance of out-of-distribution detection of models.
Ideally, a classifier should exhibit uncertainty in its predictions when evaluated on out-of-distribution (OOD) inputs.
In particular, Song et al. (2020) demonstrated that adversarial training (Madry et al., 2018) leads to degradation in the robustness against OOD data.
We use the area under the ROC curve (AUROC) to measure the success in the detection of OOD data.
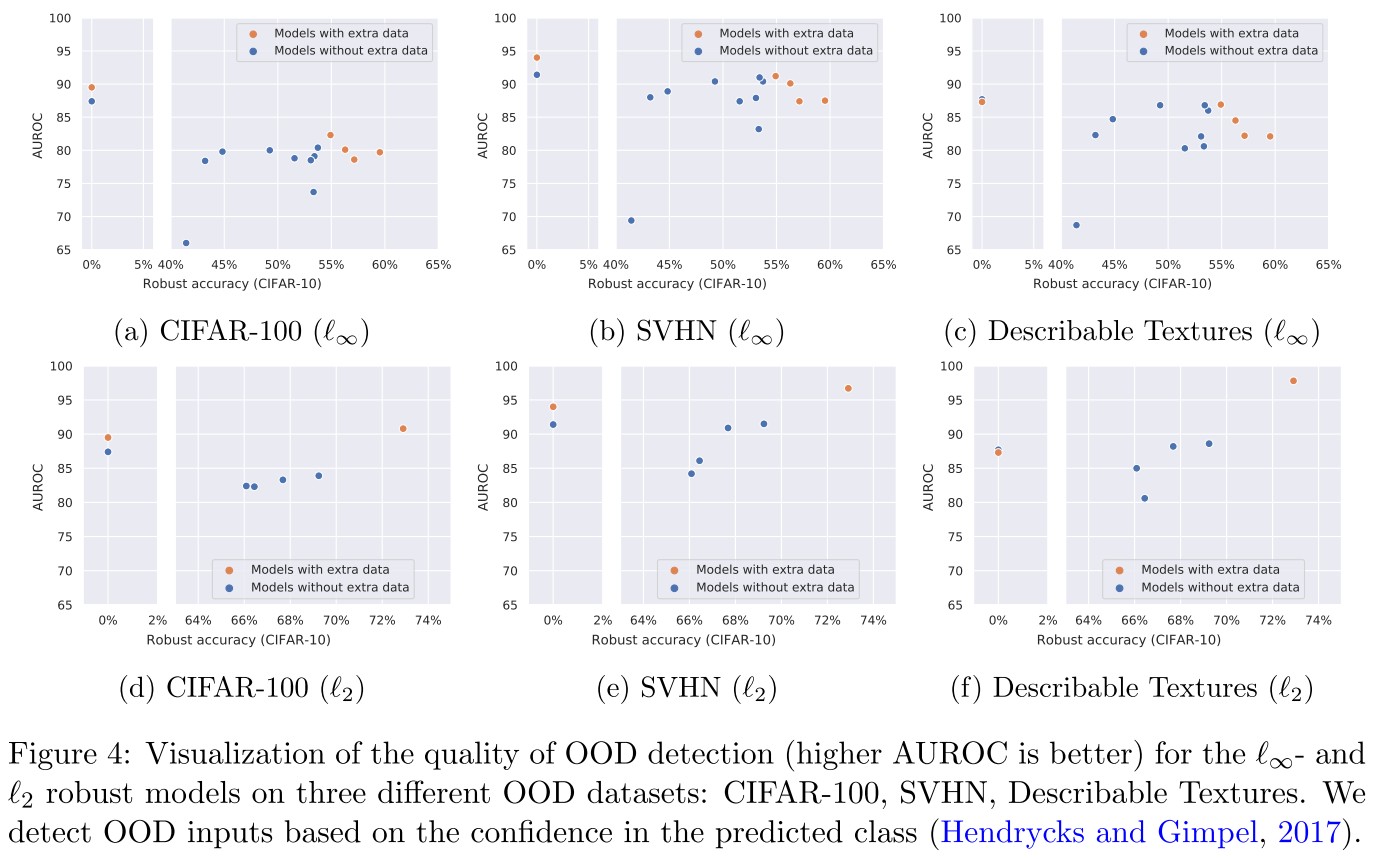
As shown in Figure 4
- We find that compared to standard training, various robust training methods indeed lead to degradation of the OOD detection quality
- With progress on robust accuracy, we find that robustness against OOD data plateaus and the use of extra data does not change this trend substantially.
This is expected, if adversarial examples and clean examples are from different distributions, then an adversarially robust model is expected to show worse performance in OOD detection quality.
Inspirations
This is a good benchmark.
ImageNet-A&ImageNet-O - 2020
Code: https://github.com/hendrycks/natural-adv-examples
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, Dawn Song. Natural Adversarial Examples. arxiv preprint 2020. arXiv:1907.07174
We introduce natural adversarial examples–real-world, unmodified, and naturally occurring examples that cause machine learning model performance to substantially degrade.
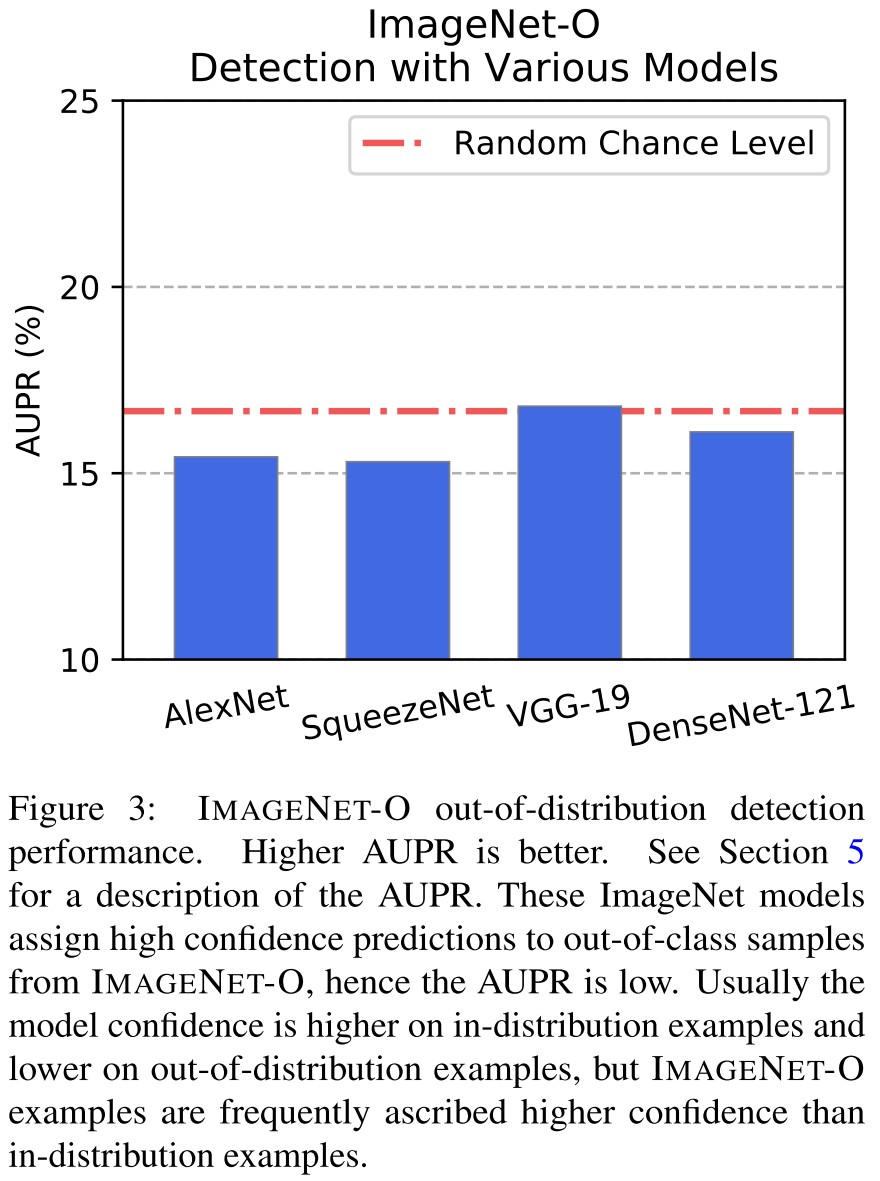
For example, on IMAGENET-A a DenseNet-121 obtains around 2% accuracy, an accuracy drop ofapproximately 90%, and its out-of-distribution detection performance on IMAGENET-O is near random chance levels.
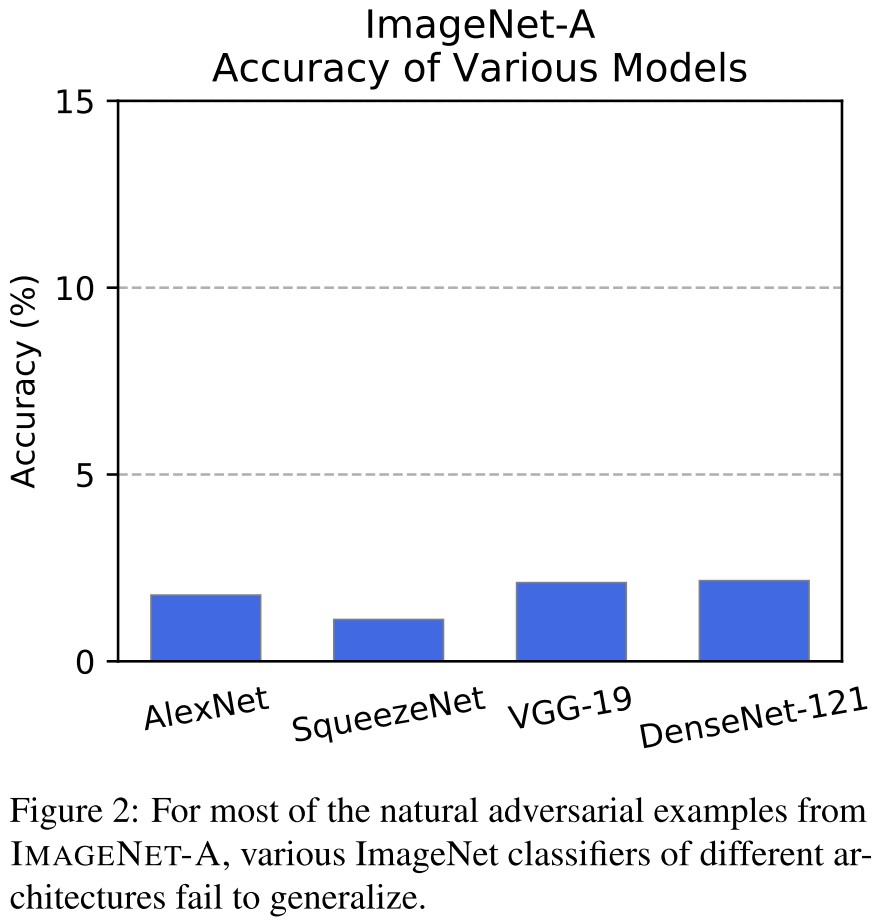



ImageNet-A
IMAGENET-A is a dataset of natural adversarial examples for ImageNet classifiers, or real-world examples that fool current classifiers
They first download numerous images related to an ImageNet class and delete the images that ResNet-50 classifiers correctly predict.
We select a 200-class subset of ImageNet-1K’s 1,000 classes so that errors among these 200 classes would be considered egregious.
They drop those classes that are two similar or old-fashioned.
ImageNet-O
Next, IMAGENET-O is a dataset of natural adversarial examples for ImageNet out-of-distribution detectors.
They download ImageNet-22K and delete examples from ImageNet-1K to create this dataset. For the remaining examples, they only keep examples that are classified by a ResNet-50 as an ImageNet-1K class with high confidence.
We again select a 200class subset of ImageNet-1K’s 1,000 classes. These 200 classes determine the in-distribution or the distribution that is considered usual.
Illustrative Classifier Failure Modes

Classifiers may wrongly associate class with shape, color, texture or background, and they also demonstrate fickleness to small scene variations (e.g. the alligator in the down center of Figure 7, small variations induce different predictions).
Classifiers may also overgeneralize cues as demonstrated in the right down of Figure 7.
Experiments
Metrics
Our metric for assessing robustness to natural adversarial examples for classifiers is the top-1 accuracy on IMAGENET-A
Our metric for assessing out-of-distribution detection performance of NAEs is the area under the precision-recall curve (AUPR).
Data Augmentation
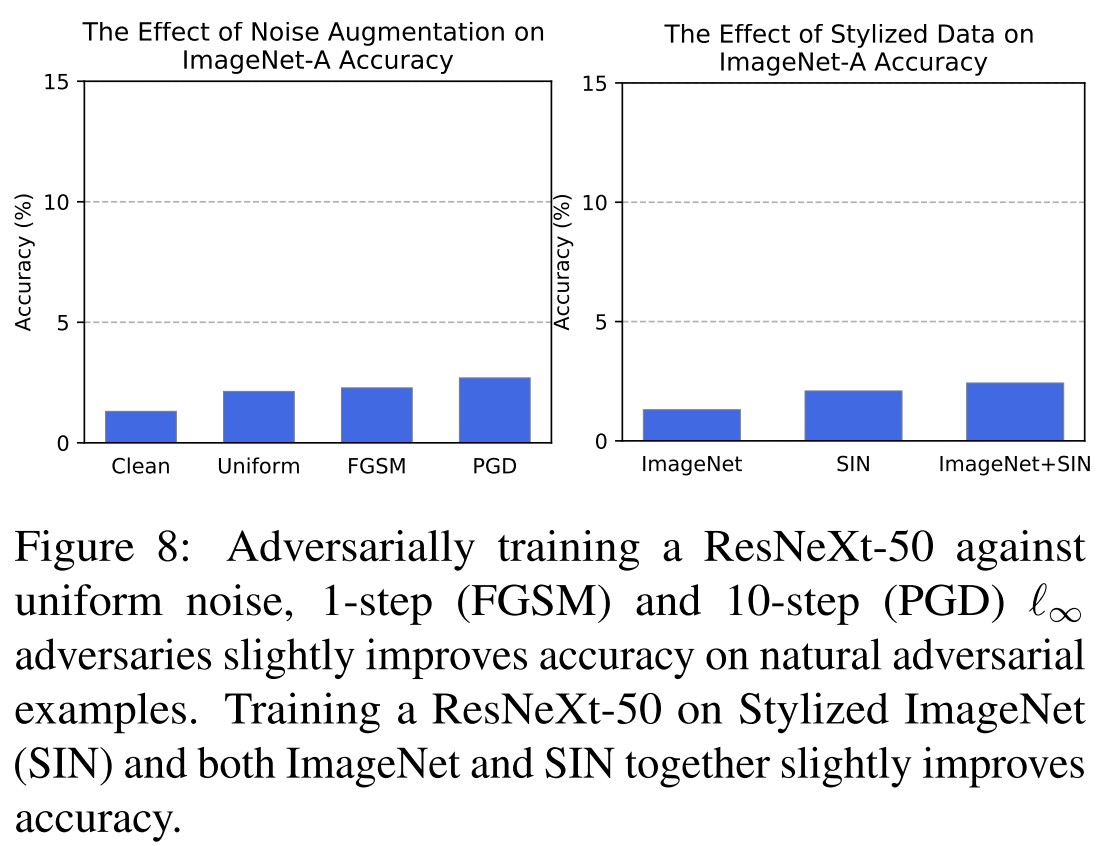
As shown in Figure 8, adversarial training hardly help and Reducing a ResNeXt-50’s texture bias by training with SIN (Stylized ImageNet) images does little to improve IMAGENET-A accuracy.
Architectural Changes Can Help
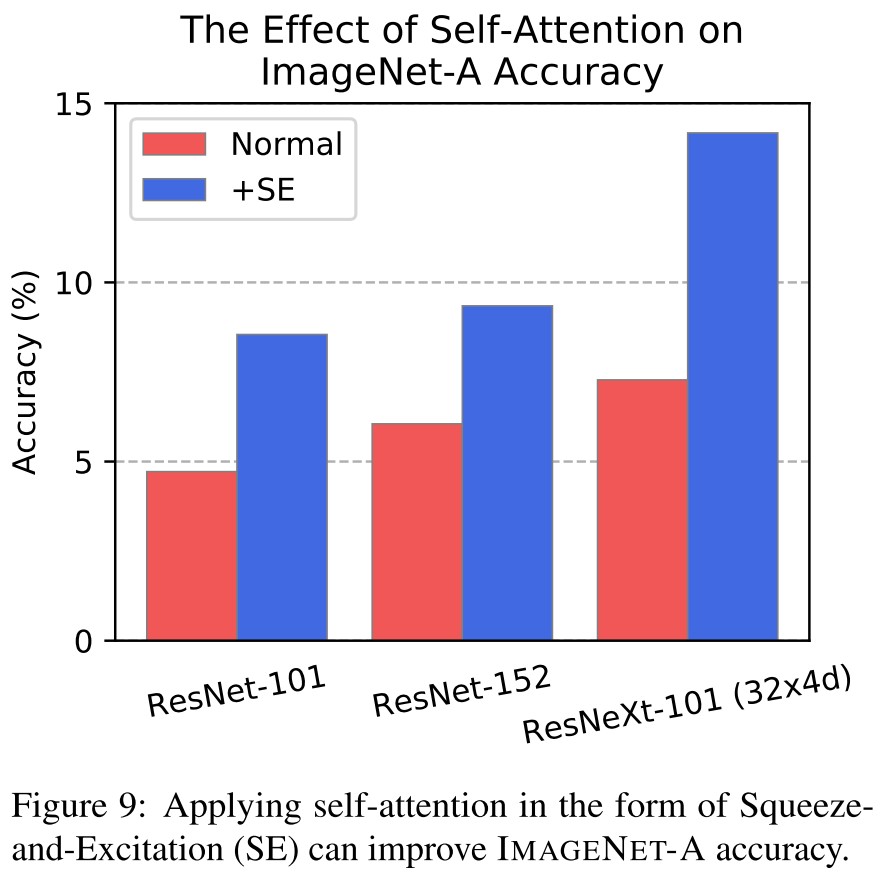
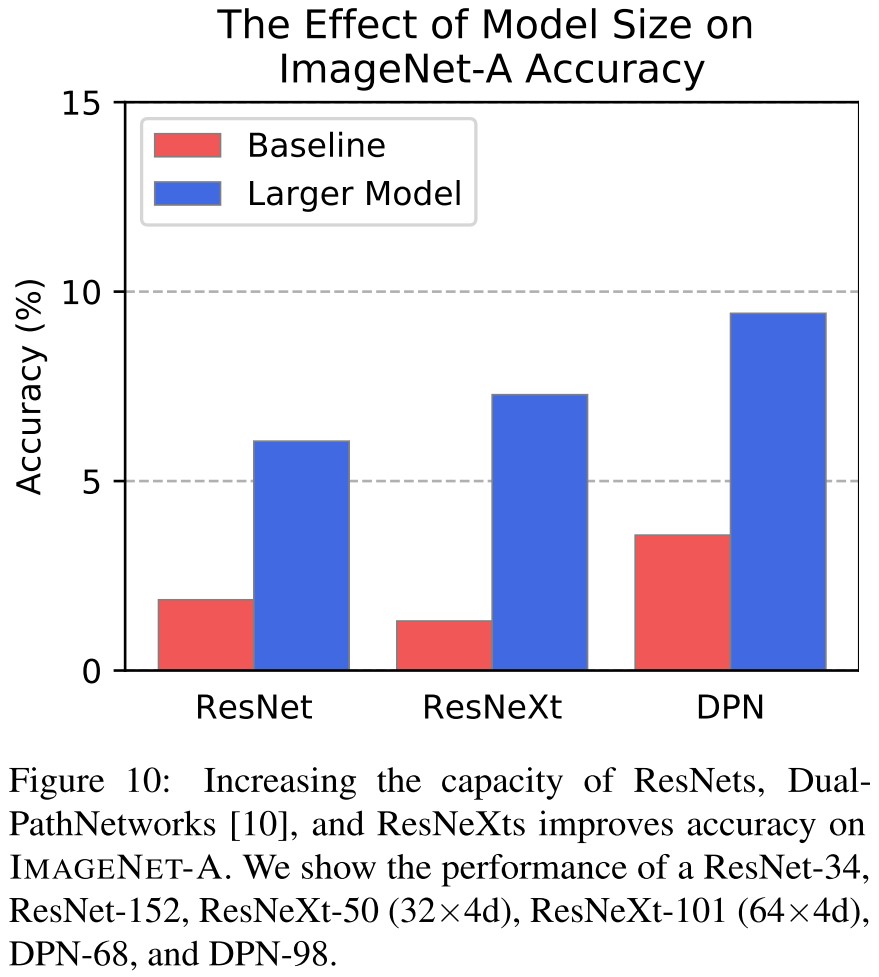
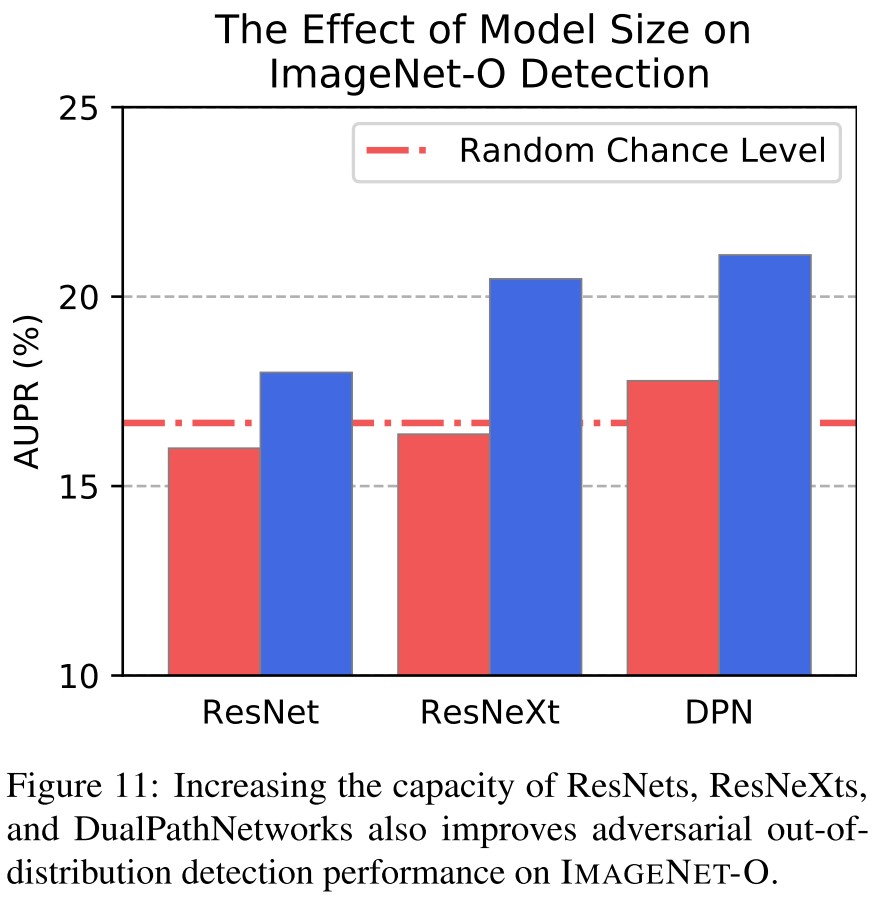
Inspirations
This dataset surely worth further exploration, but I think it's a little harsh on the classifier, especially as they set the metric as top-1 accuracy.
Benchmark attacks
AutoAttack- ICML 2020
Code: https://github.com/fra31/auto-attack
Francesco Croce, Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. ICML 2020. arXiv:2003.01690
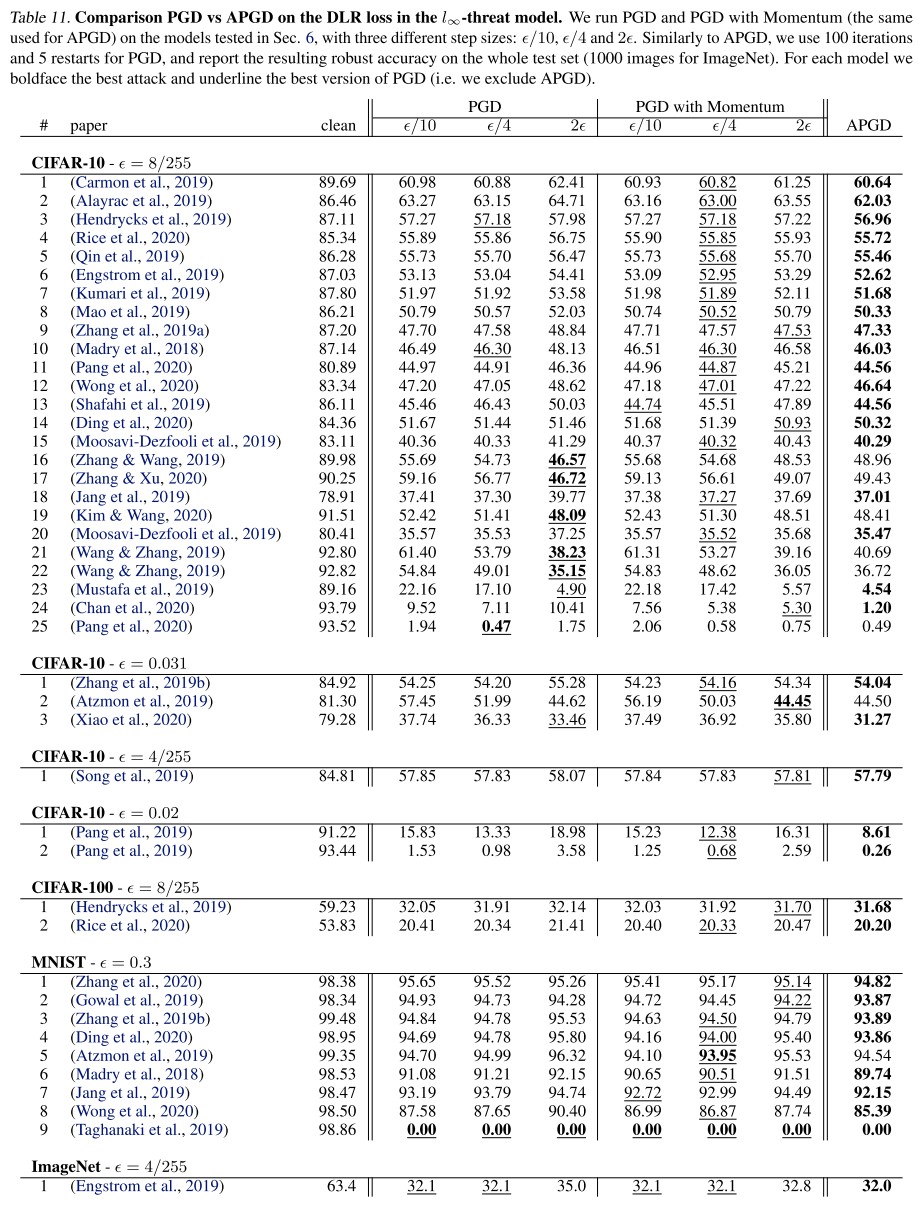
In this paper we first propose two extensions of the PGD-attack overcoming failures due to suboptimal step size and problems of the objective function.
The evaluation of proposed defenses is incomplete, hence leading a wrong impression of robustness. They modify the PGD attack to be parameter-free and propose to use it for evaluation.
They identify the fixed step size and the widely used cross-entropy loss as two major reasons for the failures of PGD and introduce more types of attacks to enrich the diversity, proposing a paremeter-free AutoAttack as an evaluation bench.
Adversarial example
The original mathematical forms are reformed here.
For a -class classifier taking decisions according to
Assume is correctly classified as by .
Given a metric and , the threat model (attack space) is defined as
For image classification, a popular threat model is based on -norm, i.e.
A data point is an adversarial example for at w.r.t the threat model if
To find , it's common to define some surrogate function and solve the constrained optimization problem
This can be solved using Projected Gradient Descent (PGD) iterative, with the th step as
given an objective (surrogate function) . At each step, projects the perturbed data point back to the attack space.
In the formulation proposed by Madry et al. The step size is fixed, i.e. and the initial point is either or , i.e. a random start point in the attack space.
Auto-PGD
They claim three drawbacks of initial PGD:
- Suboptimal fixed step size
- Budget agnostic overall scheme
- Unaware of the trend (i.e. agnostic of the current situation of the optimization process)

They propose to add a momentum term for the update:
And add two conditions to decide when to restore the recorded best point and decay the step size:
- and
Condition 1 counts in how many cases since the last checkpoint the update step has been successful in increasing . If this holds for a fraction of total update steps since last checkpoints, then the step size is considered properly to be kept and the condition will be false.
Condition 2 holds true if without step size adjustment, the objective is not increased since last checkpoint.
If one of the conditions above hold true, the data point is restarted at the best one with the step size halved, i.e.
This leaves only one free variable, i.e. the number of iterations .
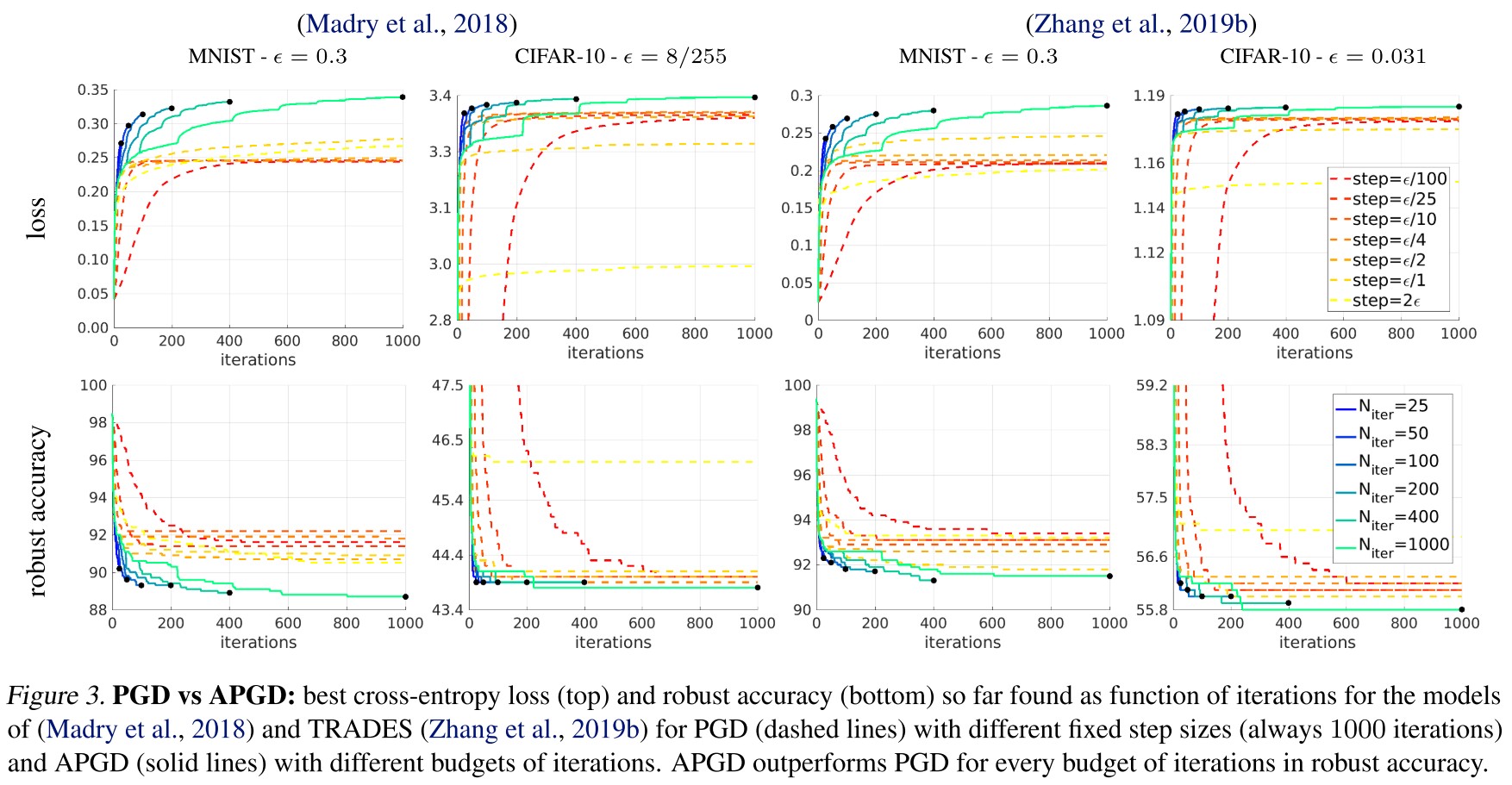
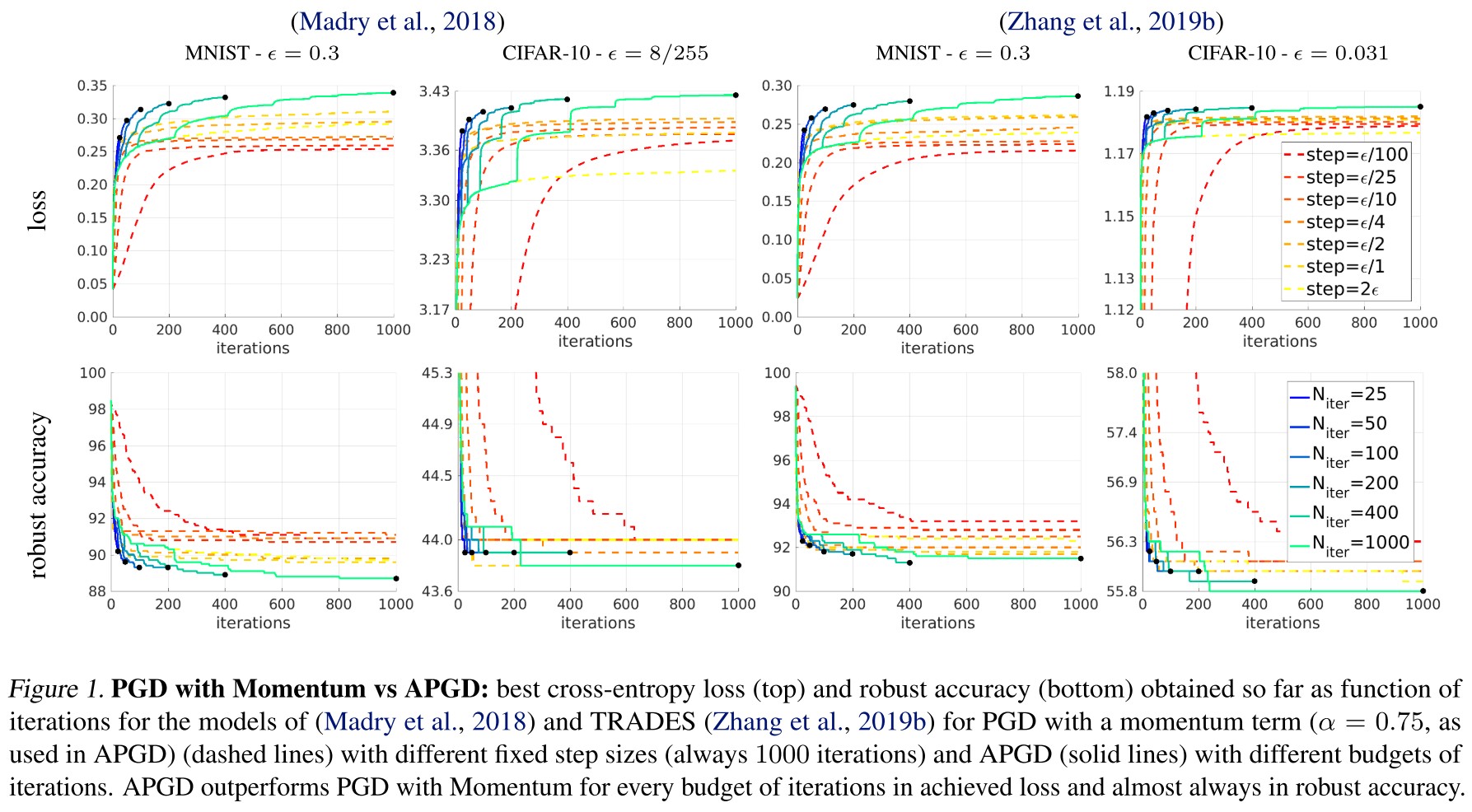
Alternative loss function
The widely used cross-entropy loss is affected by the scale of logits, i.e. small logits cause gradient vanishing (due to the finite arithmetic).
They test the robust accuracy by simply dividing the logits by a factor .
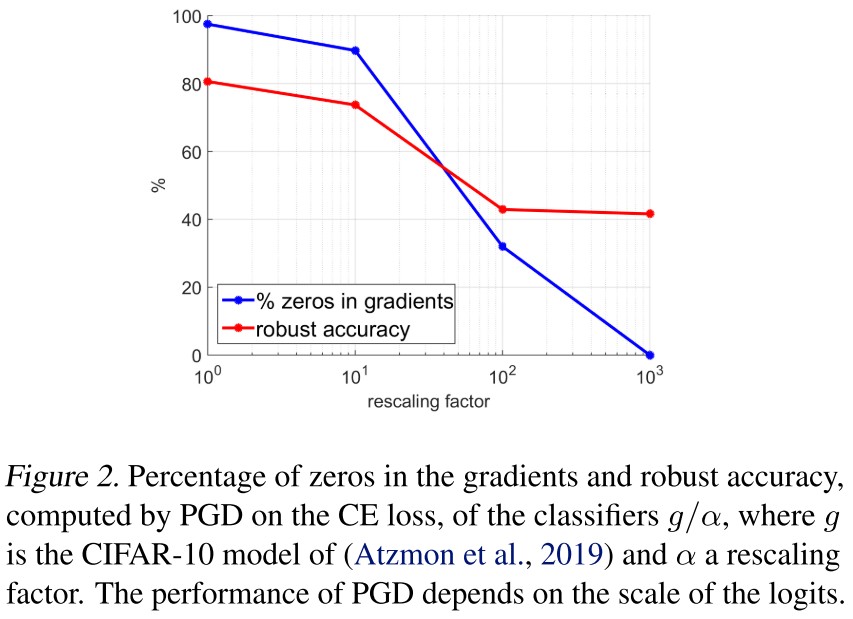
As shown in Figure 2, without rescaling the gradient vanishes almost for every coordinate, which leads to a relatively overestimated robust accuracy.
They propose the Difference of Logits Ratio (DLR) loss, designed to be both shift and rescaling invariant, i.e.
in which, is the ordering of the components of in decreasing order.
For a classifier, minimizing DLR means to maximize the difference between the correct logit and the second largest logit while keeping the difference to be proportional to be difference of the largest logit and the thrid largest logit.
For adversary, the process is reversed.
And a targeted version
AutoAttack
We combine our two parameter-free versions of PGD, APGDCE and APGDDLR, with two existing complementary attacks, FAB (Croce & Hein, 2020) and Square Attack (Andriushchenko et al., 2020), to form the ensemble AutoAttack.
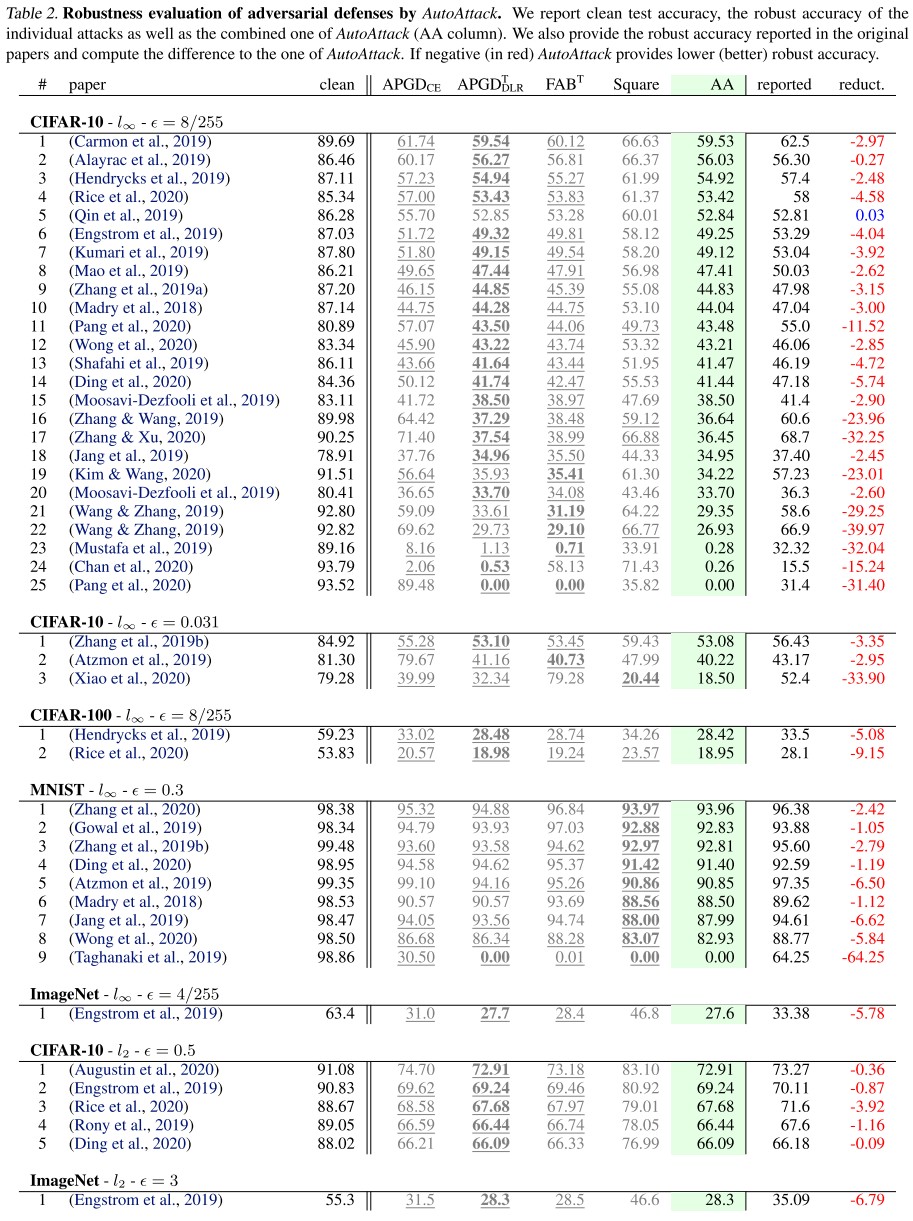
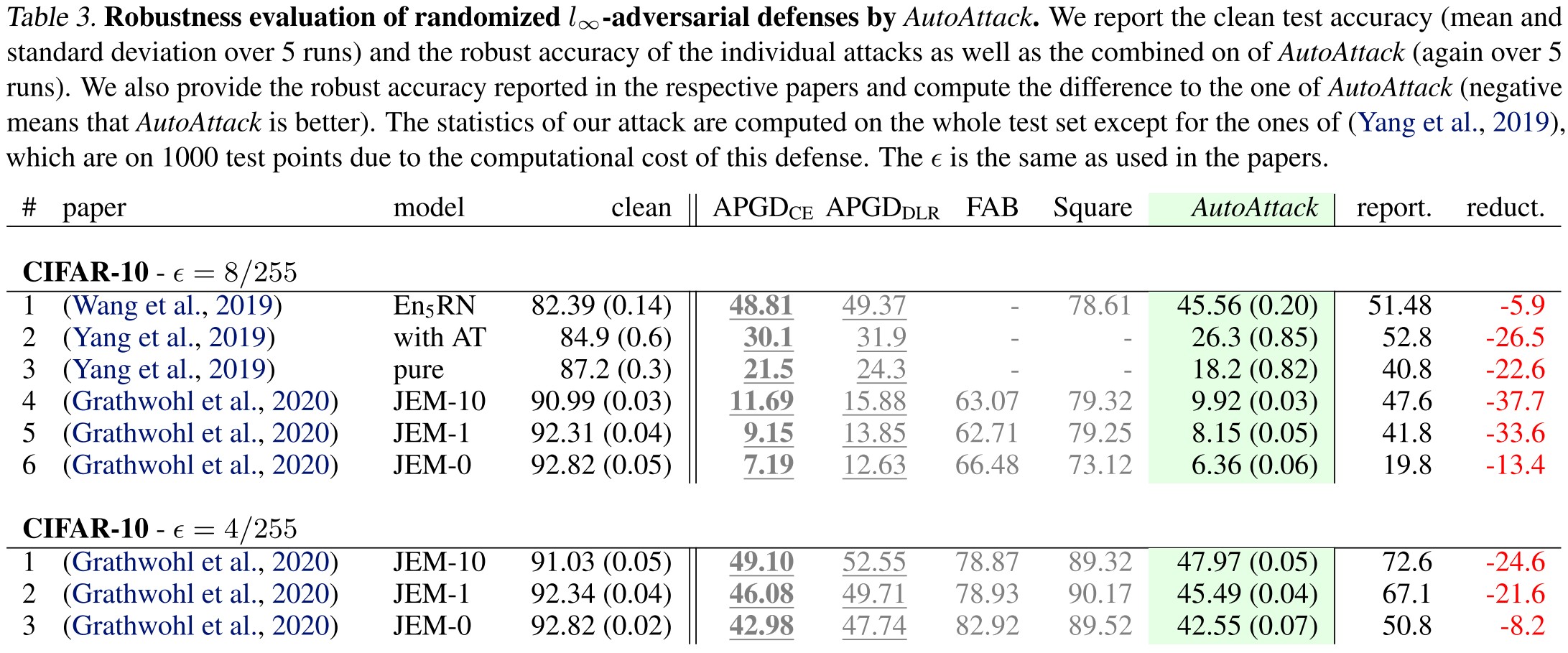
Inspirations
It seems that using unlabeled data is the best approach in CIFAR-10, which leads to the problem of robustness to the direction of data augmentation.