Re-purpose Adversarial Example and Adversarial Robustness
By LI Haoyang 2020.11.6 (branched)
Content
Re-purpose Adversarial Example and Adversarial RobustnessContentAccuracy AugmentationAdversarial Propagation - CVPR 2020MethodologyPerformanceInspirationsTransfer LearningDo Adversarially Robust ImageNet Models Transfer Better? - 2020Fixed-Feature Transfer LearningFull-Network Fine TuningImageNet accuracy and transfer performanceRobust models improve with widthOptimal robustness levels for downstream tasksComparing adversarial robustness to texture robustnessInspiration
Accuracy Augmentation
Adversarial Propagation - CVPR 2020
Cihang Xie, Mingxing Tan, Boqing Gong, Jiang Wang, Alan Yuille, Quoc V. Le. Adversarial Examples Improve Image Recognition. CVPR 2020. arXiv:1911.09665v2
The general belief is that adversarial training will inevitably hurt the model's performance on clean image, however, this paper tries to boost the performance with adversarial examples.
We hypothesize such performance degradation is mainly caused by distribution mismatch—adversarial examples and clean images are drawn from two different domains therefore training exclusively on one domain cannot well transfer to the other.
Methodology
The vanilla training problem is to minimize the expectation of loss function over a underlying data distribution by adjusting parameters in designed model according to labeled data pair and :
The adversarial training adds an inner adversarial perturbation term to it. The goal is then to minimize the average loss over adversarial examples optimally perturbed under certain constraints :
In this paper, they treat adversarial examples as additional training samples and the problem is then become:
However, as observed in former studies [7, 18], directly optimizing Eq. (3) generally yields lower performance than the vanilla training setting on clean images.
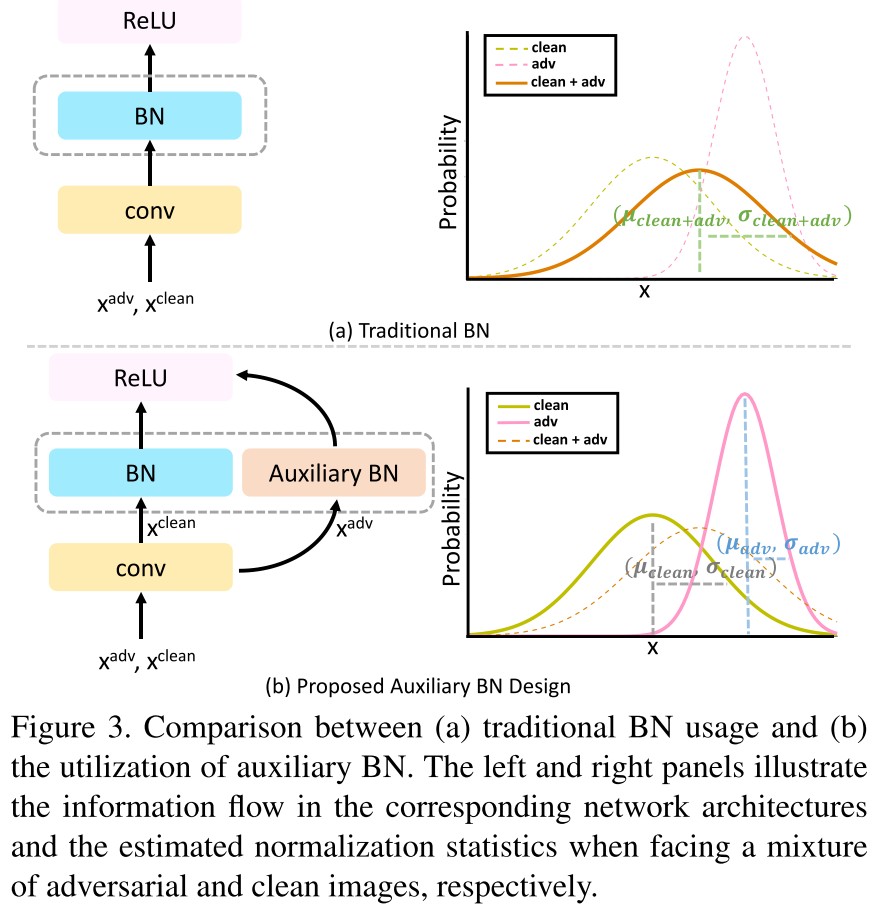

They then hypothesize that the distribution of adversarial examples is different from that of normal examples, hence they should be batch normalized separately. An auxiliary batchnorm branch is introduced to process adversarial examples separately, and dropped in inference.
The strategy is explicit:
For each clean mini-batch , generate a mini-batch of adversarial examples using the auxiliary BNs.
Compute the loss on clean mini-batch using main BNs and the loss on adversarial mini-batch using auxiliary BNs.
Step the optimization of network parameters:
Performance
We choose EfficientNets [41] at different computation regimes as our default architectures, ranging from the light-weight EfficientNet-B0 to the large EfficientNet-B7.
We choose Projected Gradient Descent (PGD) [23] under norm as the default attacker for generating adversarial examples on-the-fly.
They test the performance on ImageNet validation datasets and the following three datasets:
ImageNet-C [9]. The ImageNet-C dataset is designed for measuring the network robustness to common image corruptions [9].
ImageNet-A [10]. The ImageNet-A dataset adversarially collects 7,500 natural, unmodified but “hard” real-world images.
Stylized-ImageNet [6]. The Stylized-ImageNet dataset is created by removing local texture cues while retaining global shape information on natural images via AdaIN style transfer [13].
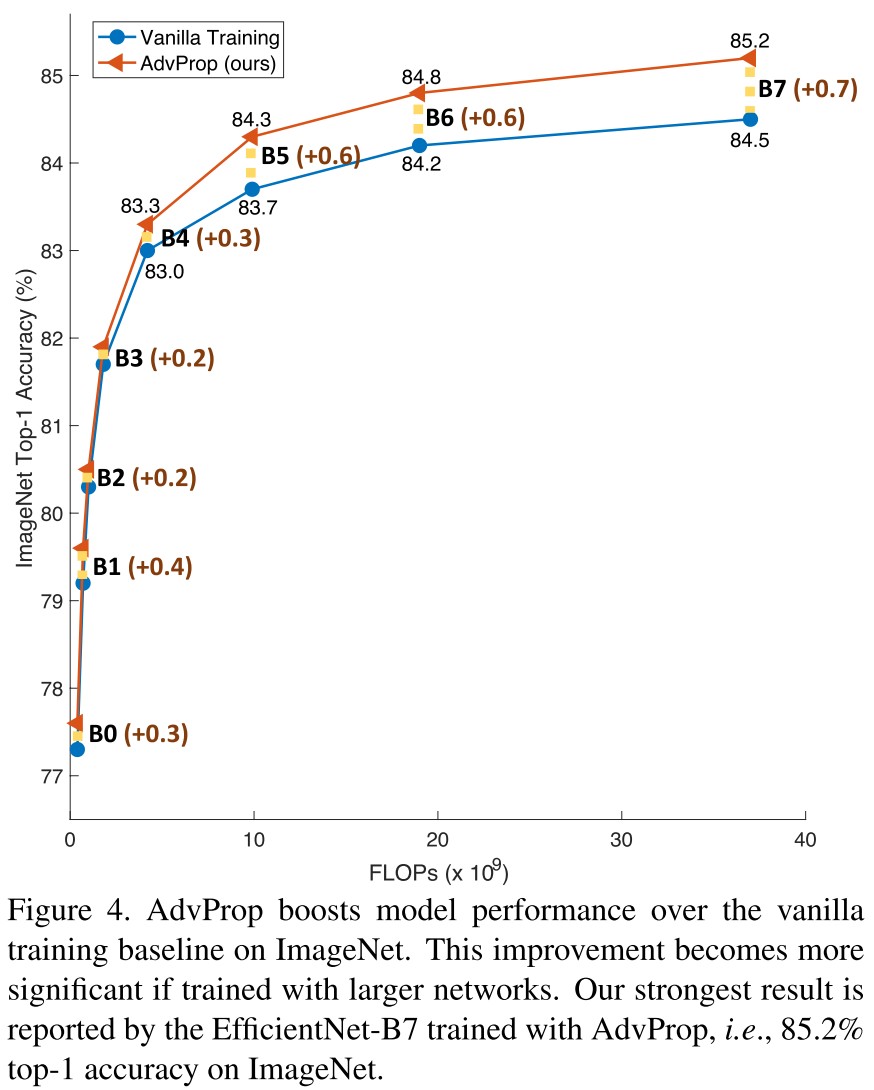
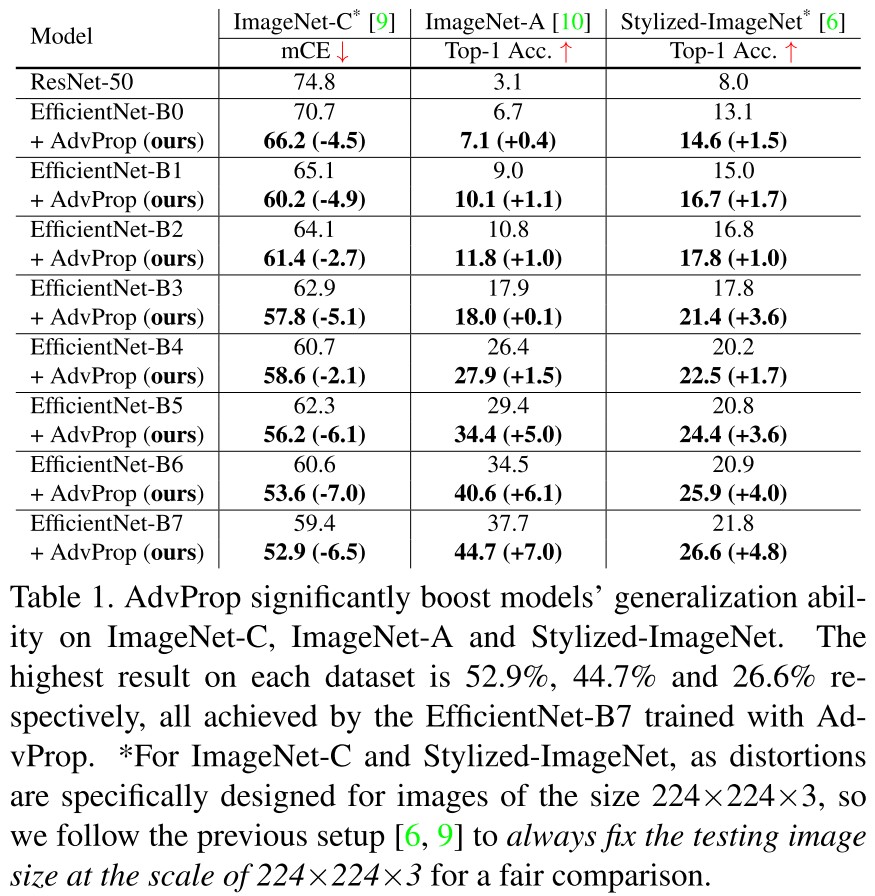
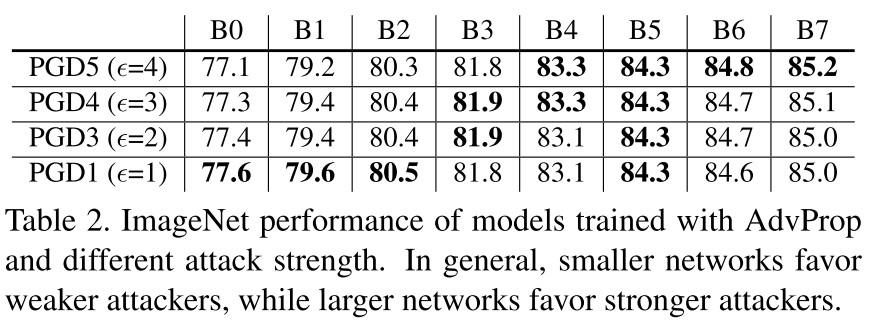
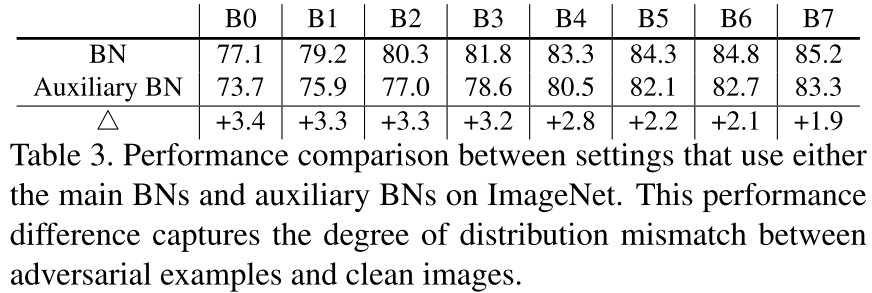
A smaller model favors weaker attack and the difference between using auxiliary BNs and not using reduces when the model grows larger.
In summary, AdvProp enables networks to enjoy the benefits of adversarial examples even with limited capacity.
Inspirations
It's a good idea to use adversarial examples positively, but the proposed method seems a little shaky. The experiments show that with larger capacity, the boosting is reduced. The auxiliary BNs is proposed based on the assumption that the distribution mismatch, yet no experiment is conducted to verify the mismatch. Intuitively, small perturbations should not change the distribution very much, this verification is a potential work to do.
Transfer Learning
Do Adversarially Robust ImageNet Models Transfer Better? - 2020
Code: https://github.com/Microsoft/robust-models-transfer
Hadi Salman, Andrew Ilyas, Logan Engstrom, Ashish Kapoor, Aleksander Madry. Do Adversarially Robust ImageNet Models Transfer Better? arXiv preprint 2020. arXiv:2007.08489
Typically, better pre-trained models yield better transfer results, suggesting that initial accuracy is a key aspect of transfer learning performance.
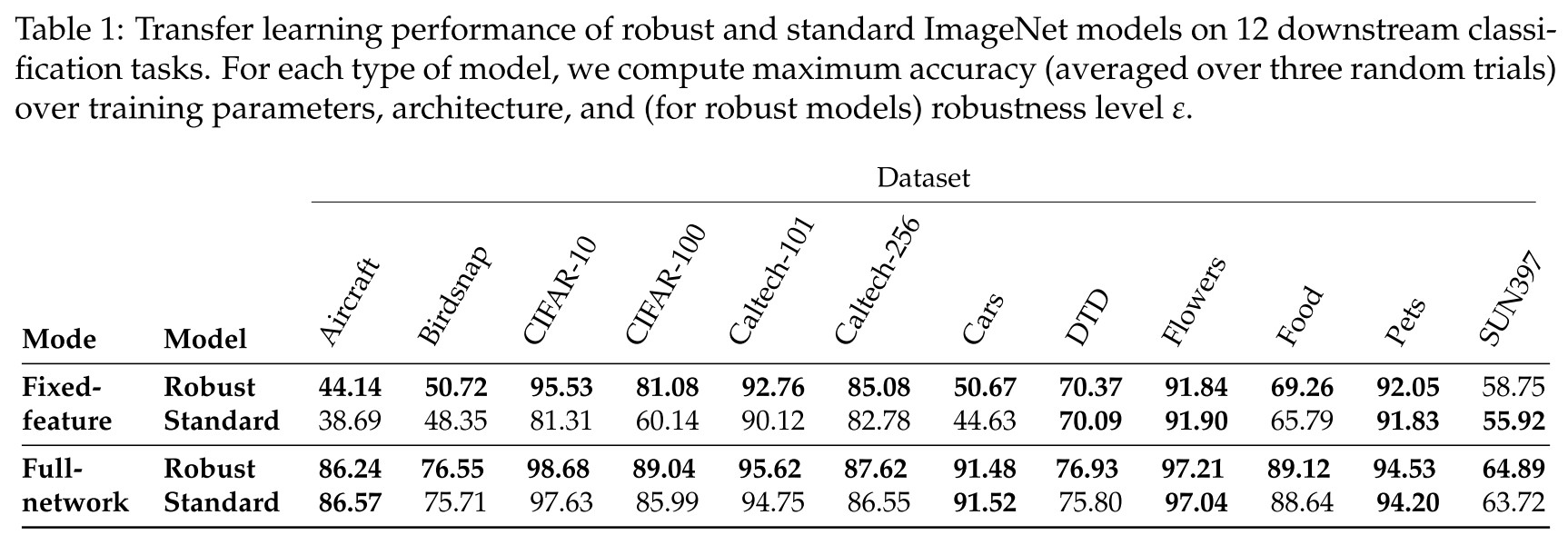
We find that adversarially robust models, while less accurate, often perform better than their standard-trained counterparts when used for transfer learning.
Broadly, transfer learning refers to any machine learning algorithm that leverages information from one (“source”) task to better solve another (“target”) task.
Fixed-Feature Transfer Learning
The fixed-feature transfer learning refers to use the pretrained classifier as a feature extractor, i.e. take the penultimate layer out, and use them to extract features that are linearly separable.
Both conventional wisdom and evidence from prior work [Cha+14; SZ15; KSL19; Hua+17] suggests that accuracy on the source dataset is a strong indicator of performance on downstream tasks.
They propose adversarial robust prior as another indicator to transferability of the learned representations, i.e. the representations learned by model trained with adversarial perturbations
where the latter objective encourages the model to be locally stable in the neighborhood around each data point.
But the adversarially robust models seem less accurate:
In fact, adversarially robust models are known to be significantly less accurate than their standard counterparts.
though showing human-aligned behaviors:

For example, adversarially robust representations typically have better-behaved gradients [Tsi+19; San+19; ZZ19; KCL19] and thus facilitate regularization-free feature visualization [Eng+19a] (cf. Figure 1a). Robust representations are also approximately invertible [Eng+19a], meaning that unlike for standard models [MV15; DB16], an image can be approximately reconstructed directly from its robust representation (cf. Figure 1b).
But they find that robust feature extractor learned by adversarially trained models transfers better:
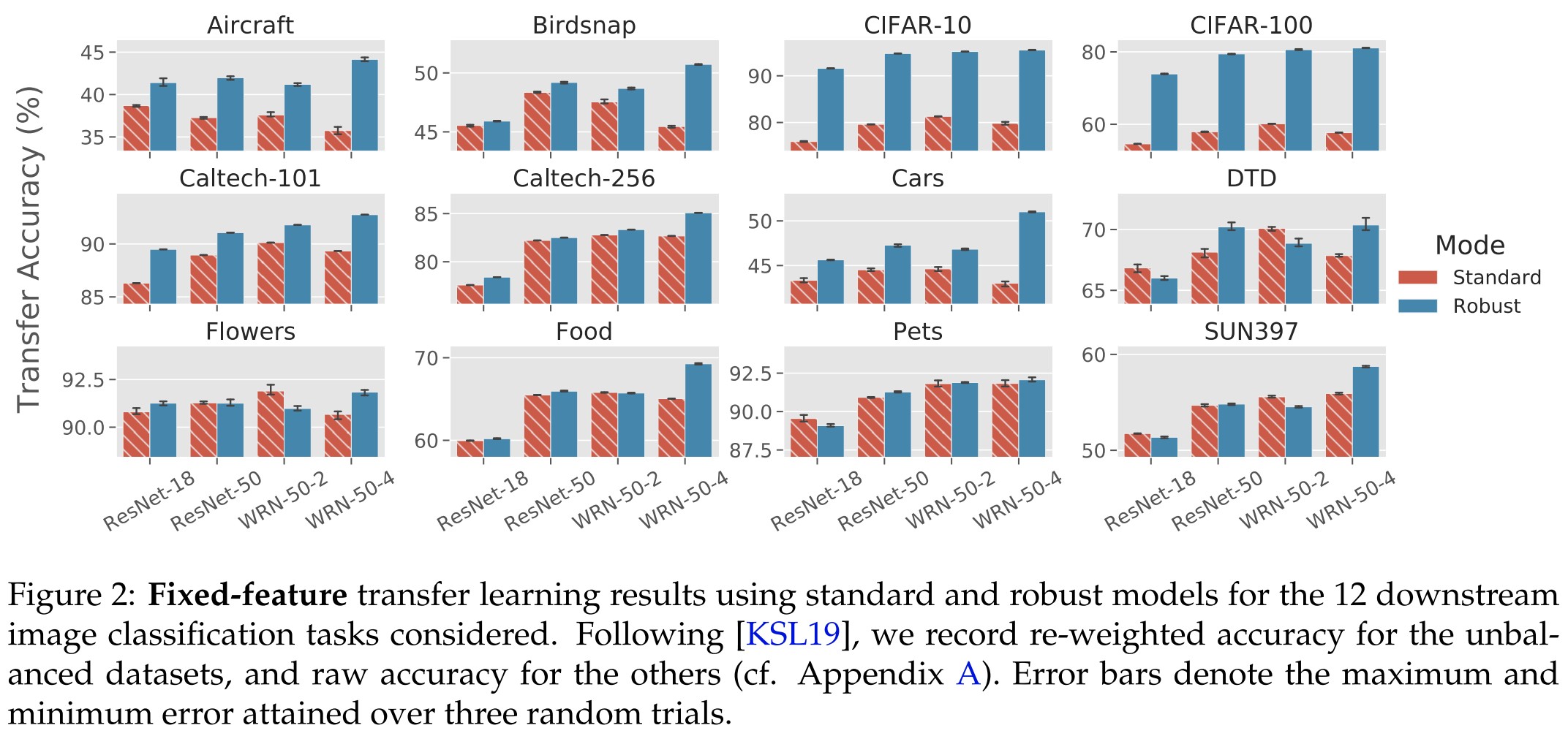
In Figure 2, we compare the downstream transfer accuracy of a standard model to that of the best robust model with the same architecture (grid searching over ε). The results indicate that robust networks consistently extract better features for transfer learning than standard networks—this effect is most pronounced on Aircraft, CIFAR-10, CIFAR-100, Food, SUN397, and Caltech-101
The results are expected.
Full-Network Fine Tuning
A more expensive but often better-performing transfer learning method uses the pre-trained model as a weight initialization rather than as a feature extractor.
Kornblith, Shlens, and Le [KSL19] find that for standard models, performance on full-network transfer learning is highly correlated with performance on fixed-feature transfer learning.
They consider three applications of full-network transfer learning: downstream image classification, object detection and instance segmentation.
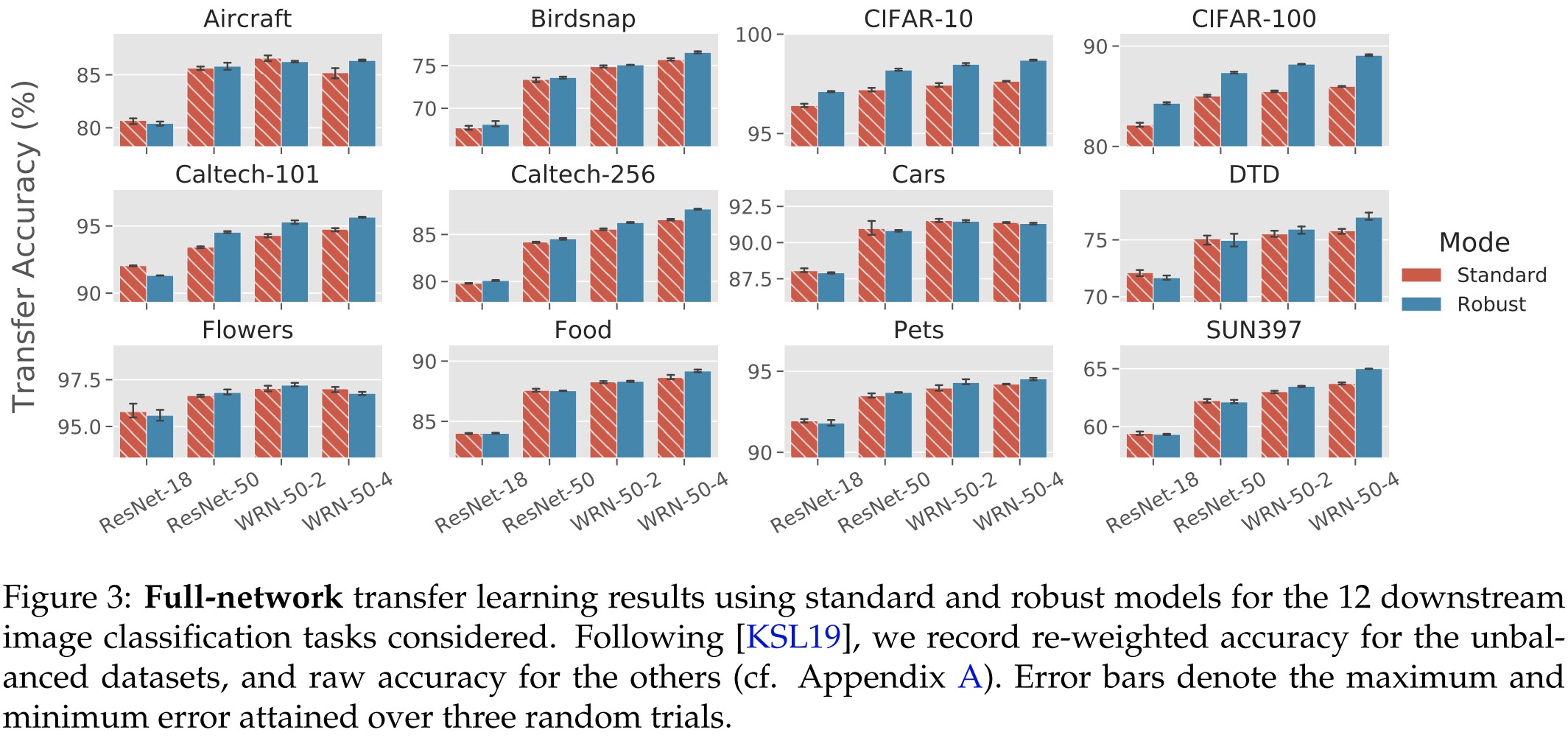
As shown in Figure 3:
Our findings are shown in Figure 3—just as in fixed-feature transfer learning, robust models match or improve on standard models in terms of transfer learning performance.

As shown in Figure 4:
Figure 4 summarizes our findings: the best robust backbone initializations outperform standard models.
The improvement brought by robust models seems marginal compared to the cost of getting a robust model.
ImageNet accuracy and transfer performance
We hypothesize that robustness and accuracy have counteracting yet separate effects: that is, higher accuracy improves transfer learning for a fixed level of robustness, and higher robustness improves transfer learning for a fixed level of accuracy.
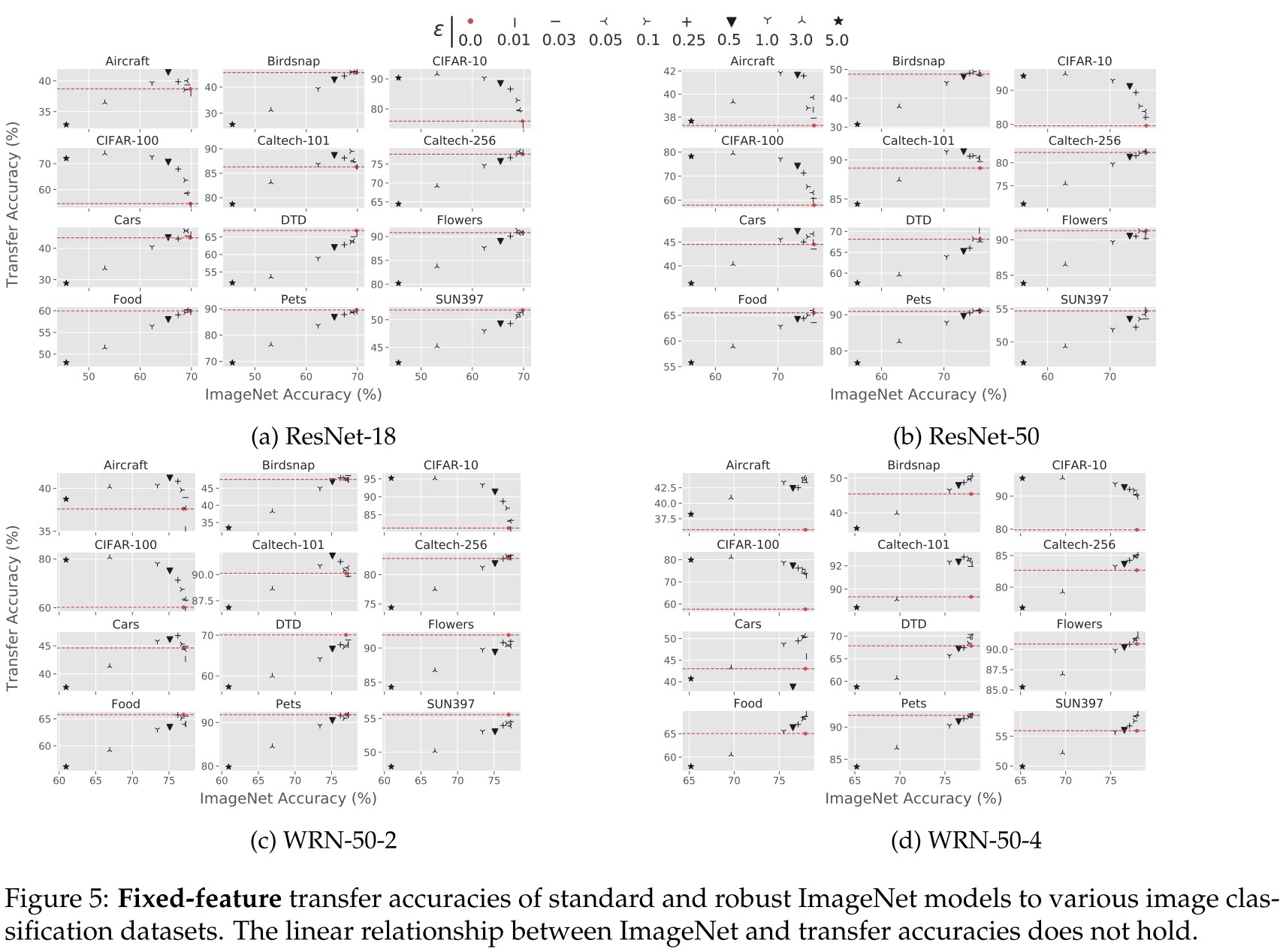
The results (cf. Figure 5; similar results for full-network transfer in Appendix F) support this. Indeed, we find that the previously observed linear relationship between accuracy and transfer performance is often violated once robustness aspect comes into play.
The relationship is surely nonlinear, but it's a little hard to support the hypothesis that for a fixed accuracy, a higher robustness is better.
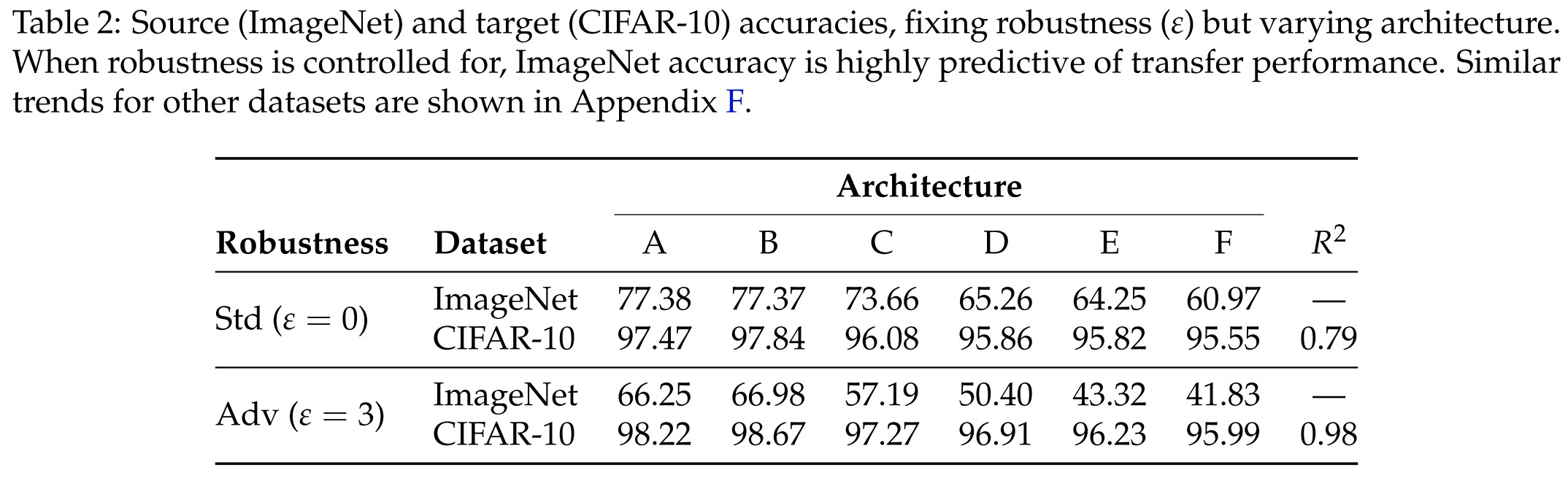
We find that when the robustness level is held fixed, the accuracy transfer correlation observed by prior works for standard models actually holds for robust models too.
Table 2 shows that for these models improving ImageNet accuracy improves transfer performance at around the same rate as (and with higher correlation than) standard models.
Fine, it holds.....
Robust models improve with width
For standard model:
Azizpour et al. [Azi+15], find that although increasing network depth improves transfer performance, increasing width hurts it.
But they find it's not held for robust models.
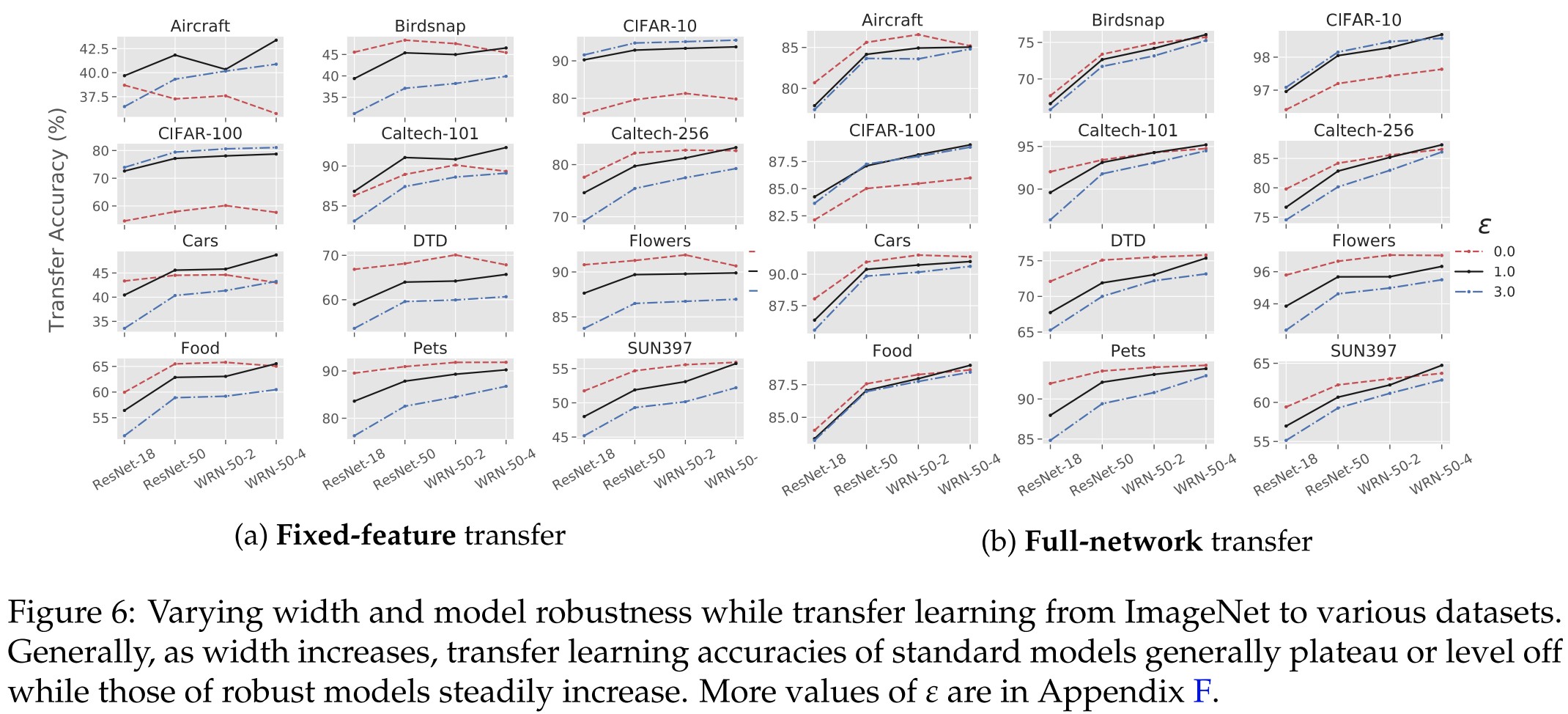
As shown in Figure 6:
As width increases, transfer performance plateaus and decreases for standard models, but continues to steadily grow for robust models.
It indicates that a wider network also has some benefits, perhaps the sole quest for depth in community is biased.
Optimal robustness levels for downstream tasks
The best varies among datasets, to explain and get the optimal robustness level, their hypothesis is:
We hypothesize that on datasets where leveraging finer-grained features are necessary (i.e., where there is less norm-separation between classes in the input space), the most effective values of will be much smaller than for a dataset where leveraging more coarse-grained features suffices.
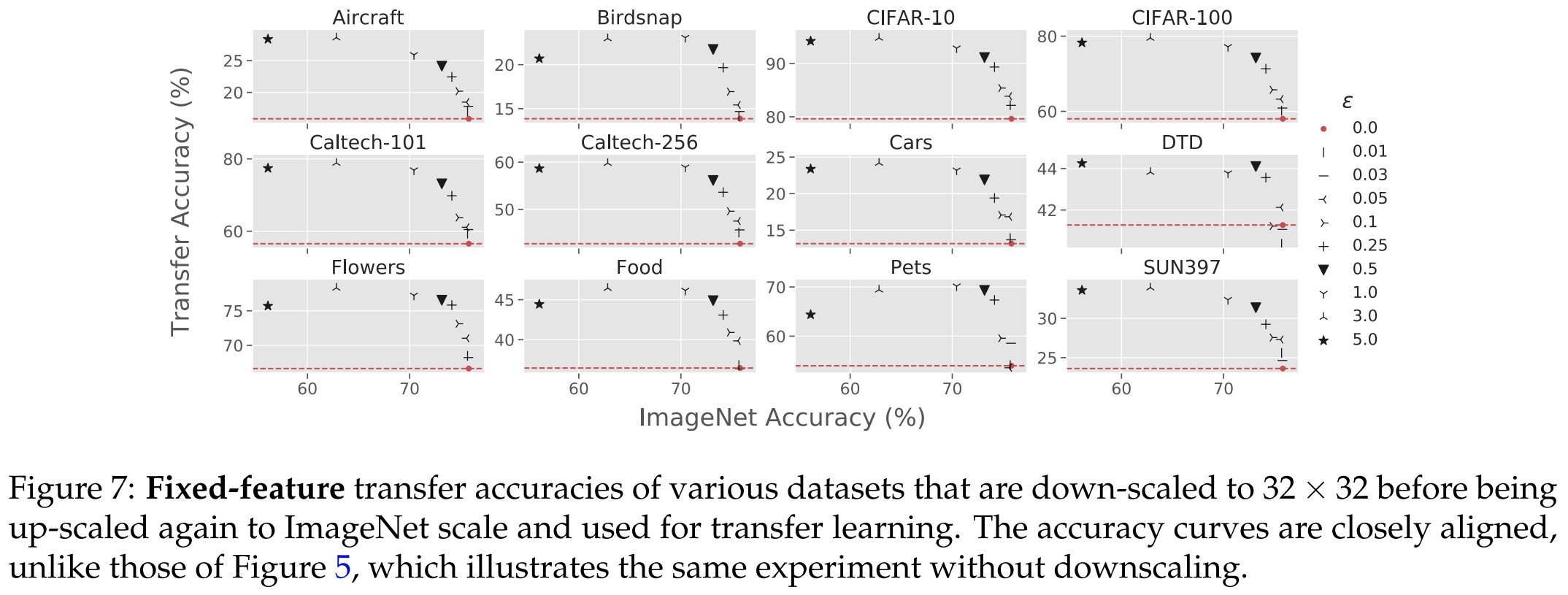
To control the granularity, for which there isn't a metric, they first downsample all images to the size of , and them upsample them to the size of that in ImageNet.
As shown in Figure 7:
After controlling for original dataset dimension, the datasets’ epsilon vs. transfer accuracy curves all behave almost identically to CIFAR-10 and CIFAR-100 ones. Note that while this experimental data supports our hypothesis, we do not take the evidence as an ultimate one and further exploration is needed to reach definitive conclusions.
It now clearly indicates that a higher robustness and a higher accuracy increase the transfer accuracy cooperatively.
Comparing adversarial robustness to texture robustness
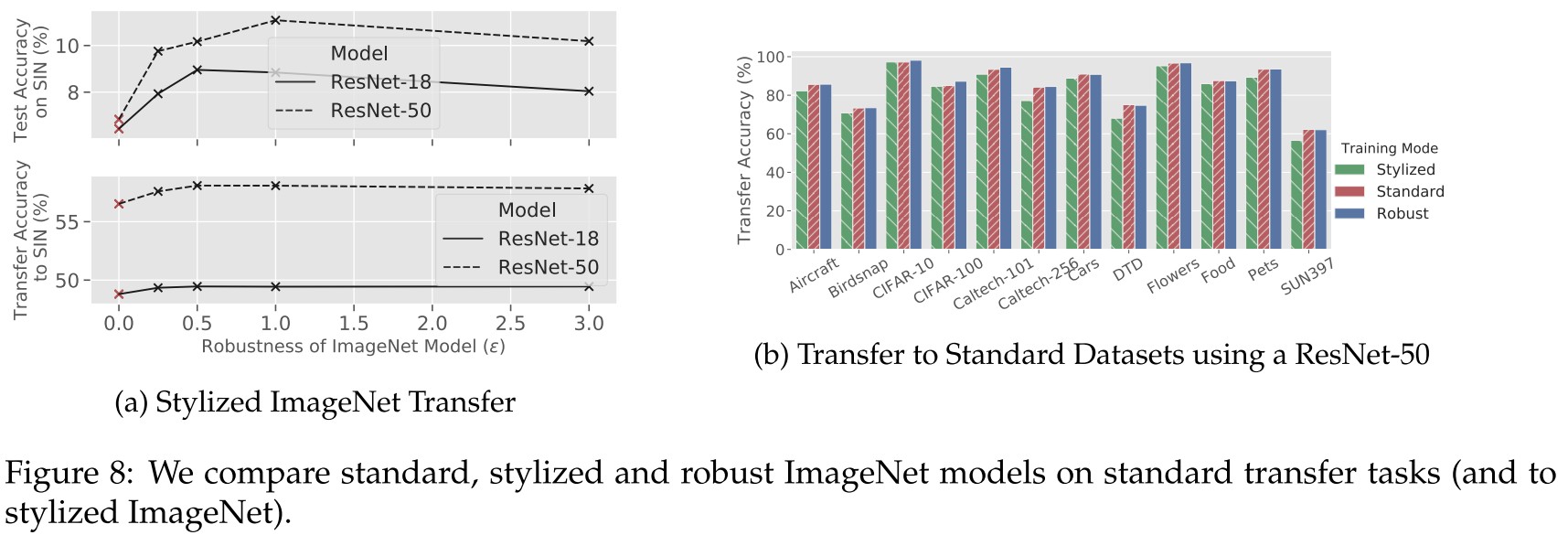
Figure 8b shows that transfer learning from adversarially robust models outperforms transfer learning from texture-invariant models on all considered datasets.
Figure 8a top shows that robust models outperform standard imagenet models when evaluated (top) or fine-tuned (bottom) on Stylized-ImageNet.
It's also expected, since texture invariance is another bias, i.e. texture matters sometimes.
Inspiration
This is a paper demonstrating that with a proper hammer, you can nail all the nails. They show the meaning of a robust model other than robustness.
I think a fast way to get robust model will boost the neural network into a higher level.