Support Vector Machine (SVM)
By LI Haoyang 2020.10.25
This is a short note summarized from Section 2.3, Chapter 2 in the book below
Bennamoun M, Shah SAA, Khan S, Rahmani H. A Guide to Convolutional Neural Networks for Computer Vision. Morgan & Claypool Publishers: Morgan & Claypool Publishers; 2018.
Support Vector Machine (SVM) is designed to find an optimal linear hyperplane to separate the training dataset into two classes, which is achieved by making the margin between the nearest data points to be as large as possible.
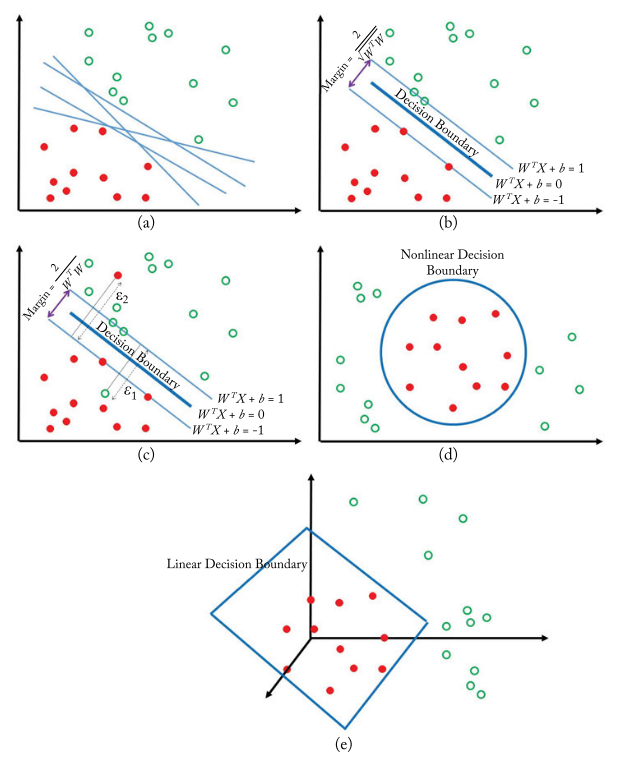
Given a training dataset of two classes, i.e.
The hyperplane separating the data can be written as
Any data points above the hyperplane that suffice should be labeled and those below the hyperplane, i.e. that suffice should be labeled . The nearest data points are divided by two hyperplanes, i.e. and , which have the distance of .
Thus, SVM is learned by solving the following problem
In the case when the data points are not completely separable, using a slack variables can allow some data points to appear on the other side (soft-margin extension)
In the case when the data points are not linearly separable, a projection can be applied to project the data points into a higher-dimensional and linear separable space (nonlinear decison boundary)
In the case when , there will be too many parameters to learn for directly, to avoid which, the Lagrange dual form is used (dual form of SVM)
The derivation of dual form of SVM
For the original problem, the Lagrange function is
By Lagrange duality, the following problem is equal to the original problem
The dual form of SVM is then
The derivativs of with respect to and are
Thus the solution for the inner minimization is
Hence there is the dual form is SVM introduced above.
The calculation of can be intractable since it projects to a higher-dimension, sometimes a very high dimension. Some kernel functions, e.g. linear, polynomial, Gaussian, Radial Basis Function (RBF), are equivalent to , with which, the problem becomes (kernel trick)
Thus the final form of SVM.